《pandas》专题
-
将值类型为list的列展平,同时在Pandas中相应地复制另一列的值
问题内容: 亲爱的大熊猫专家: 我正在尝试实现一个函数来展平具有类型为list的元素的数据框的列,我想要该列具有类型为list的元素的数据框的每一行,除要展平的指定列之外的所有列都将是重复,而指定的列将具有列表中的值之一。 以下说明了我的要求: 我觉得可能有一个优雅的解决方案/概念,但是我很挣扎。 这是我的尝试,目前还不行。 认识到alko的帮助,这是我对该解决方案的简单概括,以处理一个数据帧中的
-
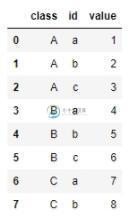 在pandas多重索引multiIndex中选定指定索引的行方法
在pandas多重索引multiIndex中选定指定索引的行方法本文向大家介绍在pandas多重索引multiIndex中选定指定索引的行方法,包括了在pandas多重索引multiIndex中选定指定索引的行方法的使用技巧和注意事项,需要的朋友参考一下 在multiIndex中选定指定索引的行 我们在用pandas类似groupby来使用多重index时,有时想要对多个level中的某个index对应的行进行操作,就需要在dataframe中找到该index
-
对Pandas MultiIndex(多重索引)详解
本文向大家介绍对Pandas MultiIndex(多重索引)详解,包括了对Pandas MultiIndex(多重索引)详解的使用技巧和注意事项,需要的朋友参考一下 创建多重索引 获得索引信息 get_level_values 基本索引 使用reindex对齐数据 数据准备 s序列加(0~-2)索引的值,因为s[:-2]没有最后两个的索引,所以为NaN.s[::2]意思是步长为1. 以上这篇对P
-
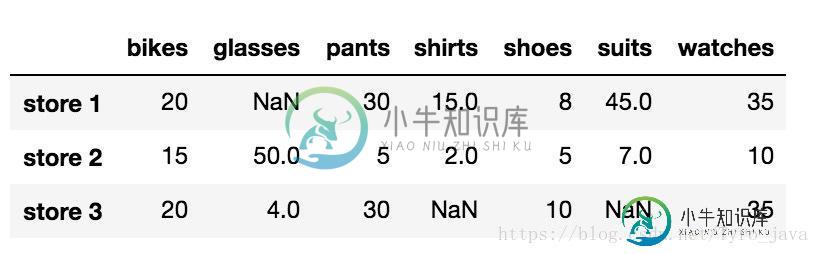 在Pandas中处理NaN值的方法
在Pandas中处理NaN值的方法本文向大家介绍在Pandas中处理NaN值的方法,包括了在Pandas中处理NaN值的方法的使用技巧和注意事项,需要的朋友参考一下 关于NaN值 -在能够使用大型数据集训练学习算法之前,我们通常需要先清理数据, 也就是说,我们需要通过某个方法检测并更正数据中的错误。 - 任何给定数据集可能会出现各种糟糕的数据,例如离群值或不正确的值,但是我们几乎始终会遇到的糟糕数据类型是缺少值。 - Pandas
-
Python:向pandas时间戳添加时间
问题内容: 我将csv文件读入pandas数据框,得到以下信息: 无论是和列有100个元素。我想将Hour的相应元素添加到TDate。 我尝试了以下方法: 但是我得到了错误,因为td似乎没有将array作为参数。如何将的每个元素添加到的相应元素中。 问题答案: 我想你可以添加到列列转换有:
-
获取pandas数据帧的行的索引为整数
问题内容: 例如,假设一个简单的数据框 给定条件,如何检索行的索引值?例如: return ,但是我想得到的只是just 。这在以后的代码中给我带来麻烦。 基于某些条件,我想记录满足该条件的索引,然后在它们之间选择行。 我试过了 获得所需的输出 但我明白了 问题答案: 添加起来更容易-使用一个元素选择list的第一个值: 但是,如果某些值不匹配,则会出现错误,因为第一个值不存在。 解决方案是使用与
-
pandas应用函数返回多个值到pandas数据帧中的行
问题内容: 我有一个带有timeindex和3列的数据帧,其中包含3D矢量的坐标: 我想对也返回向量的每一行应用转换 但是如果我这样做: 我最后得到了一个以元组为元素的熊猫系列。这是因为apply将在不解压的情况下获取myfunc的结果。如何更改myfunc,以便获得具有3列的新df? 编辑: 以下所有解决方案均有效。Series解决方案确实允许使用列名,而List解决方案的执行速度似乎更快。 问
-
pandas:查找给定列的百分位数统计
问题内容: 我有一个pandas数据框my_df,在这里我可以找到给定列的mean(),median(),mode(): 我想知道是否可以找到更详细的统计数据,例如90%?谢谢! 问题答案: 您可以使用pandas.DataFrame.quantile()函数,如下所示。
-
创建两个pandas数据框列的字典的最有效方法是什么?
问题内容: 组织以下pandas数据框的最有效方法是什么: 数据= 变成字典一样? 问题答案: In [9]: pd.Series(df.Letter.values,index=df.Position).to_dict() Out[9]: {1: ‘a’, 2: ‘b’, 3: ‘c’, 4: ‘d’, 5: ‘e’} 速度比较(使用Wouter方法)
-
如何将tsv文件加载到Pandas DataFrame中?
问题内容: 我是python和pandas的新手。我正在尝试将文件加载到熊猫中。 这是我正在尝试的错误,也是我得到的: 问题答案: 注 :由于17.0气馁:使用替代 文档列出了一个.from_csv函数,该函数似乎可以执行您想要的操作: 如果您有标题,则可以传递。
-
估算pandas中类别的缺失值
问题内容: 问题是如何用熊猫数据框中类别列的最频繁级别填充NaN? 在R randomForest软件包中,有 na.roughfix选项: 在熊猫中使用数字变量,我可以用以下内容填充NaN值: 问题答案: 您可以使用一栏中最频繁的值来填充NaN。 如果要用自己的最常用值填充每一列,则可以使用 更新 2018-25-10⬇ 从熊猫开始,包括用于Series和Dataframe的方法。您可以使用它来
-
pandas把所有大于0的数设置为1的方法
本文向大家介绍pandas把所有大于0的数设置为1的方法,包括了pandas把所有大于0的数设置为1的方法的使用技巧和注意事项,需要的朋友参考一下 如下所示: 以上这篇pandas把所有大于0的数设置为1的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。
-
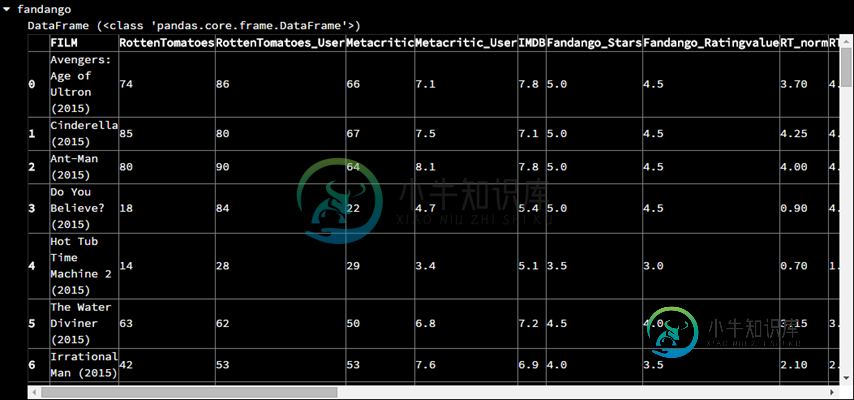 详解Pandas之容易让人混淆的行选择和列选择
详解Pandas之容易让人混淆的行选择和列选择本文向大家介绍详解Pandas之容易让人混淆的行选择和列选择,包括了详解Pandas之容易让人混淆的行选择和列选择的使用技巧和注意事项,需要的朋友参考一下 在刚学Pandas时,行选择和列选择非常容易混淆,在这里进行一下讨论和归纳 本文的数据来源:https://github.com/fivethirtyeight/data/tree/master/fandango 原始的数据如下(截取了一部分)
-
pandas groupby,您将获得一列的最大值和另一列的最小值
问题内容: 我有一个数据框,如下所示: 我想要一个数据框,该数据框具有每个用户num1的最小值和每个用户num2的最大值。 输出应类似于: 我知道,如果我想要两栏的最大值,我可以做: 是否有一些等效方法而不必执行以下操作: 问题答案: 使用+ by ,因此必须按或排序列。最后添加为必要时转换为。 等同于:
-
如何用pythonic方式填充Pandas数据框的丢失记录?
问题内容: 我有一个像这样的熊猫数据框“ df”: 它丢失了一些行,我想像这样填补中间的空白: 有python方式可以做到这一点吗? 问题答案: 您需要构造完整索引,然后使用数据框的方法。像这样 然后,您可以使用该方法将NaN设置为所需的值。 更新(2014年6月) 只是必须自己重新审视一下……在当前版本的熊猫中,有一个函数可以从可迭代的笛卡尔积中构建。因此上述解决方案可能变为: 我认为这很优雅。