《pandas》专题
-
PYODBC到pandas-dataframe不工作-传递值的形状为(x,y),索引表示(w,z)
我以前在python中使用pyodbc,但现在我已经在一台新机器上安装了它(win 8 64位、python 2.7 64位、PythonXY和Spyder)。 我不知道为什么行为会改变。也许是我的Pandas版本,或者是pyodbc,但是更新是有问题的。我试图更新一些模块,但它搞砸了一切,我使用的任何方法(二进制文件--用于正确的机器/安装--PIP安装、easy-install,任何东西!等等
-
为什么在使用pandas read_gbq时出现错误“禁止:403访问被拒绝:BigQuery BigQuery:全局文件模式时权限被拒绝”
我正在尝试使用python来读取BigQuery中的视图。我以前使用过0.14版。gbq的0,并通过执行以下操作使用服务帐户进行身份验证: 其中路径_到_JSON、BQ_视图和项目_ID已填入相关信息。这样做没有任何问题。不过,我现在正在处理另一个使用0.15版的项目。gbq的0,其中已被弃用,并已替换为。按照有关如何使用服务帐户的new credentials参数进行身份验证的指南,我尝试了以下
-
ImportError:没有名为“ pandas.indexes”的模块
问题内容: 导入pandas并没有引发错误,而是尝试像这样读取选取的pandas数据框: 追溯为165行,并发三个并发异常(无论如何)。是不是熊猫版17.1我跑兼容?如何释放数据框以供使用? 以下是回溯副本: 我还尝试了直接从pickle加载pickle文件: 并得到相同的错误: 问题答案: 当我使用python 2.7创建pkl文件并尝试使用python 3.6读取它时,出现了此错误: 而且有效
-
python,用pandas排序降序数据框
问题内容: 我正在尝试通过降序对数据框进行排序。我在升序参数中输入了“ False”,但我的命令仍然在升序。 我的代码是: 但输出是 问题答案: 编辑:这已经过时,请参阅@Merlin的答案。 是非空 列表 ,与。您应该写:
-
为什么在Alpine Linux上安装Pandas会花费很多时间
问题内容: 我注意到,使用基本操作系统Alpine与CentOS或Debian在Docker容器中安装Pandas和Numpy(它的依赖项)需要花费更长的时间。我在下面创建了一个小测试来演示时差。除了Alpine用来更新和下载构建依赖项以安装Pandas和Numpy的几秒钟之外,为什么setup.py所需的时间比Debian的安装要多70倍? 是否有任何方法可以使用Alpine作为基础映像来加快安
-
 python+pandas分析nginx日志的实例
python+pandas分析nginx日志的实例本文向大家介绍python+pandas分析nginx日志的实例,包括了python+pandas分析nginx日志的实例的使用技巧和注意事项,需要的朋友参考一下 需求 通过分析nginx访问日志,获取每个接口响应时间最大值、最小值、平均值及访问量。 实现原理 将nginx日志uriuriupstream_response_time字段存放到pandas的dataframe中,然后通过分组、数据统
-
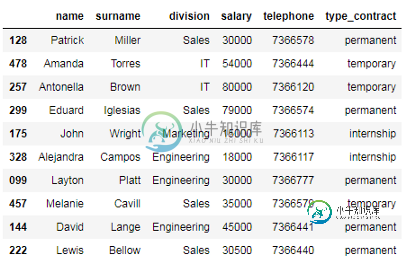 Pandas的数据过滤实现
Pandas的数据过滤实现本文向大家介绍Pandas的数据过滤实现,包括了Pandas的数据过滤实现的使用技巧和注意事项,需要的朋友参考一下 作者|Amanda Iglesias Moreno 编译|VK 来源|Towards Datas Science 从数据帧中过滤数据是清理数据时最常见的操作之一。Pandas提供了一系列根据行和列的位置和标签选择数据的方法。此外,Pandas还允许你根据列类型获取数据子集,并使用布尔
-
 pandas针对excel处理的实现
pandas针对excel处理的实现本文向大家介绍pandas针对excel处理的实现,包括了pandas针对excel处理的实现的使用技巧和注意事项,需要的朋友参考一下 本文主要介绍了pandas针对excel处理的实现,分享给大家,具体如下: 读取文件 数值处理 获取数据 loc和iloc详解 多行 输出行号和列号 获取指定值 基本格式化 数据多表合并 到此这篇关于pandas针对excel处理的实现的文章就介绍到这了,更多相关
-
pandas 分块阅读
本文向大家介绍pandas 分块阅读,包括了pandas 分块阅读的使用技巧和注意事项,需要的朋友参考一下 示例
-
 深入浅析python的第三方库pandas
深入浅析python的第三方库pandas本文向大家介绍深入浅析python的第三方库pandas,包括了深入浅析python的第三方库pandas的使用技巧和注意事项,需要的朋友参考一下 pandas模块 pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。 作为pandas系列的最终章,本文引出一个数据“复制”问题。 示例如下: 从上图中可以
-
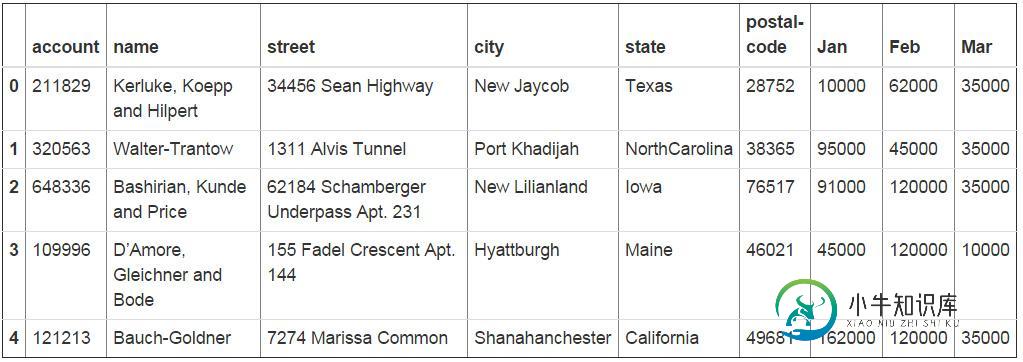 用Python的pandas框架操作Excel文件中的数据教程
用Python的pandas框架操作Excel文件中的数据教程本文向大家介绍用Python的pandas框架操作Excel文件中的数据教程,包括了用Python的pandas框架操作Excel文件中的数据教程的使用技巧和注意事项,需要的朋友参考一下 引言 本文的目的,是向您展示如何使用pandas 来执行一些常见的Excel任务。有些例子比较琐碎,但我觉得展示这些简单的东西与那些你可以在其他地方找到的复杂功能同等重要。作为额外的福利,我将会进行一些模糊字符串
-
在Pandas DataFrame的字符串中漂亮地打印换行符
问题内容: 我有一个Pandas DataFrame,其中的一列中包含字符串元素,而这些字符串元素包含我想实际打印的新行。但是它们只是出现在输出中。 也就是说,我要打印此: 但这就是我得到的: 我该如何完成我想要的?我可以使用DataFrame,还是必须恢复为手动打印填充的列一次一次? 这是我到目前为止的内容: 问题答案: 从pandas.DataFrame文档中: 具有标注轴(行和列)的二维大小
-
如何将pandas DataFrame升级到Microsoft SQL Server表?
问题内容: 我想将我的pandas DataFrame插入到SQL Server表中。这个问题为PostgreSQL提供了一个可行的解决方案,但T- SQL没有的变体。如何为SQL Server完成同一件事? 问题答案: 有两种选择: 使用语句代替。 使用带a的语句,后跟条件语句。 MERGE的T-SQL文档说: 性能提示:当两个表具有匹配特征的复杂混合时,为MERGE语句描述的条件行为最有效。例
-
基于值而不是计数的带有窗口的pandas滚动计算
问题内容: 我正在寻找一种类似的各种功能的方法,但我希望滚动计算的窗口由一个值范围(例如,DataFrame列的值范围)定义,而不是由窗口中的行数。 例如,假设我有以下数据: 如果执行类似的操作,则会得到一个滚动总和,其中每个窗口包含5行。但是我想要的是一个滚动总和,其中每个窗口都包含的一定范围的值。也就是说,我希望能够执行类似的操作,并得到一个结果,其中第一个窗口包含所有介于1和5之间的行,然后
-
pandas滚动值
问题内容: 如何获得pandas系列值的某个长度n的滚动值? 例如,如果我有以下内容: 我如何获得长度为n的移动值,即类似,如果n = 3: [NaN,NaN,0],[NaN,0,1],…,[4,8.8,7.12] 编辑:如果我使用熊猫滚动,如: 然后滚动是该系列的移动平均线。在这里,我不希望每个移动的3个值集合的平均值,而是这些3个值的集合。 问题答案: 我认为您需要先添加s,然后再执行以下解决