
详解pandas DataFrame的查询方法(loc,iloc,at,iat,ix的用法和区别)

在操作DataFrame时,肯定会经常用到loc,iloc,at等函数,各个函数看起来差不多,但是还是有很多区别的,我们一起来看下吧。
首先,还是列出一个我们用的DataFrame,注意index一列,如下:

接下来,介绍下各个函数的用法:
1、loc函数
愿意看官方文档的,请戳这里,这里一般最权威。
loc函数是基于“标签”选择数据的,但是也可以接受一个boolean的array,对于每个用法,我们从参数方面来一一举例:
1.1 单个label
接受一个“标签”(label)参数,返回一个Series,例如下面这个例子收一个标签,返回通过这个标签定位的行的值,注意这里是通过标签定位,而不是通过中括号中的数字定位第几行,之后我们通过对比iloc函数时还会细说。
test_dict_df.loc[1] #return the row with name 'Bob' test_dict_df.loc[7] #return the row with name 'Time' important!!! # type(test_dict_df.loc[1]) #pandas.core.series.Series
1.2 一个label的array
如果键入一个标签的array,那么就返回一个对应的DataFrame:
test_dict_df.loc[[1,2,4]]
结果如下:
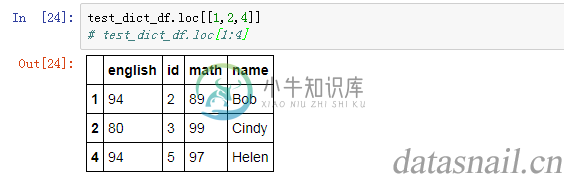
1.3 加入一个切片array
test_dict_df.loc[[1:4]]
结果如下:

1.4 行标签,列标签
通过在中括号中加入行标签和列标签来定位一个cell,相当于坐标的定位:
test_dict_df.loc[1,'english'] #result:94
1.5 行标签或者列标签是切片array
test_dict_df.loc[1:4,'english'] # test_dict_df.loc[1:4,'english':'math']
1.6 还可以接受条件,进行选择
例如我们选择英语成绩超过90的所有行:
test_dict_df.loc[test_dict_df['english']>90]

当然,也可以再条件选择后,再加入列选择,列选择的时候可以单列,也可以是切片数组,通过上面的介绍这里就可以灵活处理:
test_dict_df.loc[test_dict_df['english']>90,'english'] #single label test_dict_df.loc[test_dict_df['english']>90,'english':'name'] #slice array test_dict_df.loc[test_dict_df['english']>90,['english','name']] #label array
1.7 接受一个boolean的array
可以接受一个boolean的array,相当于按照这个表的真假按照位置的顺序选择值
test_dict_df.loc[[True,False,False,True]]
loc还有很多用法,这里先介绍到这里吧,当然如果你的DataFrame是复合的行或者复合列,写法也是不同的,具体就可以查阅官方文档了!
2、iloc函数
官方文档戳这里。
iloc函数与loc函数不同的是,它接受的是一个数字,代表着要选择数据的位置:
test_dict_df.iloc[6]
这代表我们选择的是第6行,而不是index为6的那一行。当然,也可以接受一个boolean的array,相当于按照这个表的真假按照位置的顺序选择值:
test_dict_df.iloc[[True,False,False,True]]
这里iloc也可以接受切片array:
# test_dict_df.iloc[1:2] test_dict_df.iloc[[1,2,4]]
3、ix函数(0.20.0版本后已经弃用)
ix就是一种混合索引,字符串的标签和证书的数据索引都可以作为合法输入,其实相当于loc和iloc的一个混合方法:
test_dict_df.ix['Alice'] test_dict_df.ix[1]
上述两种方法都能得到值,这里我们就不追究这个函数具体是怎样的检索顺序或者工作原理了。因为官方给出的是从pandas0.20.0之后,ix函数已经被弃用。其实在使用的时候,ix函数虽然方便,但是的确有时候会显得比较混乱,所以我们之后也尽量少用这个函数吧,还是按照官方大佬的指导。
4、at函数
at是用来选择单个值的,此时用法类似于loc:
test_dict_df.at[1,'english'] test_dict_df.loc[1,'english']
以上两种方法都能选择到,label为1,列为'english'的那个值,但是据说at速度要快,这点我没有考证过。
5、iat函数
iat函数相对于at函数,就相当于iloc相对于loc函数。iat也只能选择一个值。只不过是用索引位置来选择,注意:行列都是索引位置来选择,从0开始数。
# test_dict_df.iat[1,'english'] #error!!! test_dict_df.iat[2,2] #right!!!
6、概括一下
最后我们概括一下:
1、 loc和iloc函数都是用来选择某行的,iloc与loc的不同是:iloc是按照行索引所在的位置来选取数据,参数只能是整数。而loc是按照索引名称来选取数据,参数类型依索引类型而定;
2、 at和iat函数是只能选择某个位置的值,iat是按照行索引和列索引的位置来选取数据的。而at是按照行索引和列索引来选取数据;
3、 loc和iloc函数的功能包含at和iat函数的功能。
相应的代码连接:github代码
先写到这里,如有新的再补充。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
问题内容: 最近开始从我的安全位置(R)分支到Python,并且对中的单元格定位/选择感到有些困惑。我已经阅读了文档,但仍在努力了解各种本地化/选择选项的实际含义。 我为什么应该使用或超过最一般的选择? 我的理解是,,,和可以提供一些保证正确性是不能提供的,但我也看到了在那里往往是一刀切最快的解决方案。 请说明使用除?以外的任何东西背后的现实世界中的最佳实践推理。 问题答案: loc: 仅适用于索
-
问题内容: 有人可以解释这三种切片方法有何不同吗? 我看过文档,也看过这些 答案,但是我仍然发现自己无法解释这三者之间的区别。在我看来,它们在很大程度上似乎是可互换的,因为它们处于切片的较低级别。 例如,假设我们要获取的前五行。这三者如何运作? 有人可以提出三种用法之间的区别更清楚的情况吗? 问题答案: 注意:在熊猫版本0.20.0及更高版本中,已弃用,建议改为使用loc和iloc。我留下了ix完
-
关于堆栈溢出,有多个问题比较loc、iloc和ix,比如这一个,还有多个问题讨论速度差异,比如这一个。似乎大家的共识是.ix速度更快,但它已被弃用。 这就引出了我的问题,如果. ix更快,尤其是在基于标签的索引中,为什么要弃用它?为什么你不想使用更快的方法?我发现弃用. ix的唯一原因是它混淆了人们,因为它对标签和整数都有效。我是不是漏了什么?或者. ix的唯一缺点是它令人困惑,因此将来可能不支持
-
主要内容:.loc[],.iloc[]在数据分析过程中,很多时候需要从数据表中提取出相应的数据,而这么做的前提是需要先“索引”出这一部分数据。虽然通过 Python 提供的索引操作符 和属性操作符 可以访问 Series 或者 DataFrame 中的数据,但这种方式只适应与少量的数据,为了解决这一问题,Pandas 提供了两种类型的索引方式来实现数据的访问。 本节就来讲解一下,如何在 Pandas 中使用 loc 函数和 iloc
-
本文向大家介绍MyBatis带参查询的方法详解,包括了MyBatis带参查询的方法详解的使用技巧和注意事项,需要的朋友参考一下 #{}占位符 类似于jdbc中通过PreparedStatement进行操作的方式, 会将sql语句中需要参数的位置使用?进行占位,后续由传进来的参数进行参数的绑定。?处绑定的都是值,不能指定表的列,转换成sql时表名会被当成字符串,会出错,防止sql注入。 简单类型参数
-
有人能解释一下这两种切片方法有什么不同吗? 我看过文档,也看到过这些答案,但我还是发现自己无法理解这三种方法有什么不同。在我看来,它们在很大程度上是可以互换的,因为它们处于较低的切片级别。 例如,假设我们希望获得的前五行。这两个是怎么工作的? 谁能说出三种情况,在使用上的区别比较清楚? 从前,我也想知道这两个函数与有什么不同,但是已经从pandas 1.0中删除了,所以我不再关心了。