《pandas》专题
-
在Pandas[复制]中从筛选结果创建bool掩码
我知道如何创建一个掩码来过滤数据帧时,查询一个单一的列: 我在这里使用一个简单的面具: 我的问题是如何创建具有多列的掩码?因此,如果我这样做: 这就像我期望的那样过滤,但是如何根据我的另一个例子从中创建布尔掩码呢?我已经为此提供了测试数据,但我经常想在其他类型的数据上创建一个掩码,所以我正在寻找任何指针。
-
使用NaN以外的填充值初始化Pandas DataFrame
假设我初始化一个空数据帧如下: 生成的具有以下形式 有没有一种pythonic方法可以将s替换为其他值,例如?当然,一种方法是简单地将其指定为数据: 也许有更简洁的方法?
-
如何用Pandas中数据帧的两个参数应用lambda的结果生成返回列的数据帧
我有一个包含3列a、b和c的数据框,还有一个接受3个参数的函数,例如一个小示例: 对于每一行,我希望应用函数并在新的数据帧中返回值a、b、c、x、y、z 我做到了: 它正在返回: 如何获得如下结果,而不是每一行的数组:
-
pandas dataframe列具有带逗号的字符串如何将其转换为列表[已关闭]
数据帧中的列具有值,。我想制作这样的数组:
-
在pandas中创建新列。使用apply()函数的DataFrame
我有一个数据框,如: 我需要为每个列应用一些函数,并在这个数据帧中创建具有特殊名称的新列。 所以我需要根据列和(如name)乘以两个额外的列,名称为和由两个。是否可以使用或其他结构来完成此操作?
-
从Pandas[duplicate]中前两列上的函数创建第三列
我有一个功能: 以及数据帧: 我想将每行的组和名称输入到我的“lookup”函数中,并将该行的答案作为第三列中的单元格返回:“value” 我已经看了这个和这个问题。但他们不完全是我在做的。 我也研究过这个问题。这就是我正在做的。但对我来说也没有成功。 我试过这个: 和这个: 但它只会使值列全部为“NULL” 这里的任何建议都非常感谢。
-
Pandas:在数据帧中创建两个新列,其中的值是从预先存在的列计算出来的
我正在使用熊猫库,我想添加两个新列到一个数据框有n列(n 要应用的函数类似于: 为仅返回值的函数创建新列的一种方法是: 所以,我想要的,但尝试失败(*),是这样的: 实现这一目标的最佳方式是什么?我毫无头绪地浏览了文件。 **返回一个熊猫系列每个项目由一个元组z, y组成。试图将其分配给两个数据框列会产生一个ValueError。**
-
Pandas dataframe:创建一个新列,该列是使用其他两列的自定义函数
考虑下面的数据集存储在熊猫数据文件<代码> DFX < /代码>: 我有一个函数是: 现在,我想在中创建一个新列,其中包含计算出的z值 查看其他SO示例,我尝试了几个变体,包括: 返回错误。正确的方法是什么?
-
如何从pandas中的多个列计算多个列
我正在尝试使用一个函数从pandas数据帧中的多个列计算多个列。该函数接受三个参数-a-、-b-和-c-,并返回三个计算值-sum-、-prod-和-quot-。在我的pandas数据框架中,我有三个列-a-、-b-和-c-我想从中计算列-sum-、-prod-和-quot-。 我所做的映射只有在正好有三行时才起作用。我不知道出了什么问题,尽管我认为这与选择正确的轴有关。有人能解释一下发生了什么,
-
获取Pandas中每个分区的每列平均值[重复]
我试图为数据帧(如以下数据帧)获取每个分区每列的平均值: 也就是说,我想得到和的平均值,并将它们聚合成和的唯一组合。因此,生成的DataFrame应该是: 其中,我国城市分区的重复行已聚合为一行,具有平均值。 我研究了等等问题
-
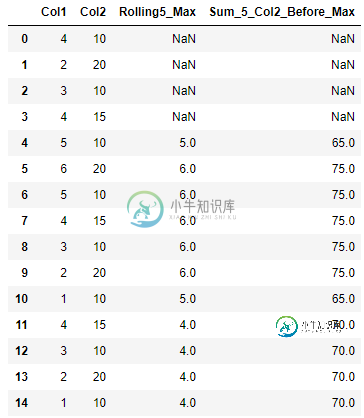 Pandas:在滚动窗口中查找max,并返回max行和继续四行的另一列的总和
Pandas:在滚动窗口中查找max,并返回max行和继续四行的另一列的总和我有一个有两列的数据框。我想找到第一列的滚动5周期最大值,并计算滚动最大值行和前4行的值和第二列的总和。 下面是上面提到的Col1和Col2的期望输出的例子,滚动最大值的第三列和计算的期望结果的最后一列 下面是设置前三列的代码: 以下是所需输出的示例:
-
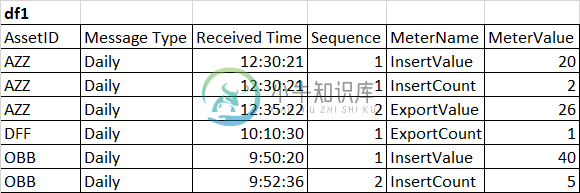 如何使用Pandas将一列中的值转换为列?[副本]
如何使用Pandas将一列中的值转换为列?[副本]大家好,我有一个数据集,看起来像下面的df1,我想让它看起来像使用熊猫的df2。我曾经尝试过使用枢轴和转置,但我不知道该怎么做。谢谢你的帮助!
-
Pandas-合并行并添加带有get_dummies的列
使用以下数据帧: 我想获得 我分别尝试了和 但我不知道如何将两者结合起来,或者是否有其他方法。
-
将数据从sqlalchemy移动到pandas DataFrame
我正试着在一个熊猫数据目录中加载一个SQLAlchemy。 当我尝试: 我得到一个属性错误: 和 上一个问题SQLAlchemy ORM到pandas DataFrame的转换解决了我的问题,但是解决方案:使用不是我的解决方案。我使用db.session.add()和db.session.commit()打开/关闭会话,但是当我使用时,就会得到一个属性错误:
-
SQLAlchemy ORM到pandas数据表的转换
是否有解决方案将SQLAlchemy转换为pandas Dataframe? null ,其中是我的模型类,是列表)。这相当于SQL。 有什么可能吗?