《pandas》专题
-
将组ID返回到pandas数据框
问题内容: 对于数据框 我有兴趣按名称和等级分组,并且可能会得到汇总值 但是我想在原始字段中获得一个字段,其中包含该行的组号,例如 有没有在熊猫中做到这一点的好方法? 我可以用python来获得 但是在大型数据框上它的运行速度很慢,因此我认为可能会有更好的内置熊猫方法来做到这一点。 问题答案: 很多方便的东西存储在对象中。例如: 所以: 潜伏在某个地方可能会有更好的别名,但是无论如何这应该起作用。
-
构造3D Pandas DataFrame
问题内容: 我在Pandas中构建3D DataFrame有困难。我想要这样的东西 其中,等是顶级描述符,而和是子描述符。接下来的数字是成对的,而,等的对数则不同。观察有四个这样的对,只有1个,有3个。 我不确定如何继续构造此DataFrame。修改此示例并没有给我设计输出: 产生: 有什么办法可以将C中的列表分解成自己的列? 编辑:我的结构很重要。看起来如下: 所需的输出是顶部的输出。它表示某个
-
如何使用多索引转换Pandas DataFrame?
问题内容: 使用以下DataFrame,如何在不让Pandas将移位后的值分配给其他索引值的情况下基于索引来移位“ beyer”列? 生产… 问题在于,佩恩特得到了分配最后一位战士的啤酒。相反,我希望它像这样… 问题答案: 使用应用转移到各组分别:(感谢Jeff指出这个简化) 如果您有一个多索引,则可以通过将一系列或级别名称传递给 参数来对多个级别进行分组。
-
通过不在列表中的索引值对Pandas数据框进行切片
问题内容: 我有一个数据框。 我想选择在所有指数是 不是 在列表中, 现在,我使用列表理解来创建所需的标签以进行切片。 工作正常,但如果我经常需要这样做可能会很笨拙。 有一个更好的方法吗? 问题答案: 在索引上使用并反转布尔索引以执行标签选择:
-
使用pandas索引来绘制数据
问题内容: 我有一个pandas-Dataframe并用于计算均值(例如每日或每月均值)。这是一个小例子。 我现在该如何绘制monthly_mean?如何管理将新创建的DataFrame的索引用作x轴?提前致谢。 问题答案: 您可以用来将索引变回一列:
-
pandas数据框的最大大小
问题内容: 我试图使用s或函数读取稍大的数据集,但我一直遇到s。数据框的最大大小是多少?我的理解是,只要数据适合内存,数据帧就应该可以,这对我来说不是问题。还有什么可能导致内存错误? 就上下文而言,我试图在《2007年消费者金融调查》中阅读ASCII格式(使用)和Stata格式(使用)。该文件的dta大小约为200MB,而ASCII的大小约为1.2GB,在Stata中打开该文件将告诉我,对于22,
-
使用pandas读取zip文件中包含的多个文件
问题内容: 我有多个包含不同类型的txt文件的zip文件。如下所示: 如何使用pandas读取每个文件而不提取它们? 我知道每个zip文件是否为1个文件,我可以对read_csv使用压缩方法,如下所示: 任何有关如何执行此操作的帮助都将非常有用。 问题答案: 你可以传递到构建从包装成一个多文件一个CSV文件。 码: 将所有内容读入字典的示例:
-
可以memmap pandas系列。数据框呢?
问题内容: 似乎我可以通过创建mmap’d ndarray并使用它来初始化python系列的memmap底层数据。 成功!似乎它由只读的内存映射ndarray支持。我可以对DataFrame做同样的事情吗?以下失败 以下成功,但仅适用于一列: …这样我 就可以 不复制而制作DF。但是,这仅适用于一列,我想要很多。我发现了用于组合1列DF的方法:pd.concat(.. copy = False),
-
了解pandas数据框索引
问题内容: 摘要:这不起作用: 但是这样做: 为什么? 再生产: 这不起作用: 但是这样做: 链接到笔记本 我的问题是: 为什么只有第二种方式起作用?我似乎看不到选择/索引逻辑的差异。 版本是0.10.0 编辑:这不应该再这样了。从0.11版开始,提供。参见此处:http : //pandas.pydata.org/pandas- docs/stable/indexing.html 问题答案: 大
-
Python(Pandas):将数据框存储在具有多索引的hdf5中
问题内容: 我需要使用具有多个索引的大型数据框,因此我尝试创建一个数据框以了解如何将其存储在hdf5文件中。数据框是这样的:(在前2列中有multi索引) 我正在使用pandas.to_hdf,但在尝试选择组中的数据时会创建“固定格式存储”: 它返回一些错误,主要问题是 然后我试图像这样追加DataFrame: 那应该创建一个表,但这给了我另一个错误: 所以我需要的代码将数据帧存储在一个表中HDF
-
Pandas中的SQL中EXCEPT子句的相似之处是什么?
问题内容: 我有一个示例熊猫数据框df: 第二个df1: 我想获取不与df1重叠的df子集。实际上,我正在寻找SQL中EXCEPT操作数的等效项。 我使用了减去()函数-但这显然是错误的,因为减法执行逐元素的数值减法。所以我收到一条错误消息: 因此,问题是:熊猫SQL中的EXCEPT等效项是什么? 问题答案: 我认为您首先需要所有字符串列: 或者: 通过修改后的问题进行编辑:
-
Python Pandas-比较2个数据框,多个参数
问题内容: 我有两张桌子。一个(下面的df)大约有18,000行,另一个(下面的映射文件)大约有80万行。我需要一个可以与如此大的DataFrames一起使用的解决方案。 这是一个玩具示例:表1-df 表2-映射文件 我正在尝试执行以下操作(我的语法是错误的,但是我认为这个想法会出现): 换句话说:我需要遍历mapfile中的每个项目(行),看看它的位置是否在df中每个CHR的任何START和EN
-
在构建Pandas DataFrame中使用逻辑运算符
问题内容: 我有两段熊猫代码,我认为它们应该是等效的,但是第二段代码并没有达到我的期望。 每个部分(例如)都按照自己的期望进行操作,但是似乎我在逻辑运算符上做错了,因为最终结果与列表理解版本的结果不同。 问题答案: 的操作者比结合更紧密地(或任何比较操作符)。请参阅文档。一个简单的例子是: 这是因为将其分组为,然后调用了比较链接。这就是您的情况。您需要在每个比较之间加上括号。 请注意和比较中的多余
-
从Numpy数组创建Pandas DataFrame:如何指定索引列和列标题?
问题内容: 我有一个由列表列表组成的Numpy数组,代表带有行标签和列名的二维数组,如下所示: 我希望所得的DataFrame将Row1和Row2作为索引值,并将Col1,Col2作为标头值 我可以指定索引如下: 但是我不确定如何最好地分配列标题。 问题答案: 您需要指定,并以构造函数,如: 编辑 :如@joris注释中所示,您可能需要更改上述内容才能具有正确的数据类型。
-
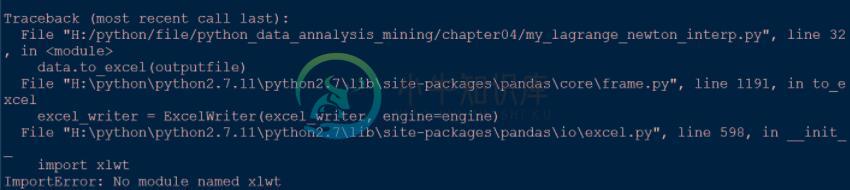 解决Python pandas df 写入excel 出现的问题
解决Python pandas df 写入excel 出现的问题本文向大家介绍解决Python pandas df 写入excel 出现的问题,包括了解决Python pandas df 写入excel 出现的问题的使用技巧和注意事项,需要的朋友参考一下 学习Python数据分析挖掘实战一书时,在数据预处理阶段,有一节要使用拉格朗日插值法对缺失值补充,代码如下: 1.import xlwt 错误 这个问题比较简单,只需要在官网上下载安装或者直接在编译器中运行如