《pandas》专题
-
解决pandas中读取中文名称的csv文件报错的问题
本文向大家介绍解决pandas中读取中文名称的csv文件报错的问题,包括了解决pandas中读取中文名称的csv文件报错的问题的使用技巧和注意事项,需要的朋友参考一下 之前在使用Pandas处理csv文件时,发现如果文件名为中文,则会报错: 后来在一位博主的博客中解释了是read_csv中engine参数的问题,默认是C engine,在读取中文标题时有可能会出错(在我这是必现),解决方法是将en
-
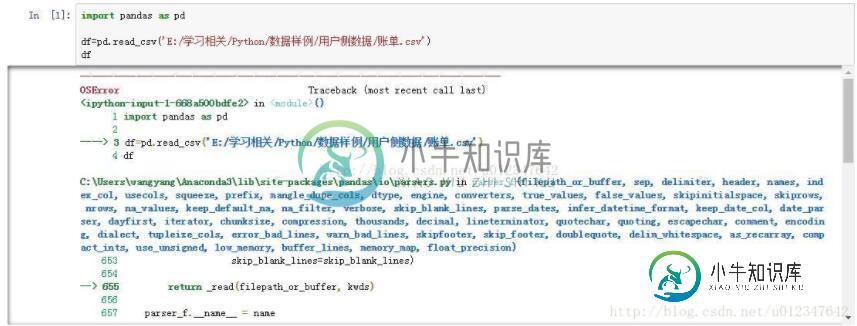 利用Pandas读取文件路径或文件名称包含中文的csv文件方法
利用Pandas读取文件路径或文件名称包含中文的csv文件方法本文向大家介绍利用Pandas读取文件路径或文件名称包含中文的csv文件方法,包括了利用Pandas读取文件路径或文件名称包含中文的csv文件方法的使用技巧和注意事项,需要的朋友参考一下 利用Pandas的read_csv函数导入数据文件时,若文件路径或文件名包含中文,会报错,无法导入: 解决方法如下: 以上这篇利用Pandas读取文件路径或文件名称包含中文的csv文件方法就是小编分享给大家的全部
-
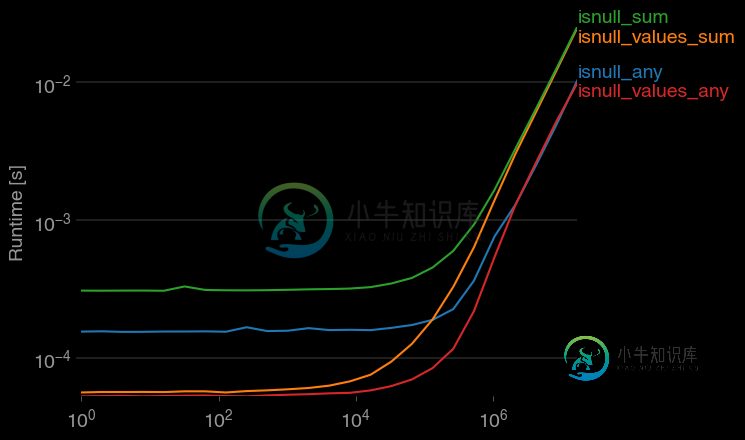 如何检查Pandas DataFrame中的值是否为NaN
如何检查Pandas DataFrame中的值是否为NaN问题内容: 在Python Pandas中,检查DataFrame是否具有一个(或多个)NaN值的最佳方法是什么? 我知道函数,但是这会为每个元素返回一个布尔值的DataFrame。此处的帖子也无法完全回答我的问题。 问题答案: jwilner的反应是现场的。我一直在探索是否有更快的选择,因为根据我的经验,求平面数组的总和(奇怪)比计数快。这段代码似乎更快: 速度稍慢,但当然还有其他信息-的数量。
-
将局部变量与pandas eval函数配合使用
问题内容: 熊猫帮助文件说(用于eval): 为方便起见,可以使用多行字符串来执行多个分配。 但是,我发现这不适用于变量(使用ipython): 这有效: 但这不起作用(op,cl,hi,lo是数据帧df_price中的cols,其中mult是一个浮点数): 错误: pandas.computation.ops.UndefinedVariableError : 未定义局部变量“ mult” 问题答
-
带有和不带有括号的python pandas函数
问题内容: 我注意到,如果使用许多不带括号的DataFrame函数,其行为似乎类似于“属性”,例如 这是如何完成的,是一种好的做法?这是Linux上的熊猫0.15.1 问题答案: 它们是不同的,因此不建议使用,它们清楚地表明这是一种方法并且恰好输出结果,而另一种则表明了预期的输出。 这就是为什么您不应该这样做的原因: 所以好吧,您没有使用括号正确地调用该方法并看到显示为有效的输出,但是如果您引用了
-
Pandas DataFrame按时间戳分组
问题内容: 我有一个用例,其中: 数据的格式为:Col1,Col2,Col3和时间戳。 现在,我只想获取行数与时间戳箱的数量。 也就是说,对于每半小时的存储桶(甚至没有对应行的存储桶),我需要计算有多少行。 时间戳记分布在一年内,因此我无法将其划分为24个存储桶。 我必须每隔30分钟将它们装箱。 问题答案: 通过
-
pandas df.corr()返回NaN,尽管数据已填充
问题内容: 我的数据如下所示: 当我尝试打电话时,我会全部收回。我在excel中进行了测试,确实可以计算出相关性。 知道为什么会这样吗? 我很乐意发布更多信息,但不确定会有所帮助。 问题答案: 杰森(Jason),使用示例数据对我来说很好用。 我在您的data.info()中注意到dtype上贴有’None’。当我加载样本数据时,我得到 我想象是什么原因导致“无”导致您的问题。 希望这可以帮助[希
-
如何使用pandas groupby函数将函数应用于numpy数组
问题内容: 我对熊猫还很陌生,所以我希望这将是一个简单的答案(我也感谢所有指向数据框设置的指针) 假设我有以下DataFrame: 现在,我想按“ gp”分组并获取“ vector”的均值 我试过了 乃至 但我收到一个错误,没有要聚合的“数字类型”。那么np.arrays在熊猫中不起作用吗? 问题答案: 对我来说,它有效: 我取两次平均值,因为您想要向量均值的均值组值(不是吗?)。 如果要使用均值
-
pandas:文件格式和文件名中带有重音/特殊字符的oserror
问题内容: 我试图用来从一些.csv文件中获取数据。只要文件名或文件路径中没有重音(例如ä,é,ü),此方法就可以正常工作。当我使用诸如这样的文件名时,出现以下错误:。我的代码是: 我正在使用pandas 0.20.1和python 3.6.0。我发现这在以前的版本中是一个问题,但我认为它已解决。有想法该怎么解决这个吗?我也发现了这个:https : //github.com/pandas- de
-
如何在Pandas中迭代数据帧并删除空行?[副本]
数据帧: 我有一段代码逐列遍历数据帧: 我需要删除它是NaN的行。我该怎么做?我已经尝试了. isnull()和. Notnull(),但它们返回错误
-
Python Pandas:拆分列并在当前[重复]旁边添加新列
我有一个类似于此的excel工作表,但有很多列: 我想将团队列拆分为团队和一个名为Team ID的新列。我目前使用以下代码执行此操作: 这很好(请注意,团队名称可以包括数字、空格和paranthesis)。虽然这可能并不完美,但我完成了这项工作。 我的问题是新列“Team ID”放置在数据集的末尾。所以它将是“Team-成员-Team ID”。虽然3列不是问题,但有时有10列需要拆分7列。 所以问
-
Pandas Dataframe:如何将一列拆分为多个热编码列[duplicate]
我有一个这样的文本文件: 输入文件中的最后一个字段的长度为50k个字符,并且只有0、1或2个字符。我想要最后一个字段的一个热编码版本。因此,我的预期结果是这样的数据帧: 我通过读取输入文件创建了一个初始数据帧: 这将创建一个包含3列的数据帧: 我想我也许可以使用下面的东西创建初始的单独列,然后使用熊猫get_dummies函数进行一次热编码,但是我无法创建单独的列。我已经试过了 但这并不是把角色分
-
在pandas for python中创建虚拟变量
我试图在python中使用pandas从一个分类变量创建一系列伪变量。我遇到了函数,但每当我尝试调用它时,都会收到一个错误,即名称未定义。 任何创建虚拟变量的想法或其他方法都将受到欢迎。 编辑:由于其他人似乎遇到了这种情况,熊猫中的功能现在运行得非常好。这意味着以下各项应起作用: 看见http://blog.yhathq.com/posts/logistic-regression-and-pyth
-
FileNotFoundError:[Errno 2]将excel文件导入到pandas[duplicate]时
我得到一个FileNotFoundError:[Errno 2]没有这样的文件或目录:'census_data.xlsx'导入excel文件到熊猫。我仔细检查了我的文件是否正确,但我仍然得到这个错误。 这是我的密码:
-
Pandas在groupby之后获取所有行的最小值和最大值
我有一个这样的数据帧: 必修的: 相关链接:pandas groupby的最小和最大行 pandas groupby中两个系列的最大值和最小值 pandas groupby中的最大和最小日期 单击groupby,然后按列的值(例如,最小值、最大值)选择一行