
python+selenium+chromedriver实现爬虫示例代码

下载好所需程序
1.Selenium简介
Selenium是一个用于Web应用程序测试的工具,直接运行在浏览器中,就像真正的用户在操作一样。
2.Selenium安装
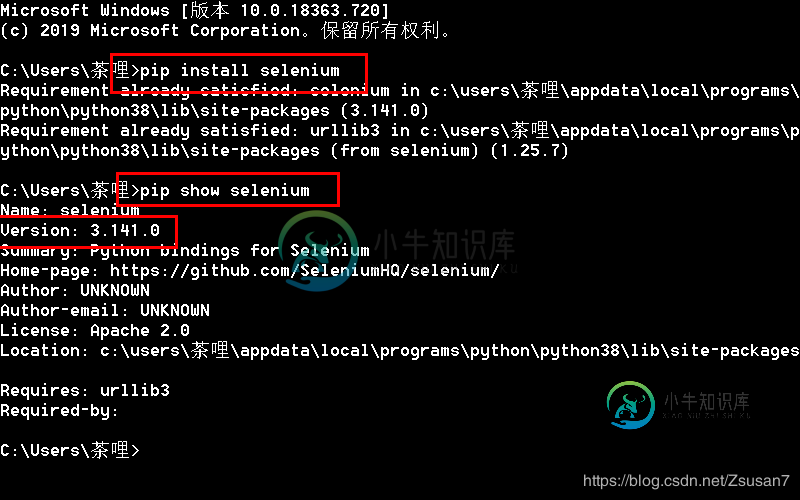
方法一:在Windows命令行(cmd)输入pip install selenium即可自动安装,安装完成后,输入pip show selenium可查看当前的版本
方法二:直接下载selenium包:
selenium下载网址
Pychome安装selenium如果出现无法安装,参考以下博客
解决Pycharm无法使用已经安装Selenium的问题
3.禁止谷歌浏览器自动更新
搜索本地:管理工具-服务-Google自动更新服务-选择禁止

安装浏览器对应的驱动driver
我这里用的是谷歌,选择对应的驱动版本
驱动的下载地址如下:
http://chromedriver.storage.googleapis.com/index.html


win32、win64的都下载win32.zip的
将下载的chromedriver进行解压,并将文件复制或移动到,浏览器快捷方式所在目录。
环境变量配置
1.Python环境配置
2.chromedriver环境配置
3.pychrome的python环境指向自己电脑安装好的python
注意:将下载好的chromewebdriver.exe驱动放在Python的安装路径下的Scripts里面,同时将Scripts路径添加到PATH中,这样每次运行python的时候就会自动加载驱动
代码实现
#已经准备环境:webdriver:Google已经安装好;环境变量配置好;pip install selenium; #selenium是一个包,包有很多对象,对象有属性,方法。 from selenium import webdriver browser=webdriver.Chrome()#打开浏览器 url="https://news.qq.com/zt2020/page/feiyan.htm#/global?nojump=1"#获取数据的地址 #请求浏览器内容:请求方式:get,post,token browser.get(url) #css选择器,id选择器:#开头,class选择器:.开头,标签选择器:p,span,div。 coronavirus_countent=browser.find_element_by_class_name('d')#定位到class选择器d这个内容 print(coronavirus_countent)#查看内容,session,一种缓存机制,通过浏览器解析,然后缓存的内容 # <selenium.webdriver.remote.webelement.WebElement (session="a1aa22161543b44f599e97b35dbc1ac5", element="fe645993-43cb-46cf-83a7-2488dd3d838a")> print(coronavirus_countent.text)#查看当前css.class中的d的内容 coronavirus_time=browser.find_element_by_class_name('ml')#定位到class选择器d这个内容 print(coronavirus_time.text) coronavirus_data=browser.find_element_by_class_name('nowConfirm')#定位到class选择器d这个内容 print("=======") print(coronavirus_data.text) print("=====找nowConfirm下面的字内容") coronavirus_sub=coronavirus_data.find_element_by_class_name('addnum') print(coronavirus_sub.text) browser.quit()
到此这篇关于python+selenium+chromedriver实现爬虫示例代码的文章就介绍到这了,更多相关python selenium chromedriver 爬虫内容请搜索小牛知识库以前的文章或继续浏览下面的相关文章希望大家以后多多支持小牛知识库!
-
本文向大家介绍PHP实现爬虫爬取图片代码实例,包括了PHP实现爬虫爬取图片代码实例的使用技巧和注意事项,需要的朋友参考一下 文字信息 我们尝试获取表的信息,这里,我们就用某校的课表来代替: 接下来我们就上代码: a.php 然后咱们就运行一下: 成功获取到课表; 图片获取 绝对链接 我们以百度图库的首页为例 b.php 然后,我们就获得了下面的页面: 相对链接 百度图库的图片的链接大部
-
本文向大家介绍python实现简单爬虫功能的示例,包括了python实现简单爬虫功能的示例的使用技巧和注意事项,需要的朋友参考一下 在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材。 我们最常规的做法就是通过鼠标右键,选择另存为。但有些图片鼠标右键的时候并没有另存为选项,还有办法就通过就是通过截图工具截取下来,但这样
-
EasySwoole利用redis队列+定时器+task进程实现的一个多进程爬虫。直接上代码 添加Redis配置信息 修改配置文件,添加Redis配置 "REDIS"=>array( "HOST"=>'', "PORT"=>6379, "AUTH"=>"" ) 封装Redis namespace AppUtilityDb; use ConfConfig; class Re
-
本文向大家介绍Python爬虫爬取美剧网站的实现代码,包括了Python爬虫爬取美剧网站的实现代码的使用技巧和注意事项,需要的朋友参考一下 一直有爱看美剧的习惯,一方面锻炼一下英语听力,一方面打发一下时间。之前是能在视频网站上面在线看的,可是自从广电总局的限制令之后,进口的美剧英剧等貌似就不在像以前一样同步更新了。但是,作为一个宅diao的我又怎甘心没剧追呢,所以网上随便查了一下就找到一个能用迅雷
-
本文向大家介绍python 实现一个贴吧图片爬虫的示例,包括了python 实现一个贴吧图片爬虫的示例的使用技巧和注意事项,需要的朋友参考一下 今天没事回家写了个贴吧图片下载程序,工具用的是PyCharm,这个工具很实用,开始用的Eclipse,但是再使用类库或者其它方便并不实用,所以最后下了个专业开发python程序的工具,开发环境是Python2,因为大学时自学的是python2 第一步:就是
-
本文向大家介绍node.js实现博客小爬虫的实例代码,包括了node.js实现博客小爬虫的实例代码的使用技巧和注意事项,需要的朋友参考一下 前言 爬虫,是一种自动获取网页内容的程序。是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上就是针对爬虫而做出的优化。 这篇文章介绍的是利用node.js实现博客小爬虫,核心的注释我都标注好了,可以自行理解,只需修改url和按照要趴的博客内部dom构造改一下