
Python实现爬取百度贴吧帖子所有楼层图片的爬虫示例

本文实例讲述了Python实现爬取百度贴吧帖子所有楼层图片的爬虫。分享给大家供大家参考,具体如下:
下载百度贴吧帖子图片,好好看
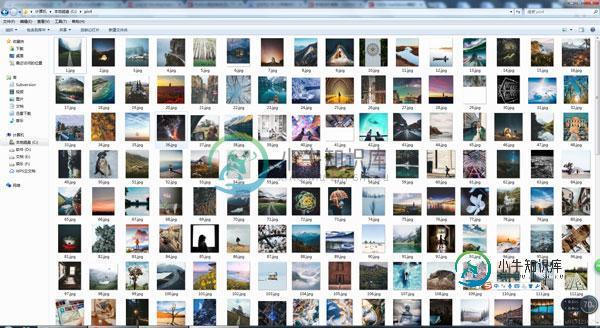
python2.7版本:
#coding=utf-8
import re
import requests
import urllib
from bs4 import BeautifulSoup
import time
time1=time.time()
def getHtml(url):
page = requests.get(url)
html =page.text
return html
def getImg(html):
soup = BeautifulSoup(html, 'html.parser')
img_info = soup.find_all('img', class_='BDE_Image')
global index
for index,img in enumerate(img_info,index+1):
print ("正在下载第{}张图片".format(index))
urllib.urlretrieve(img.get("src"),'C:/pic4/%s.jpg' % index)
def getMaxPage(url):
html = getHtml(url)
reg = re.compile(r'max-page="(\d+)"')
page = re.findall(reg,html)
page = int(page[0])
return page
if __name__=='__main__':
url = "https://tieba.baidu.com/p/5113603072"
page = getMaxPage(url)
index = 0
for i in range(1,page):
url = "%s%s" % ("https://tieba.baidu.com/p/5113603072?pn=",str(i))
html = getHtml(url)
getImg(html)
print ("OK!All DownLoad!")
time2=time.time()
print u'总共耗时:' + str(time2 - time1) + 's'
PS:这里再为大家提供2款非常方便的正则表达式工具供大家参考使用:
JavaScript正则表达式在线测试工具:
http://tools.jb51.net/regex/javascript
正则表达式在线生成工具:
http://tools.jb51.net/regex/create_reg
更多关于Python相关内容可查看本站专题:《Python Socket编程技巧总结》、《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。
-
本文向大家介绍python 实现一个贴吧图片爬虫的示例,包括了python 实现一个贴吧图片爬虫的示例的使用技巧和注意事项,需要的朋友参考一下 今天没事回家写了个贴吧图片下载程序,工具用的是PyCharm,这个工具很实用,开始用的Eclipse,但是再使用类库或者其它方便并不实用,所以最后下了个专业开发python程序的工具,开发环境是Python2,因为大学时自学的是python2 第一步:就是
-
本文向大家介绍Python爬虫:通过关键字爬取百度图片,包括了Python爬虫:通过关键字爬取百度图片的使用技巧和注意事项,需要的朋友参考一下 使用工具:Python2.7 点我下载 scrapy框架 sublime text3 一。搭建python(Windows版本) 1.安装python2.7 ---然后在cmd当中输入python,界面如下则安装成功 2.集成Scrapy框架----输
-
本文向大家介绍Python爬虫实现百度图片自动下载,包括了Python爬虫实现百度图片自动下载的使用技巧和注意事项,需要的朋友参考一下 制作爬虫的步骤 制作一个爬虫一般分以下几个步骤: 分析需求分析网页源代码,配合开发者工具编写正则表达式或者XPath表达式正式编写 python 爬虫代码 效果预览 运行效果如下: 存放图片的文件夹: 需求分析 我们的爬虫至少要实现两个功能:一是搜索图片,二是自动
-
本文向大家介绍python爬虫之爬取百度音乐的实现方法,包括了python爬虫之爬取百度音乐的实现方法的使用技巧和注意事项,需要的朋友参考一下 在上次的爬虫中,抓取的数据主要用到的是第三方的Beautifulsoup库,然后对每一个具体的数据在网页中的selecter来找到它,每一个类别便有一个select方法。对网页有过接触的都知道很多有用的数据都放在一个共同的父节点上,只是其子节点不同。在上次
-
本文向大家介绍PHP实现爬虫爬取图片代码实例,包括了PHP实现爬虫爬取图片代码实例的使用技巧和注意事项,需要的朋友参考一下 文字信息 我们尝试获取表的信息,这里,我们就用某校的课表来代替: 接下来我们就上代码: a.php 然后咱们就运行一下: 成功获取到课表; 图片获取 绝对链接 我们以百度图库的首页为例 b.php 然后,我们就获得了下面的页面: 相对链接 百度图库的图片的链接大部
-
本文向大家介绍python2爬取百度贴吧指定关键字和图片代码实例,包括了python2爬取百度贴吧指定关键字和图片代码实例的使用技巧和注意事项,需要的朋友参考一下 目的:在百度贴吧输入关键字和要查找的起始结束页,获取帖子里面楼主所发的图片 思路: 获取分页里面的帖子链接列表 获取帖子里面楼主所发的图片链接列表 保存图片到本地 注意事项: 问题:在谷歌浏览器使用xpath helper插件时有匹配结