《爬虫》专题
-
 Python爬虫常用库的安装及其环境配置
Python爬虫常用库的安装及其环境配置本文向大家介绍Python爬虫常用库的安装及其环境配置,包括了Python爬虫常用库的安装及其环境配置的使用技巧和注意事项,需要的朋友参考一下 Python常用库的安装 urllib、re 这两个库是Python的内置库,直接使用方法import导入即可。 在python中输入如下代码: 返回结果为HTTPResponse的对象: <http.client.HTTPResponse object
-
python中用Scrapy实现定时爬虫的实例讲解
本文向大家介绍python中用Scrapy实现定时爬虫的实例讲解,包括了python中用Scrapy实现定时爬虫的实例讲解的使用技巧和注意事项,需要的朋友参考一下 一般网站发布信息会在具体实现范围内发布,我们在进行网络爬虫的过程中,可以通过设置定时爬虫,定时的爬取网站的内容。使用python爬虫框架Scrapy框架可以实现定时爬虫,而且可以根据我们的时间需求,方便的修改定时的时间。 1、Scrap
-
 python3爬虫中多线程进行解锁操作实例
python3爬虫中多线程进行解锁操作实例本文向大家介绍python3爬虫中多线程进行解锁操作实例,包括了python3爬虫中多线程进行解锁操作实例的使用技巧和注意事项,需要的朋友参考一下 生活中我们为了保障房间里物品的安全,所以给门进行上锁,在我们需要进入房间的时候又会重新打开。同样的之间我们讲过多线程中的lock,作用是为了不让多个线程运行是出错所以进行锁住的指令。但是鉴于我们实际运用中,因为线程和指令不会只有一个,如果全部都进行lo
-
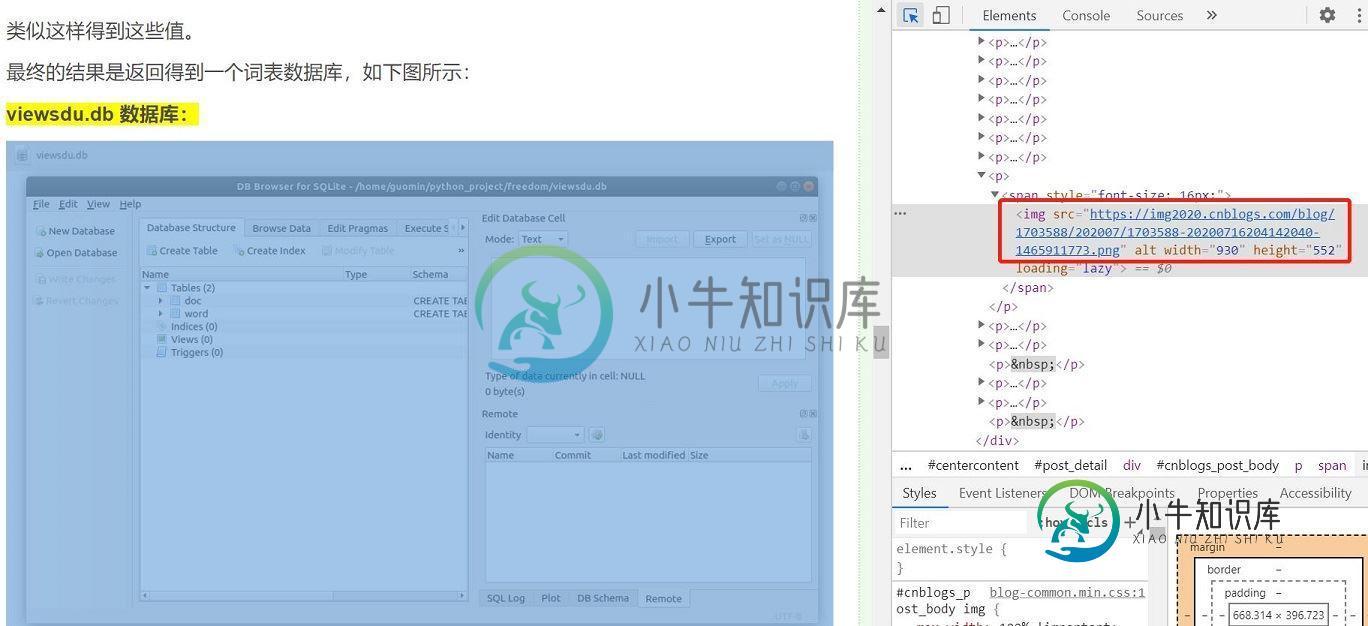 Python爬虫抓取指定网页图片代码实例
Python爬虫抓取指定网页图片代码实例本文向大家介绍Python爬虫抓取指定网页图片代码实例,包括了Python爬虫抓取指定网页图片代码实例的使用技巧和注意事项,需要的朋友参考一下 想要爬取指定网页中的图片主要需要以下三个步骤: (1)指定网站链接,抓取该网站的源代码(如果使用google浏览器就是按下鼠标右键 -> Inspect-> Elements 中的 html 内容) (2)根据你要抓取的内容设置正则表达式以匹配要抓取的内容
-
 Python爬虫之模拟知乎登录的方法教程
Python爬虫之模拟知乎登录的方法教程本文向大家介绍Python爬虫之模拟知乎登录的方法教程,包括了Python爬虫之模拟知乎登录的方法教程的使用技巧和注意事项,需要的朋友参考一下 前言 对于经常写爬虫的大家都知道,有些页面在登录之前是被禁止抓取的,比如知乎的话题页面就要求用户登录才能访问,而 “登录” 离不开 HTTP 中的 Cookie 技术。 登录原理 Cookie 的原理非常简单,因为 HTTP 是一种无状态的协议,因此为了在
-
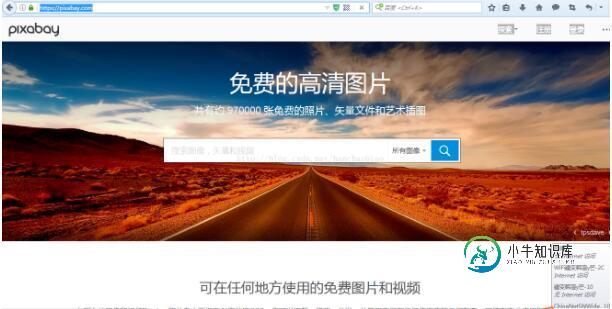 Python3.x爬虫下载网页图片的实例讲解
Python3.x爬虫下载网页图片的实例讲解本文向大家介绍Python3.x爬虫下载网页图片的实例讲解,包括了Python3.x爬虫下载网页图片的实例讲解的使用技巧和注意事项,需要的朋友参考一下 一、选取网址进行爬虫 本次我们选取pixabay图片网站 二、选择图片右键选择查看元素来寻找图片链接的规则 通过查看多个图片路径我们发现取src路径都含有 https://cdn.pixabay.com/photo/ 公共部分且图片格式都为.jpg
-
Python基于BeautifulSoup和requests实现的爬虫功能示例
本文向大家介绍Python基于BeautifulSoup和requests实现的爬虫功能示例,包括了Python基于BeautifulSoup和requests实现的爬虫功能示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python基于BeautifulSoup和requests实现的爬虫功能。分享给大家供大家参考,具体如下: 爬取的目标网页:http://www.qianlima.
-
python实现爬虫统计学校BBS男女比例(一)
本文向大家介绍python实现爬虫统计学校BBS男女比例(一),包括了python实现爬虫统计学校BBS男女比例(一)的使用技巧和注意事项,需要的朋友参考一下 一、项目需求 前言:BBS上每个id对应一个用户,他们注册时候会填写性别(男、女、保密三选一)。 经过检查,BBS注册用户的id对应1-300000,大概是30万的用户 笔者想用Python统计BBS上有多少注册用户,以及这些用户的性别分布
-
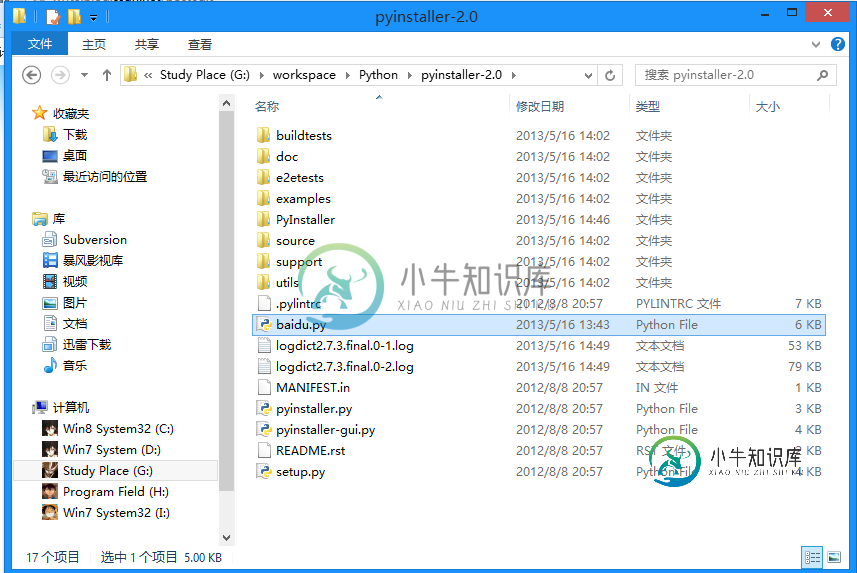 零基础写python爬虫之打包生成exe文件
零基础写python爬虫之打包生成exe文件本文向大家介绍零基础写python爬虫之打包生成exe文件,包括了零基础写python爬虫之打包生成exe文件的使用技巧和注意事项,需要的朋友参考一下 1.下载pyinstaller并解压(可以去官网下载最新版): https://github.com/pyinstaller/pyinstaller/ 2.下载pywin32并安装(注意版本,我的是python2.7): https://pypi.
-
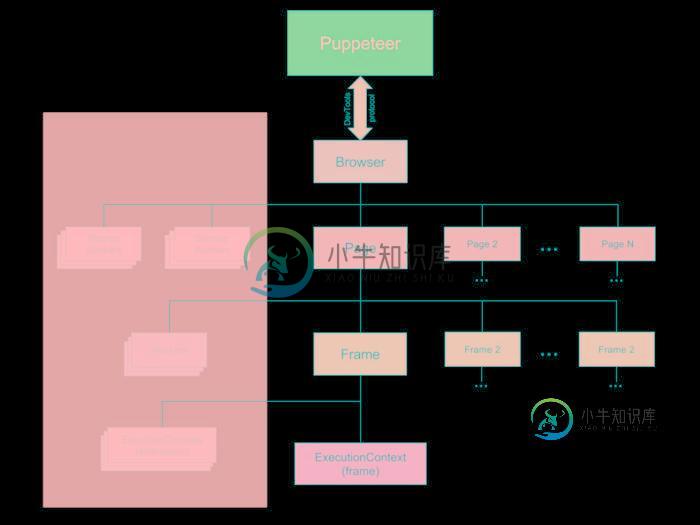 详解Node使用Puppeteer完成一次复杂的爬虫
详解Node使用Puppeteer完成一次复杂的爬虫本文向大家介绍详解Node使用Puppeteer完成一次复杂的爬虫,包括了详解Node使用Puppeteer完成一次复杂的爬虫的使用技巧和注意事项,需要的朋友参考一下 本文介绍了详解Node使用Puppeteer完成一次复杂的爬虫,分享给大家,具体如下: 架构图 Puppeteer架构图 Puppeteer 通过 devTools 与 browser 通信 Browser 一个可以拥有多个页面的浏
-
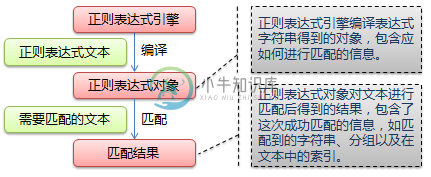 零基础写python爬虫之神器正则表达式
零基础写python爬虫之神器正则表达式本文向大家介绍零基础写python爬虫之神器正则表达式,包括了零基础写python爬虫之神器正则表达式的使用技巧和注意事项,需要的朋友参考一下 接下来准备用糗百做一个爬虫的小例子。 但是在这之前,先详细的整理一下Python中的正则表达式的相关内容。 正则表达式在Python爬虫中的作用就像是老师点名时用的花名册一样,是必不可少的神兵利器。 一、 正则表达式基础 1.1.概念介绍 正则表达式是用于
-
 Python爬虫实战:王者荣耀全套皮肤采集
Python爬虫实战:王者荣耀全套皮肤采集王者荣耀这款手游,想必大家都玩过或听过,虽已运营多年,但热度依然不减当年,各种英雄配上各式各样的皮肤,甚是精美, 今天就教大家如何利用几行Python代码爬取王者荣耀全套皮肤~~ 01网页分析 首先打开王者荣耀官网,点击英雄资料
-
 python爬取youtube视频的示例代码
python爬取youtube视频的示例代码本文向大家介绍python爬取youtube视频的示例代码,包括了python爬取youtube视频的示例代码的使用技巧和注意事项,需要的朋友参考一下 这几天正在追剧,原名《大秦帝国之天下》的《大秦赋》,看着看着又想把前几部刷一遍了,但第一部《裂变》自己没有高清资源,搜了一波发现youtube上有个48集版的高清资源,有删减就有删减吧,就想着写个脚本批量下载一下,记录一下过程,主要是youtu
-
 python批量爬取下载抖音视频
python批量爬取下载抖音视频本文向大家介绍python批量爬取下载抖音视频,包括了python批量爬取下载抖音视频的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了python批量爬取下载抖音视频的具体代码,供大家参考,具体内容如下 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
粘附爬行器以读取Json数组
我有一个Json数组文件的格式:-[[{key1:value1},{key2:value2},{key3:value3}],[{key1:value4},{key2:value5},{key3:value6}]] 我需要使用AWS glue爬取上述文件,并读取json模式,其中每个键都作为模式中的一列。我尝试使用标准的json分类器,但它似乎不起作用,并且模式加载为数组。我需要从S3读取json文