《爬虫》专题
-
node.js实现博客小爬虫的实例代码
本文向大家介绍node.js实现博客小爬虫的实例代码,包括了node.js实现博客小爬虫的实例代码的使用技巧和注意事项,需要的朋友参考一下 前言 爬虫,是一种自动获取网页内容的程序。是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上就是针对爬虫而做出的优化。 这篇文章介绍的是利用node.js实现博客小爬虫,核心的注释我都标注好了,可以自行理解,只需修改url和按照要趴的博客内部dom构造改一下
-
 Python代理IP爬虫的新手使用教程
Python代理IP爬虫的新手使用教程本文向大家介绍Python代理IP爬虫的新手使用教程,包括了Python代理IP爬虫的新手使用教程的使用技巧和注意事项,需要的朋友参考一下 前言 Python爬虫要经历爬虫、爬虫被限制、爬虫反限制的过程。当然后续还要网页爬虫限制优化,爬虫再反限制的一系列道高一尺魔高一丈的过程。爬虫的初级阶段,添加headers和ip代理可以解决很多问题。 本人自己在爬取豆瓣读书的时候,就以为爬取次数过多,直接被封
-
java实现简单的爬虫之今日头条
本文向大家介绍java实现简单的爬虫之今日头条,包括了java实现简单的爬虫之今日头条的使用技巧和注意事项,需要的朋友参考一下 前言 需要提前说下的是,由于今日头条的文章的特殊性,所以无法直接获取文章的地址,需要获取文章的id然后在拼接成url再访问。下面话不多说了,直接上代码。 示例代码如下 总结 以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可
-
简单的抓取淘宝图片的Python爬虫
本文向大家介绍简单的抓取淘宝图片的Python爬虫,包括了简单的抓取淘宝图片的Python爬虫的使用技巧和注意事项,需要的朋友参考一下 写了一个抓taobao图片的爬虫,全是用if,for,while写的,比较简陋,入门作品。 从网页http://mm.taobao.com/json/request_top_list.htm?type=0&page=中提取taobao模特的照片。 是不是很简单呢,
-
Python的Scrapy爬虫框架简单学习笔记
本文向大家介绍Python的Scrapy爬虫框架简单学习笔记,包括了Python的Scrapy爬虫框架简单学习笔记的使用技巧和注意事项,需要的朋友参考一下 一、简单配置,获取单个网页上的内容。 (1)创建scrapy项目 (2)编辑 items.py (3)在 spiders 文件夹下,创建 blog_spider.py 需要熟悉下xpath选择,感觉跟JQuery选择器差不多,但是不如
-
Python爬虫实现模拟点击动态页面
本文向大家介绍Python爬虫实现模拟点击动态页面,包括了Python爬虫实现模拟点击动态页面的使用技巧和注意事项,需要的朋友参考一下 动态页面的模拟点击: 以斗鱼直播为例:http://www.douyu.com/directory/all 爬取每页的房间名、直播类型、主播名称、在线人数等数据,然后模拟点击下一页,继续爬取 代码如下 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多
-
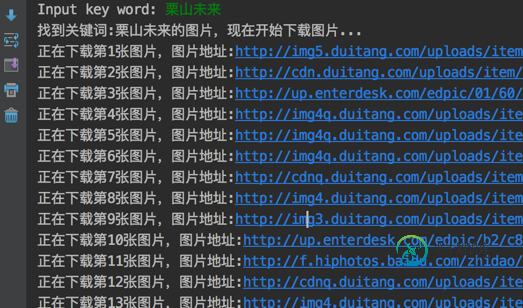 Python爬虫实现百度图片自动下载
Python爬虫实现百度图片自动下载本文向大家介绍Python爬虫实现百度图片自动下载,包括了Python爬虫实现百度图片自动下载的使用技巧和注意事项,需要的朋友参考一下 制作爬虫的步骤 制作一个爬虫一般分以下几个步骤: 分析需求分析网页源代码,配合开发者工具编写正则表达式或者XPath表达式正式编写 python 爬虫代码 效果预览 运行效果如下: 存放图片的文件夹: 需求分析 我们的爬虫至少要实现两个功能:一是搜索图片,二是自动
-
python爬虫 urllib模块url编码处理详解
本文向大家介绍python爬虫 urllib模块url编码处理详解,包括了python爬虫 urllib模块url编码处理详解的使用技巧和注意事项,需要的朋友参考一下 案例:爬取使用搜狗根据指定词条搜索到的页面数据(例如爬取词条为‘周杰伦'的页面数据) 编码错误 【注意】上述代码中url存在非ascii编码的数据,则该url无效。如果对其发起请求,则会报如下错误: url的特性:url不可以存在非
-
 零基础写python爬虫之urllib2使用指南
零基础写python爬虫之urllib2使用指南本文向大家介绍零基础写python爬虫之urllib2使用指南,包括了零基础写python爬虫之urllib2使用指南的使用技巧和注意事项,需要的朋友参考一下 前面说到了urllib2的简单入门,下面整理了一部分urllib2的使用细节。 1.Proxy 的设置 urllib2 默认会使用环境变量 http_proxy 来设置 HTTP Proxy。 如果想在程序中明确控制 Proxy 而不受环境
-
Java中的网络爬虫。下载网页问题
我正在尝试开发一个小的网络爬虫,它下载网页并搜索特定部分的链接。但当我运行这段代码时,“href”标记中的链接会变短。如: 原文链接:“/kids-toys-action-figures-accessories/b/ref=toys_hp_catblock_actnfig?ie=utf8&node=165993011&pf_rd_m=atvpdkikx0der&pf_rd_s=merchandis
-
scrapy 爬虫抓取网页写入 mysql 数据库
安装MySQL-python [root@centos7vm ~]# pip install MySQL-python 执行如下不报错说明安装成功: [root@centos7vm ~]# python Python 2.7.5 (default, Nov 20 2015, 02:00:19) [GCC 4.8.5 20150623 (Red Hat 4.8.5-4)] on linux2 T
-
 python爬虫 - https认证如何用代码实现?
python爬虫 - https认证如何用代码实现?这个网页的数据如何获得? https://fiin-core.ssi.com.vn/Master/GetListOrganization?langu... 访问的时候,要求认证 点击,verify you are human,可以看到数据。 现在,我想抓取这些数据: 怎么办呢?
-
python3.x - python mitmproxy高级爬虫问题,求解决?
我要把downstream_port传到tiktok_response_interceptor.py脚本, 我目前的方法是 tiktok_response_interceptor-9092.py tiktok_response_interceptor-9093.py tiktok_response_interceptor-9094.py 然后文件中也写死 这大概不是最好的方法
-
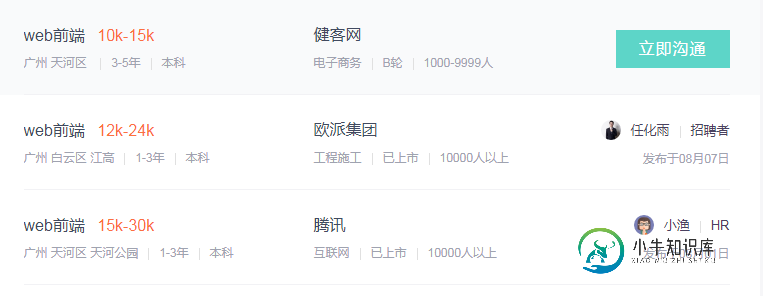 NodeJs实现简单的爬虫功能案例分析
NodeJs实现简单的爬虫功能案例分析本文向大家介绍NodeJs实现简单的爬虫功能案例分析,包括了NodeJs实现简单的爬虫功能案例分析的使用技巧和注意事项,需要的朋友参考一下 1.爬虫:爬虫,是一种按照一定的规则,自动地抓取网页信息的程序或者脚本;利用NodeJS实现一个简单的爬虫案例,爬取Boss直聘网站的web前端相关的招聘信息,以广州地区为例; 2.脚本所用到的nodejs模块 express 用来搭建一个服务,将结果
-
 Python爬虫学习之获取指定网页源码
Python爬虫学习之获取指定网页源码本文向大家介绍Python爬虫学习之获取指定网页源码,包括了Python爬虫学习之获取指定网页源码的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了Python获取指定网页源码的具体代码,供大家参考,具体内容如下 1、任务简介 前段时间一直在学习Python基础知识,故未更新博客,近段时间学习了一些关于爬虫的知识,我会分为多篇博客对所学知识进行更新,今天分享的是获取指定网页源码的方法,