《爬虫》专题
-
什么是爬山法(Hill Climbing)?
本文向大家介绍什么是爬山法(Hill Climbing)?相关面试题,主要包含被问及什么是爬山法(Hill Climbing)?时的应答技巧和注意事项,需要的朋友参考一下 DFS的变形,不同的是每次选择的是最优的一个子结点,即局部最优解 例如,对于8数码问题,设置一个函数表示放错位置的数目,每次选择子结点中放错最少的结点 步骤: 1.建立一个栈,将根结点放入栈 2.判断栈顶元素是否是目标结点,如果
-
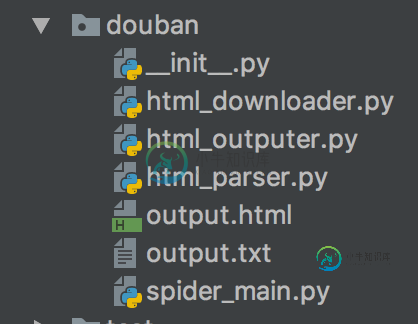 Python爬豆瓣电影实例
Python爬豆瓣电影实例本文向大家介绍Python爬豆瓣电影实例,包括了Python爬豆瓣电影实例的使用技巧和注意事项,需要的朋友参考一下 文件结构 html_downloader.py - 下载网页html内容 html_outputer.py - 输出结果到文件中 html_parser.py: 解析器:解析html的dom树 spider_main.py - 主函数 综述 其实就是使用了urllib2和Beauti
-
刮擦蜘蛛停止爬行
我试着在一个. asp网站上运行一个蜘蛛,它需要登录授权和一些爬行到同一个网站内的不同页面。我昨天成功地使用我的蜘蛛登录,并正在用不同的功能抓取数据,当我在更改了as功能后再次运行蜘蛛时,蜘蛛停止了工作。我不知道发生了什么,我对网络抓取相当陌生。下面是代码: 以下是日志: 代码曾经能够尝试从页面中抓取一些我想要的数据,但没有成功,但我相信这只是因为我使用了错误的css选择器。现在它只是打开和关闭而
-
粗糙的蜘蛛不爬行
我正试着测试这只痒痒的爬行蜘蛛,但我不明白它为什么不爬行。它应该做的是在wikipedia的数学页面上爬行一个深度级别,然后返回每个爬行页面的标题。我错过了什么?非常感谢您的帮助! 设置: 日志:
-
10. Selenium爬取淘宝商品
① 案例要求 使用Selenium爬取淘宝商品,指定关键字和指定页码信息来进行爬取 ② 案例分析: url地址:https://s.taobao.com/search?q=ipad ③ 具体代码实现 '''通过关键字爬取淘宝网站的信息数据''' from selenium import webdriver from selenium.common.exceptions import Timeout
-
19. Ajax信息爬取实战
Ajax = 异步 JavaScript 和 XML(标准通用标记语言的子集)。 Ajax 是一种用于创建快速动态网页的技术。 Ajax 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。 案例:爬取京东指定商品信息的评论信息 #爬取指定京东商品的评论信息 import requests import re # header头信息 headers = { 'User-Agen
-
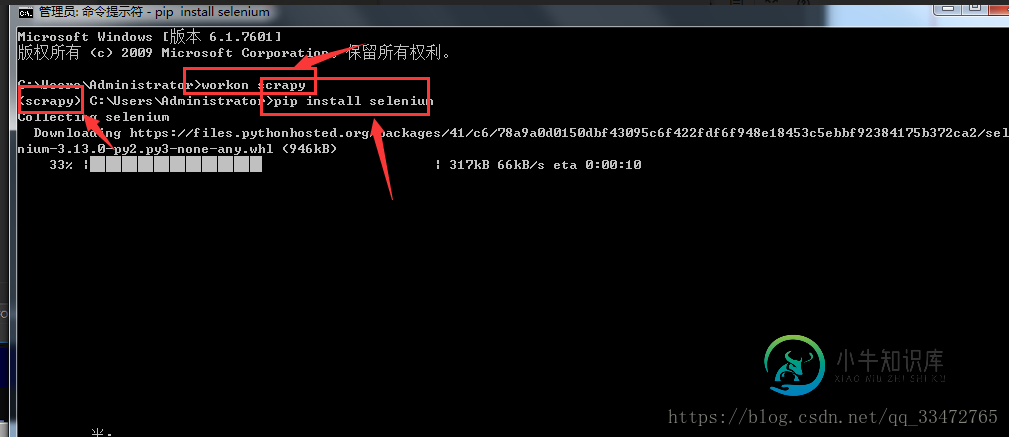 scrapy与selenium结合爬取数据(爬取动态网站)的示例代码
scrapy与selenium结合爬取数据(爬取动态网站)的示例代码本文向大家介绍scrapy与selenium结合爬取数据(爬取动态网站)的示例代码,包括了scrapy与selenium结合爬取数据(爬取动态网站)的示例代码的使用技巧和注意事项,需要的朋友参考一下 scrapy框架只能爬取静态网站。如需爬取动态网站,需要结合着selenium进行js的渲染,才能获取到动态加载的数据。 如何通过selenium请求url,而不再通过下载器Downloader去请求
-
 python实现简单爬虫功能的示例
python实现简单爬虫功能的示例本文向大家介绍python实现简单爬虫功能的示例,包括了python实现简单爬虫功能的示例的使用技巧和注意事项,需要的朋友参考一下 在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材。 我们最常规的做法就是通过鼠标右键,选择另存为。但有些图片鼠标右键的时候并没有另存为选项,还有办法就通过就是通过截图工具截取下来,但这样
-
 nodejs爬虫抓取数据之编码问题
nodejs爬虫抓取数据之编码问题本文向大家介绍nodejs爬虫抓取数据之编码问题,包括了nodejs爬虫抓取数据之编码问题的使用技巧和注意事项,需要的朋友参考一下 cheerio DOM化并解析的时候 1.假如使用了 .text()方法,则一般不会有html实体编码的问题出现 2.如果使用了 .html()方法,则很多情况下(多数是非英文的时候)都会出现,这时,可能就需要转义一番了 类似这些 因为需要作数据存储,所有需要转换 大
-
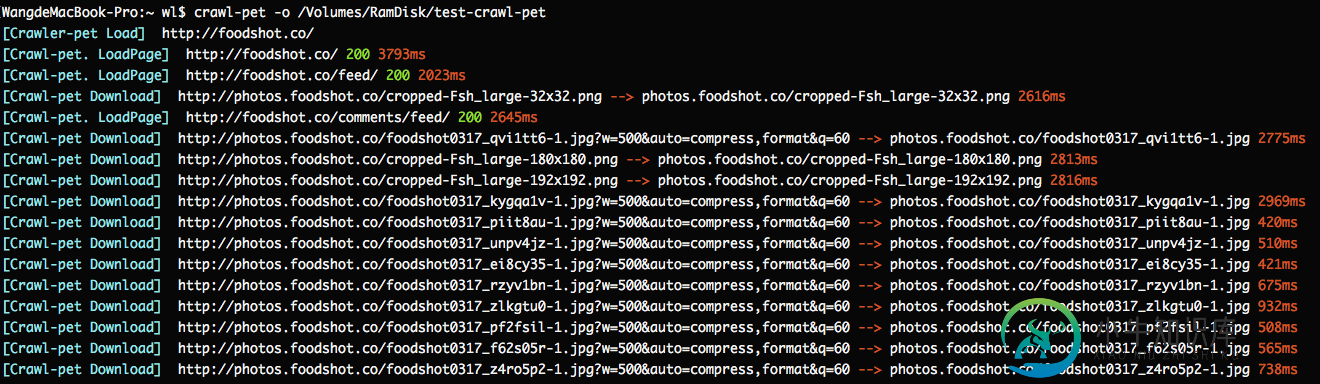 简单好用的nodejs 爬虫框架分享
简单好用的nodejs 爬虫框架分享本文向大家介绍简单好用的nodejs 爬虫框架分享,包括了简单好用的nodejs 爬虫框架分享的使用技巧和注意事项,需要的朋友参考一下 这个就是一篇介绍爬虫框架的文章,开头就不说什么剧情了。什么最近一个项目了,什么分享新知了,剧情是挺好,但介绍的很初级,根本就没有办法应用,不支持队列的爬虫,都是耍流氓。 所以我就先来举一个例子,看一下这个爬虫框架是多么简单并可用。 第一步:安装 Crawl-pet
-
python爬虫中多线程的使用详解
本文向大家介绍python爬虫中多线程的使用详解,包括了python爬虫中多线程的使用详解的使用技巧和注意事项,需要的朋友参考一下 queue介绍 queue是python的标准库,俗称队列.可以直接import引用,在python2.x中,模块名为Queue。python3直接queue即可 在python中,多个线程之间的数据是共享的,多个线程进行数据交换的时候,不能够保证数据的安全性和一致性
-
PHP一个简单的无需刷新爬虫
本文向大家介绍PHP一个简单的无需刷新爬虫,包括了PHP一个简单的无需刷新爬虫的使用技巧和注意事项,需要的朋友参考一下 由于只是一个小示例,所以过程化简单写了,小菜随便参考,大神大可点解 接下的入表库当然就不写了,那些更小意思了~就此别过吧~ 总结 以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对呐喊教程的支持。如果你想了解更多相关内容请查看下面相
-
 PHP+HTML+JavaScript+Css实现简单爬虫开发
PHP+HTML+JavaScript+Css实现简单爬虫开发本文向大家介绍PHP+HTML+JavaScript+Css实现简单爬虫开发,包括了PHP+HTML+JavaScript+Css实现简单爬虫开发的使用技巧和注意事项,需要的朋友参考一下 开发一个爬虫,首先你要知道你的这个爬虫是要用来做什么的。我是要用来去不同网站找特定关键字的文章,并获取它的链接,以便我快速阅读。 按照个人习惯,我首先要写一个界面,理清下思路。 1、去不同网站。那么我们需
-
PHP代码实现爬虫记录——超管用
本文向大家介绍PHP代码实现爬虫记录——超管用,包括了PHP代码实现爬虫记录——超管用的使用技巧和注意事项,需要的朋友参考一下 实现爬虫记录本文从创建crawler 数据库,robot.php记录来访的爬虫从而将信息插入数据库crawler,然后从数据库中就可以获得所有的爬虫信息。实现代码具体如下: 数据库设计 以下文件 robot.php 记录来访的爬虫,并将信息写入数据库: 成功了,现在访问数
-
python制作花瓣网美女图片爬虫
本文向大家介绍python制作花瓣网美女图片爬虫,包括了python制作花瓣网美女图片爬虫的使用技巧和注意事项,需要的朋友参考一下 花瓣图片的加载使用了延迟加载的技术,源代码只能下载20多张图片,修改后基本能下载所有的了,只是速度有点慢,后面再优化下