
python 实现一个贴吧图片爬虫的示例

今天没事回家写了个贴吧图片下载程序,工具用的是PyCharm,这个工具很实用,开始用的Eclipse,但是再使用类库或者其它方便并不实用,所以最后下了个专业开发python程序的工具,开发环境是Python2,因为大学时自学的是python2
第一步:就是打开cmd命令,输入pip install lxml
如图
第二步:下载一个chrome插件:专门用来将html文件转为xml用xpth技术定位
在页面按下Ctrl+Shift+X即可打开插件进行页面分析
如下图
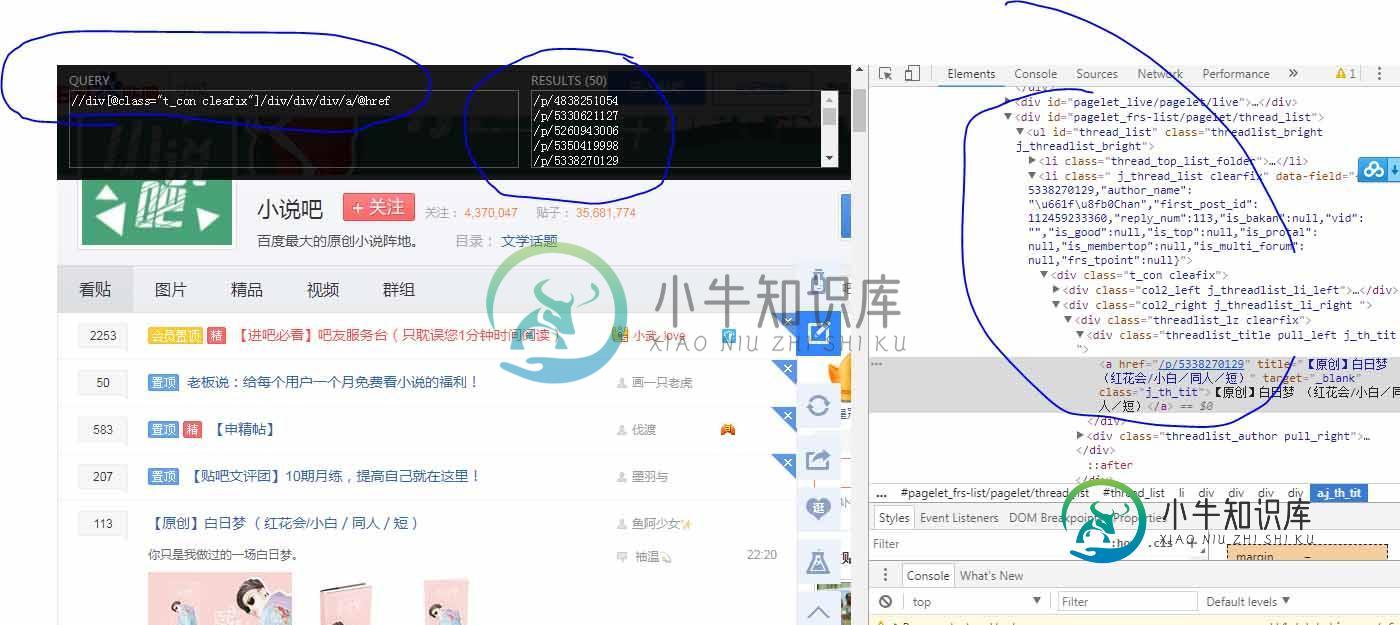
图中的黑色方框左边填写xpth,右边会返回对应的结果,可以看到当前页面的帖子全部抓取到了。xpth具体怎么写要根据右边的检查元素来具体分析,寻找规律,每个网站的方式不一样,但是细心寻找可以找到相同的规律。
找到规律并能匹配上开始写代码了:go
至于代码我对于每行尽量标上注释,方便大家理解
# -*- coding:utf-8 -*-
import urllib
import urllib2
from lxml import etree
def loadPage(url):
"""
作用:根据url发送请求,获取服务器响应文件
url: 需要爬取的url地址
"""
#print url
#美女
# headers = {"User-Agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"}
request = urllib2.Request(url)
html = urllib2.urlopen(request).read()
# 解析HTML文档为HTML DOM模型
content = etree.HTML(html)
#print content
# 返回所有匹配成功的列表集合
link_list = content.xpath('//div[@class="t_con cleafix"]/div/div/div/a/@href')
#link_list = content.xpath('//a[@class="j_th_tit"]/@href')
for link in link_list:
fulllink = "http://tieba.baidu.com" + link
# 组合为每个帖子的链接
#print link
loadImage(fulllink)
# 取出每个帖子里的每个图片连接
def loadImage(link):
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
request = urllib2.Request(link, headers = headers)
html = urllib2.urlopen(request).read()
# 解析
content = etree.HTML(html)
# 取出帖子里每层层主发送的图片连接集合
#link_list = content.xpath('//img[@class="BDE_Image"]/@src')
#link_list = content.xpath('//div[@class="post_bubble_middle"]')
link_list = content.xpath('//img[@class="BDE_Image"]/@src')
# 取出每个图片的连接
for link in link_list:
print link
writeImage(link)
def writeImage(link):
"""
作用:将html内容写入到本地
link:图片连接
"""
#print "正在保存 " + filename
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 文件写入
request = urllib2.Request(link, headers = headers)
# 图片原始数据
image = urllib2.urlopen(request).read()
# 取出连接后10位做为文件名
filename = link[-10:]
# 写入到本地磁盘文件内
with open("d:\image\\"+filename, "wb") as f:
f.write(image)
print "已经成功下载 "+ filename
def tiebaSpider(url, beginPage, endPage):
"""
作用:贴吧爬虫调度器,负责组合处理每个页面的url
url : 贴吧url的前部分
beginPage : 起始页
endPage : 结束页
"""
for page in range(beginPage, endPage + 1):
pn = (page - 1) * 50
filename = "第" + str(page) + "页.html"
fullurl = url + "&pn=" + str(pn)
print fullurl
loadPage(fullurl)
#print html
print "谢谢使用"
if __name__ == "__main__":
kw = raw_input("请输入需要爬取的贴吧名:")
beginPage = int(raw_input("请输入起始页:"))
endPage = int(raw_input("请输入结束页:"))
url = "http://tieba.baidu.com/f?"
key = urllib.urlencode({"kw": kw})
fullurl = url + key
tiebaSpider(fullurl, beginPage, endPage)
运行:
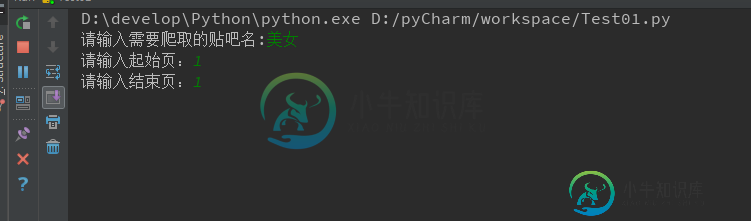

可以看到程序成功运行了,当然我自己的过程并不是一帆风顺,代码仅供参考
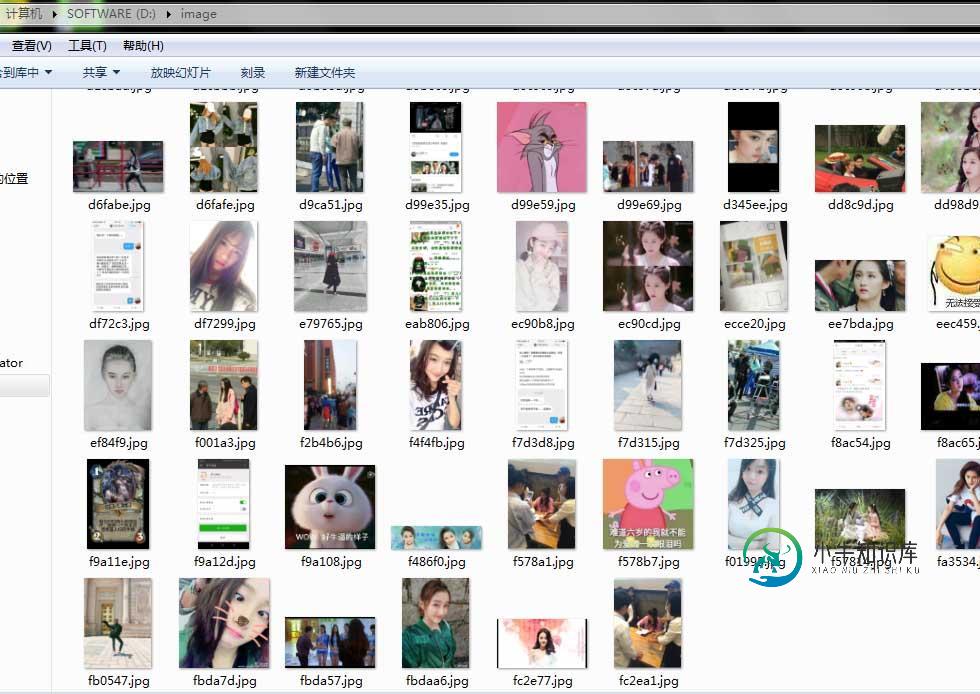
以上这篇python 实现一个贴吧图片爬虫的示例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
本文向大家介绍Python实现爬取百度贴吧帖子所有楼层图片的爬虫示例,包括了Python实现爬取百度贴吧帖子所有楼层图片的爬虫示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python实现爬取百度贴吧帖子所有楼层图片的爬虫。分享给大家供大家参考,具体如下: 下载百度贴吧帖子图片,好好看 python2.7版本: PS:这里再为大家提供2款非常方便的正则表达式工具供大家参考使用: Ja
-
本文向大家介绍python实现爬虫下载美女图片,包括了python实现爬虫下载美女图片的使用技巧和注意事项,需要的朋友参考一下 本次爬取的贴吧是百度的美女吧,给广大男同胞们一些激励 在爬取之前需要在浏览器先登录百度贴吧的帐号,各位也可以在代码中使用post提交或者加入cookie 爬行地址:http://tieba.baidu.com/f?kw=%E7%BE%8E%E5%A5%B3&ie=utf-
-
本文向大家介绍PHP实现爬虫爬取图片代码实例,包括了PHP实现爬虫爬取图片代码实例的使用技巧和注意事项,需要的朋友参考一下 文字信息 我们尝试获取表的信息,这里,我们就用某校的课表来代替: 接下来我们就上代码: a.php 然后咱们就运行一下: 成功获取到课表; 图片获取 绝对链接 我们以百度图库的首页为例 b.php 然后,我们就获得了下面的页面: 相对链接 百度图库的图片的链接大部
-
本文向大家介绍Python爬虫实现百度图片自动下载,包括了Python爬虫实现百度图片自动下载的使用技巧和注意事项,需要的朋友参考一下 制作爬虫的步骤 制作一个爬虫一般分以下几个步骤: 分析需求分析网页源代码,配合开发者工具编写正则表达式或者XPath表达式正式编写 python 爬虫代码 效果预览 运行效果如下: 存放图片的文件夹: 需求分析 我们的爬虫至少要实现两个功能:一是搜索图片,二是自动
-
本文向大家介绍python爬虫爬取图片的简单代码,包括了python爬虫爬取图片的简单代码的使用技巧和注意事项,需要的朋友参考一下 Python是很好的爬虫工具不用再说了,它可以满足我们爬取网络内容的需求,那最简单的爬取网络上的图片,可以通过很简单的方法实现。只需导入正则表达式模块,并利用spider原理通过使用定义函数的方法可以轻松的实现爬取图片的需求。 1、spider原理 spider就是定
-
本文向大家介绍python实现简单爬虫功能的示例,包括了python实现简单爬虫功能的示例的使用技巧和注意事项,需要的朋友参考一下 在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材。 我们最常规的做法就是通过鼠标右键,选择另存为。但有些图片鼠标右键的时候并没有另存为选项,还有办法就通过就是通过截图工具截取下来,但这样