
在pandas多重索引multiIndex中选定指定索引的行方法

在multiIndex中选定指定索引的行
我们在用pandas类似groupby来使用多重index时,有时想要对多个level中的某个index对应的行进行操作,就需要在dataframe中找到该index对应的行,在单层index中我们可以方便的使用df.loc[index]来选择,在多重Index中我们可以利用的类似的思路,然而其中也有一些小坑,记录如下。
1 index为有序的
1.1 创建测试数据
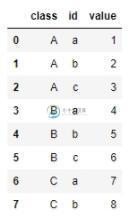
首先创建一个dataframe数据
df = pd.DataFrame({'class':['A','A','A','B','B','B','C','C'],
'id':['a','b','c','a','b','c','a','b'],
'value':[1,2,3,4,5,6,7,8]})
df中内容如下图:
1.2 设置multiIndex
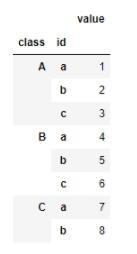
通过set_index设为多重索引
df = df.set_index(['class','id'])
设置索引后效果:
1.3 切片筛选index
这里同样使用loc定位
df.loc[('A',slice(None)),:]
各参数的解释如下:
loc[(a,b),c]中第一个参数元组为索引内容,a为level0索引对应的内容,b为level1索引对应的内容
因为df是一个dataframe,所以要用c来指定列
这里‘A',指选择class中的A类
slice(None), 是Python中的切片操作,这里用来选择任意的id,要注意!不能使用‘:'来指定任意index
‘:',用来指定dataframe任意的列
执行后的结果如下:

同样,如果想只保留id中的'a',则可以使用:
df.loc[(slice(None),'a'),:]
2 index无序
前面的例子对应的index列为数字或字母,是有序的,接下来我们看看index列为中文的情况。
2.1 创建无序测试数据
df2 = pd.DataFrame({'课程':['语文','语文','数学','数学'],'得分':['最高','最低','最高','最低'],'分值':[90,50,100,60]})
df2 = df2.set_index(['课程','得分'])

2.2 尝试切片选择index
df2.loc[('语文',slice(None)),:]
我们进行同样的操作,这时会发现提示出错:
UnsortedIndexError: 'MultiIndex Slicing requires the index to be fully lexsorted tuple len (2), lexsort depth (0)'
这是因为此时的index无法进行排序,在pandas文档中提到:Furthermore if you try to index something that is not fully lexsorted, this can raise:
我们可以通过 df2.index.is_lexsorted()来检查index是否有序,
In[1]: df2.index.is_lexsorted() out[1]: False
接下来,我们尝试对Index进行排序。(排序时要在level里指定index名)
2.3 对index排序后切片选择index
df2 = df2.sort_index(level='课程')
df2.loc[('语文',slice(None)),:]

得到了我们想要的结果。
参考文献:pandas-docs-MultiIndex / Advanced Indexing
以上这篇在pandas多重索引multiIndex中选定指定索引的行方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
本文向大家介绍对Pandas MultiIndex(多重索引)详解,包括了对Pandas MultiIndex(多重索引)详解的使用技巧和注意事项,需要的朋友参考一下 创建多重索引 获得索引信息 get_level_values 基本索引 使用reindex对齐数据 数据准备 s序列加(0~-2)索引的值,因为s[:-2]没有最后两个的索引,所以为NaN.s[::2]意思是步长为1. 以上这篇对P
-
如果我定义一个像这样的分层索引数据框: 内容如下所示: 我知道如何提取与给定列对应的数据。例如。对于列: 如何提取符合以下标准集的数据: , , , column , , 列 和 、、列、以及从开始的所有列 是偶数 (顺便说一句,我做了不止一次rtfm,但我真的觉得难以理解。)
-
基于单个值/标签的切片 基于一个或多个级别的多个标签的切片 布尔条件和表达式的过滤 哪些方法适用于什么情况 为简单起见的假设: 输入数据表没有重复的索引键 下面的输入数据只有两个级别。(此处所示的大多数解决方案都概括为N个级别) 问题2b 我如何获得级别“二”中对应于“t”和“w”的所有值? 如何从检索横截面,即具有索引特定值的单行?具体来说,如何检索的横截面,由 如何选择与和相对应的两行?
-
问题内容: 我正在尝试重新索引熊猫对象,像这样, 我正在如下所示进行操作,并且得到了错误的答案。有关如何执行此操作的任何线索? 知道为什么会这样吗? 问题答案: 为什么不简单地使用方法?
-
问题内容: 我有以下pd.DataFrame: 它具有带有和层次结构级别的MultiIndex列。该标签从0到n,并为每个标签,有两个和列。 我想子选择此DataFrame的所有(或)列。 问题答案: 有一种方法可以与布尔索引一起使用,以获得预期的结果。
-
我目前正在重构一个用Symfony 3编写的应用程序,并且严重依赖ORM,我一直在尝试获取一个包含所选列索引的对象/数组。 现在我对PHP PDO相当熟悉,我记得查询结果的基本获取如下所示 (根据我的查询)它会给我一个类似于下面的数组 在理论方面,我尝试使用几个具有水合参数的内置函数 运气不好,我最后得到了这样的东西 有人能帮我或者给我指出正确的方向吗?如何正确地解决这个问题? ----更新了问题