《pandas》专题
-
Python Pandas Dataframe基于包含字符[重复]的列删除行
我有一个数据框和大多数列'arr'有一个日期正确格式化为 几张坏唱片都有问题 比如2019/02/10,我想放弃它们。 我试过这个: 但我收到一条错误信息: 我的方向对吗?
-
根据pandas/matplotlib中的类绘制直方图
有没有一种惯用的方法来绘制两个类的特征直方图?在熊猫方面,我基本上想要 在同一个情节中。我可以 但这给了我两个不同的情节。 这似乎是一项常见的任务,因此我认为有一种惯用的方法来完成这项任务。当然,我可以手动操作柱状图,使其彼此相邻,但熊猫通常都能很好地做到这一点。 基本上,我希望将这个matplotlib示例放在一行熊猫中:http://matplotlib.org/examples/pylab_
-
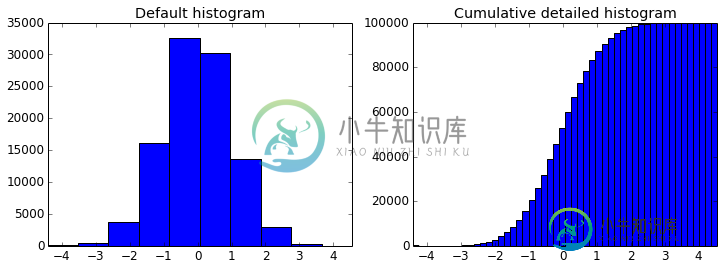 Matplotlib/Pandas直方图对齐不正确
Matplotlib/Pandas直方图对齐不正确这是来自[41]中的ipython笔记本 直方图条似乎没有正确地与网格对齐(见第一个子图)。这也是我在自己的作品中面临的问题。 有人能解释一下原因吗?
-
Python Pandas-读取包含多个表的csv文件
我有一个文件。 使用Pandas,从这个文件中获得两个DataFrame和的最佳策略是什么? 输入如下所示: 到目前为止,我想到的最好的方法是转换这个文件转换为Excel工作簿(),将表格拆分为工作表并使用: 然而: 这种方法需要模块。 这些日志文件必须被实时分析,这样就可以更好地找到一种方法来分析它们,因为它们来自日志。 真正的日志比那两个有更多的表。
-
Pandas error:ValueError:序列的真值不明确。关于将函数应用于数据帧
我有一个数据帧,在对其应用函数时给出值错误。 ValueError:序列的真值不明确。使用a.empty、a.bool()、a.item()、a.any()或a.all()。
-
为什么pandas.to_gbq函数不尊重表模式中的列顺序?
我想使用数据框将熊猫数据框上传到大查询。调用函数。 我指定一个table_schema参数来强制BigQuery中的特定列顺序(这可能与Dataframe不同)。 所以我用例如: 数据帧中的列顺序是:Col1、Col3、Col4、Col5、Col2、Col6、Col7、Col8 工作做得正确。 但是当我检查Big Query中创建(或替换)destination_table的表模式时,列顺序是:C
-
在pandas中将长整数转换为字符串(以避免使用科学符号)
我希望以下记录(当前显示为3.200000e 18,但实际上(希望)每个不同的长整数),使用pd.read_excel()创建,以不同的方式解释: 目前,它们似乎以科学符号字符串的形式出现: 然而,更糟糕的是,我不清楚这个数字是否已从我的. xlsx文件中正确读取: Excel(数据源)中的数字为320000000515952。 这与显示无关,我知道我可以在这里更改。这是关于保持底层数据在读取时的
-
pandas to csv TypeError:get_handle()获得意外的关键字参数“errors”
我有一张大桌子,我根据它们的日期把它切成许多小桌子: 我已经对dfs['2019-06-23']特定表进行了一些修改,现在我想将其保存在我的计算机上。我尝试了两种方法: 他们都提出了这个错误: get_handle()得到了一个意外的关键字参数错误 我不知道为什么会出现这个错误,也没有找到任何原因。我用这种方式保存了很多文件,但以前从未用过。 我的目标是:在修改后将此数据帧保存为csv
-
Python Pandasto_csv,你能使用.替换()抢先处理双引号转义问题吗[重复]
我试图得到一个进程去Python写入数据到. csv,然后可以BCP'd到一个MSSQL数据库。 我使用的基本to_csv命令是: 我看到的一个问题是程序如何处理文本中的双引号。如果找到一组双引号,则引号将转义。 这一行看起来像: 在加载到数据中时变成这样: 这很令人沮丧,因为这意味着如果我想在BCP之后使用数据,我需要在SQL方面进一步处理它。由于我的ETL运行在数百个表上,实现这一点将是一个巨
-
Python使用Pandas读取固定宽度文件,无需任何数据类型解释
我试图建立一个Python脚本,它将能够读取许多固定宽度的数据文件,然后将它们转换为csv。要做到这一点,我使用的熊猫是这样的: 其中和是包含读写数据所需信息的列表。 在这些文件中,我有代表测试答案的长串数字。例如:代表多项选择题测试的正确答案。所以这更多的是一个代码而不是一个数值。我遇到的问题是,熊猫将这些值解释为浮点数,然后用科学记数法将这些值写入csv(3.333332212212E 47)
-
读取pandas中CSV文件的最后一行以外的所有内容
我在pandas中读取了CSV文件,其中包括: 不幸的是,这些文件的最后一行经常损坏(逗号数错误)。目前,我在文本编辑器中打开每个文件,并删除最后一行。 有没有可能删除加载CSV的同一个python/熊猫脚本中的最后一行,以节省必须采取这个额外的非自动化步骤?
-
Pandas读取\u csv低\u内存和数据类型选项
打电话的时候 我得到: /Users/josh/anaconda/envs/py27/lib/python2。7/站点包/熊猫/io/解析器。py:1130:DtypeWarning:列(4,5,7,16)具有混合类型。在导入时指定dtype选项或将低内存设置为False。 为什么选项与相关,为什么将其设为有助于解决此问题?
-
使用Python Pandas读取制表符分隔的文件
我在使用Pandas读取选项卡分隔的文件时遇到问题。 所有单元格值都有双引号,但对于某些行,有一个额外的双引号打断了整个过程。例如: 我得到的错误是:错误标记数据。C错误:第8355行预期有31个字段,SAW58 我使用的代码是: 它适用于其余文件,但不适用于出现额外双引号的文件。
-
pandas.read_csv:如何跳过注释行
我想我误解了阅读的意图。如果我有一个像“j”这样的文件 我怎样才能看到熊猫。读取此文件,跳过任何“#”注释行?我在帮助中看到,不支持行的“注释”,但它表示应返回空行。我看到一个错误 数据标记化出错。C错误:预期第2行中的1个字段,锯3 我现在在 在版本“0.12”上。0-199-g4c8ad82': 数据标记化出错。C错误:预期第2行中的1个字段,锯3
-
使用Pandas导入每行不同列数的csv
使用Pandas或CSV模块将每行具有不同列数的CSV导入Pandas数据框的最佳方法是什么。 使用此代码: 生成以下错误