《pandas》专题
-
Python Pandas:根据出现的次数删除条目
问题内容: 我正在尝试从数据帧中删除少于100次的条目。数据框如下所示: 现在,我这样计算标记出现的次数: 但是然后我不知道如何删除那些计数低的条目… 问题答案: 编辑:感谢@WesMcKinney显示了这种更直接的方法: 产量
-
 pandas DataFrame行或列的删除方法的实现示例
pandas DataFrame行或列的删除方法的实现示例本文向大家介绍pandas DataFrame行或列的删除方法的实现示例,包括了pandas DataFrame行或列的删除方法的实现示例的使用技巧和注意事项,需要的朋友参考一下 此文我们继续围绕DataFrame介绍相关操作。 平时在用DataFrame时候,删除操作用的不太多,基本是从源DataFrame中筛选数据,组成一个新的DataFrame再继续操作。 1. 删除DataFrame某一列
-
 详解pandas DataFrame的查询方法(loc,iloc,at,iat,ix的用法和区别)
详解pandas DataFrame的查询方法(loc,iloc,at,iat,ix的用法和区别)本文向大家介绍详解pandas DataFrame的查询方法(loc,iloc,at,iat,ix的用法和区别),包括了详解pandas DataFrame的查询方法(loc,iloc,at,iat,ix的用法和区别)的使用技巧和注意事项,需要的朋友参考一下 在操作DataFrame时,肯定会经常用到loc,iloc,at等函数,各个函数看起来差不多,但是还是有很多区别的,我们一起来看下吧。 首先
-
 pandas DataFrame创建方法的方式
pandas DataFrame创建方法的方式本文向大家介绍pandas DataFrame创建方法的方式,包括了pandas DataFrame创建方法的方式的使用技巧和注意事项,需要的朋友参考一下 在pandas里,DataFrame是最经常用的数据结构,这里总结生成和添加数据的方法: ①、把其他格式的数据整理到DataFrame中; ②在已有的DataFrame中插入N列或者N行。 1. 字典类型读取到DataFrame(dict to
-
Pandas实现数据类型转换的一些小技巧汇总
本文向大家介绍Pandas实现数据类型转换的一些小技巧汇总,包括了Pandas实现数据类型转换的一些小技巧汇总的使用技巧和注意事项,需要的朋友参考一下 前言 Pandas是Python当中重要的数据分析工具,利用Pandas进行数据分析时,确保使用正确的数据类型是非常重要的,否则可能会导致一些不可预知的错误发生。 Pandas 的数据类型:数据类型本质上是编程语言用来理解如何存储和操作数据的内部结
-
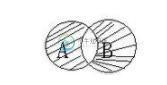 pandas求两个表格不相交的集合方法
pandas求两个表格不相交的集合方法本文向大家介绍pandas求两个表格不相交的集合方法,包括了pandas求两个表格不相交的集合方法的使用技巧和注意事项,需要的朋友参考一下 Hi,好久不见,我还是那颗翻滚的老鼠屎。处理数据时想求两个表格求不相交的部分,或许是对知识的匮乏限制了我的想象力,并未找到直接求的方法,在这里介绍老鼠屎技己使用的方法,希望对读者会有帮助。 阴影部分为所要求的部分(但是前提是A、B两个集合都是无重复内容的集合)
-
Pandas加载CSV的速度比SQL快
问题内容: 从CSV加载数据似乎比从Pandas的SQL(Postgre SQL)加载数据要快。(我有一个固态硬盘) 这是我的测试代码: foo.csv和数据库是相同的(两个列中的数据和列数相同,4列,100000行充满随机int)。 CSV需要0.05秒 SQL花费0.5秒 您认为CSV比SQL快10倍是正常的吗?我想知道我是否在这里错过了什么… 问题答案: 这是正常现象,读取csv文件始终是简
-
Python Pandas:如何仅读取CSV文件的前n行?
问题内容: 我有一个非常大的数据集,我无法读取其中的整个数据集。因此,我正在考虑只读取其中的一个数据块进行训练,但是我不知道该怎么做。任何想法将不胜感激。 问题答案: 如果您只想读取前999,999行(非标题): 如果您只想读取1,000,000 … 1,999,999行 nrows :int,默认值无要读取的文件行数。对读取大文件有用* skiprows :类似于列表或整数的行号,在文件开始处要
-
从(row,col,values)元组列表构造pandas DataFrame
问题内容: 我有一个元组列表,例如 我想将它们放入一个熊猫数据框,其中第一行命名为行,第二列命名为列。看来,处理行名称的方法类似,但如何处理列以获得2x2矩阵(前一组的输出为3x4)?是否还有一种更智能的方式来处理行标签,而不是显式地忽略它们? 编辑 似乎我将需要2个数据框-一个用于平均值,一个用于标准差,对吗?还是可以在每个“单元格”中存储值列表? 问题答案: 您可以在创建后旋转DataFram
-
将Google Spreadsheet CSV导入Pandas数据框
问题内容: 我将文件上传到Google电子表格(以制作带有数据的公共示例IPython Notebook),我使用的本机文件可以读入Pandas Dataframe中。因此,现在我使用以下代码读取电子表格,可以正常工作,但只能以字符串形式输入,而且我没有运气试图将其重新放入数据框(可以获取数据) 数据最终看起来像:(第一行标题) 引入磁盘驻留文件的本机pandas代码如下所示: 一个“干净”的解决
-
如何将列和行的pandas DataFrame子集转换为numpy数组?
问题内容: 我想知道是否有一种更简单,更节省内存的方法来从pandas DataFrame中选择行和列的子集。 例如,给定此数据框: 我只希望其中列’c’的值大于0.5的那些行,但是对于那些行,我只需要列’b’和’e’。 这是我想出的方法-也许有更好的“熊猫”方式? 我的最终目标是将结果转换为numpy数组以传递给sklearn回归算法,因此我将使用上面的代码,如下所示: …这让我很烦,因为我最终
-
使用pandas中具有多个值的列创建虚拟变量
问题内容: 我正在寻找一种处理以下问题的Python方法。 该方法非常适合从数据框的分类列创建虚拟对象。例如,如果列中的值为,则创建2个哑变量并相应地分配0或1。 现在,我需要处理这种情况。称为“标签”的单个列具有类似的值。创建6个假人,但我只想要4个假人,所以一行可以有多个1。 有没有办法以pythonic的方式处理这个问题?我只能想到一些逐步的算法来获取它,但是其中不包括get_dummies
-
如何基于Pandas数据框中的列表对索引行进行重新排序
问题内容: 我有一个看起来像这样的数据框: 它是使用以下代码创建的: 我要做的是根据预定义的列表对行(带有索引)进行排序。结果是: 我该如何实现? 问题答案: 你可以使用预定义的顺序设置指标像 但是,如果按字母顺序排列,则可以使用 如下所示,您需要将其分配给一些变量
-
直接将Pandas数据框转换为稀疏Numpy矩阵
问题内容: 我正在从Pandas数据框创建矩阵,如下所示: 然后使用以下公式生成稀疏矩阵: 从df直线到稀疏矩阵有什么办法吗? 提前致谢。 问题答案: 是一个numpy数组,以这种方式访问值总是比快。 您可能需要先进行移调,例如。在DataFrames中,列为轴0。
-
获取满足条件的Pandas DataFrame行的整数索引?
问题内容: 我有以下DataFrame: 如您所见,列用作索引。我想获取该行的序数,在这种情况下应该是。 被测试的列可以是索引列(在这种情况下也可以)或常规列,例如,我可能想找到满足条件的行的索引。 问题答案: 您可以这样使用np.where: 返回的值是一个数组,因为一列中可能有多个具有特定索引或值的行。