《爬虫》专题
-
使用 Node.js 开发资讯爬虫流程
本文向大家介绍使用 Node.js 开发资讯爬虫流程,包括了使用 Node.js 开发资讯爬虫流程的使用技巧和注意事项,需要的朋友参考一下 最近项目需要一些资讯,因为项目是用 Node.js 来写的,所以就自然地用 Node.js 来写爬虫了 项目地址:github.com/mrtanweijie… ,项目里面爬取了 Readhub 、 开源中国 、 开发者头条 、 36Kr 这几个网站的资讯内容
-
 用Python编写简单的微博爬虫
用Python编写简单的微博爬虫本文向大家介绍用Python编写简单的微博爬虫,包括了用Python编写简单的微博爬虫的使用技巧和注意事项,需要的朋友参考一下 先说点题外话,我一开始想使用Sina Weibo API来获取微博内容,但后来发现新浪微博的API限制实在太多,大家感受一下: 只能获取当前授权的用户(就是自己),而且只能返回最新的5条,WTF! 所以果断放弃掉这条路,改为『生爬』,因为PC端的微博是Ajax的动态加载,
-
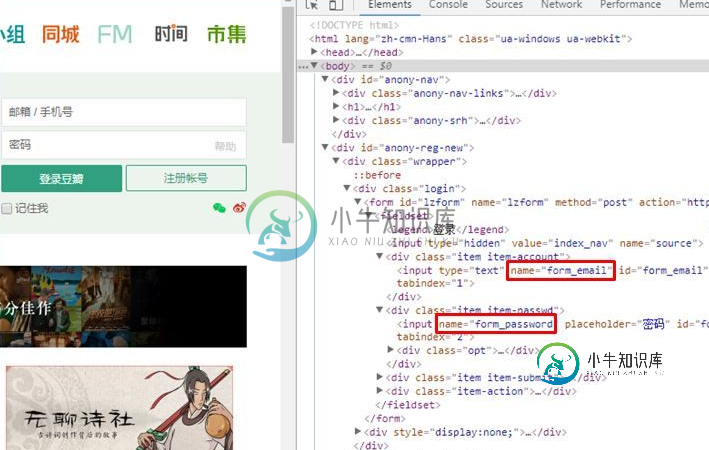 Python爬虫中urllib库的进阶学习
Python爬虫中urllib库的进阶学习本文向大家介绍Python爬虫中urllib库的进阶学习,包括了Python爬虫中urllib库的进阶学习的使用技巧和注意事项,需要的朋友参考一下 urllib的基本用法 urllib库的基本组成 利用最简单的urlopen方法爬取网页html 利用Request方法构建headers模拟浏览器操作 error的异常操作 urllib库除了以上基础的用法外,还有很多高级的功能,可以更加灵活的适用在
-
python支持多线程的爬虫实例
本文向大家介绍python支持多线程的爬虫实例,包括了python支持多线程的爬虫实例的使用技巧和注意事项,需要的朋友参考一下 python是支持多线程的, 主要是通过thread和threading这两个模块来实现的,本文主要给大家分享python实现多线程网页爬虫 一般来说,使用线程有两种模式, 一种是创建线程要执行的函数, 把这个函数传递进Thread对象里,让它来执行. 另一种是直接从Th
-
python爬虫实现中英翻译词典
本文向大家介绍python爬虫实现中英翻译词典,包括了python爬虫实现中英翻译词典的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了python爬虫实现中英翻译词典的具体代码,供大家参考,具体内容如下 通过根据某平台的翻译资源,提取出翻译信息,并展示出来,包括输入,翻译,输出三个过程,主要利用python语言实现(python3.6),抓取信息展示。 以上就是本文的全部内容,希望对
-
基python实现多线程网页爬虫
本文向大家介绍基python实现多线程网页爬虫,包括了基python实现多线程网页爬虫的使用技巧和注意事项,需要的朋友参考一下 一般来说,使用线程有两种模式, 一种是创建线程要执行的函数, 把这个函数传递进Thread对象里,让它来执行. 另一种是直接从Thread继承,创建一个新的class,把线程执行的代码放到这个新的class里。 实现多线程网页爬虫,采用了多线程和锁机制,实现了广度优先算法
-
 基于python爬虫数据处理(详解)
基于python爬虫数据处理(详解)本文向大家介绍基于python爬虫数据处理(详解),包括了基于python爬虫数据处理(详解)的使用技巧和注意事项,需要的朋友参考一下 一、首先理解下面几个函数 设置变量 length()函数 char_length() replace() 函数 max() 函数 1.1、设置变量 set @变量名=值 1.2 、length()函数 char_length()函数区别 1.3、 replace(
-
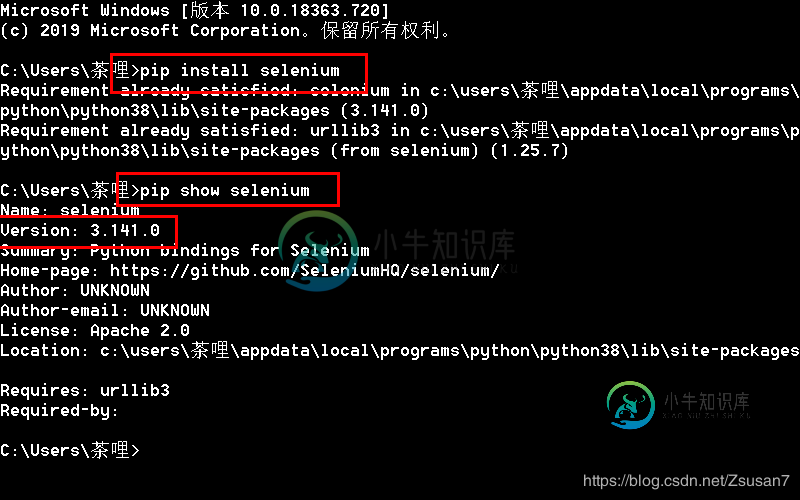 python+selenium+chromedriver实现爬虫示例代码
python+selenium+chromedriver实现爬虫示例代码本文向大家介绍python+selenium+chromedriver实现爬虫示例代码,包括了python+selenium+chromedriver实现爬虫示例代码的使用技巧和注意事项,需要的朋友参考一下 下载好所需程序 1.Selenium简介 Selenium是一个用于Web应用程序测试的工具,直接运行在浏览器中,就像真正的用户在操作一样。 2.Selenium安装 方法一:在Windows
-
python实现爬虫下载美女图片
本文向大家介绍python实现爬虫下载美女图片,包括了python实现爬虫下载美女图片的使用技巧和注意事项,需要的朋友参考一下 本次爬取的贴吧是百度的美女吧,给广大男同胞们一些激励 在爬取之前需要在浏览器先登录百度贴吧的帐号,各位也可以在代码中使用post提交或者加入cookie 爬行地址:http://tieba.baidu.com/f?kw=%E7%BE%8E%E5%A5%B3&ie=utf-
-
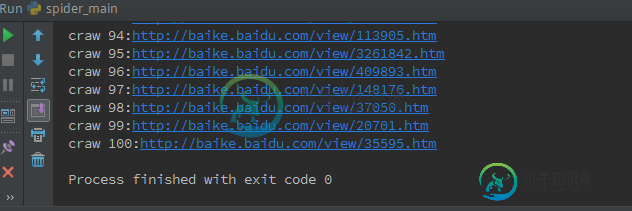 python编写简单爬虫资料汇总
python编写简单爬虫资料汇总本文向大家介绍python编写简单爬虫资料汇总,包括了python编写简单爬虫资料汇总的使用技巧和注意事项,需要的朋友参考一下 爬虫真是一件有意思的事儿啊,之前写过爬虫,用的是urllib2、BeautifulSoup实现简单爬虫,scrapy也有实现过。最近想更好的学习爬虫,那么就尽可能的做记录吧。这篇博客就我今天的一个学习过程写写吧。 一 正则表达式 正则表达式是一个很强大的工具了,众
-
第十四章 数据采集与爬虫
一 数据采集概念 任何完整的大数据平台,一般包括以下的几个过程: 数据采集 数据存储 数据处理 数据展现(可视化,报表和监控) 其中,数据采集是所有数据系统必不可少的,随着大数据越来越被重视,数据采集的挑战也变的尤为突出。这其中包括: 数据源多种多样 数据量大,变化快 如何保证数据采集的可靠性的性能 如何避免重复数据 如何保证数据的质量 我们今天就来看看当前可用的六款数据采集的产品,重点关注它们是
-
《使用 superagent 与 cheerio 完成简单爬虫》
目标 建立一个 lesson3 项目,在其中编写代码。 当在浏览器中访问 http://localhost:3000/ 时,输出 CNode(https://cnodejs.org/ ) 社区首页的所有帖子标题和链接,以 json 的形式。 输出示例: [ { "title": "【公告】发招聘帖的同学留意一下这里", "href": "http://cnodejs.org/t
-
十、Python网络爬虫进阶实战(中)
-
九、Python网络爬虫进阶实战(上)
1. Scrapy框架介绍与安装 2. Scrapy框架的使用 3. Selector选择器 4. Spider的使用 5. Downloader Middleware的使用 6. Spider Middleware的使用 7. ItemPipeline的使用 8. Scrapy实战案例 本周作业
-
21. 网络爬虫阶段案例实战
任务:Ajax爬取今日头条的街拍美图 爬取url地址:https://www.toutiao.com/search_content/ 分析: 分析url地址:https://www.toutiao.com/search_content/? 每页20条数据,Ajax加载数据 需要提交参数: params = { 'offset': offset, #页码数据