
PHP实现爬虫爬取图片代码实例

文字信息
我们尝试获取表的信息,这里,我们就用某校的课表来代替:

接下来我们就上代码:
a.php
<?php
header( "Content-type:text/html;Charset=utf-8" );
$ch = curl_init();
$url ="表的链接";
curl_setopt ( $ch , CURLOPT_USERAGENT ,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.113 Safari/537.36" );
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$content=curl_exec($ch);
preg_match_all("/<td rowspan=\"\d\">(.*?)<\/td>\n<td rowspan=\"\d\">(.*?)<\/td><td rowspan=\"\d\" align=\"\w+\">(.*?)<\/td><td rowspan=\"\d\" align=\"\w+\">(.*?)<\/td><td>(.*?)<\/td>\n<td>(.*?)<\/td><td>(.*?)<\/td>/",$content,$matchs,PREG_SET_ORDER);
//匹配该表所用的正则
var_dump($matchs);
然后咱们就运行一下:

成功获取到课表;
图片获取
绝对链接
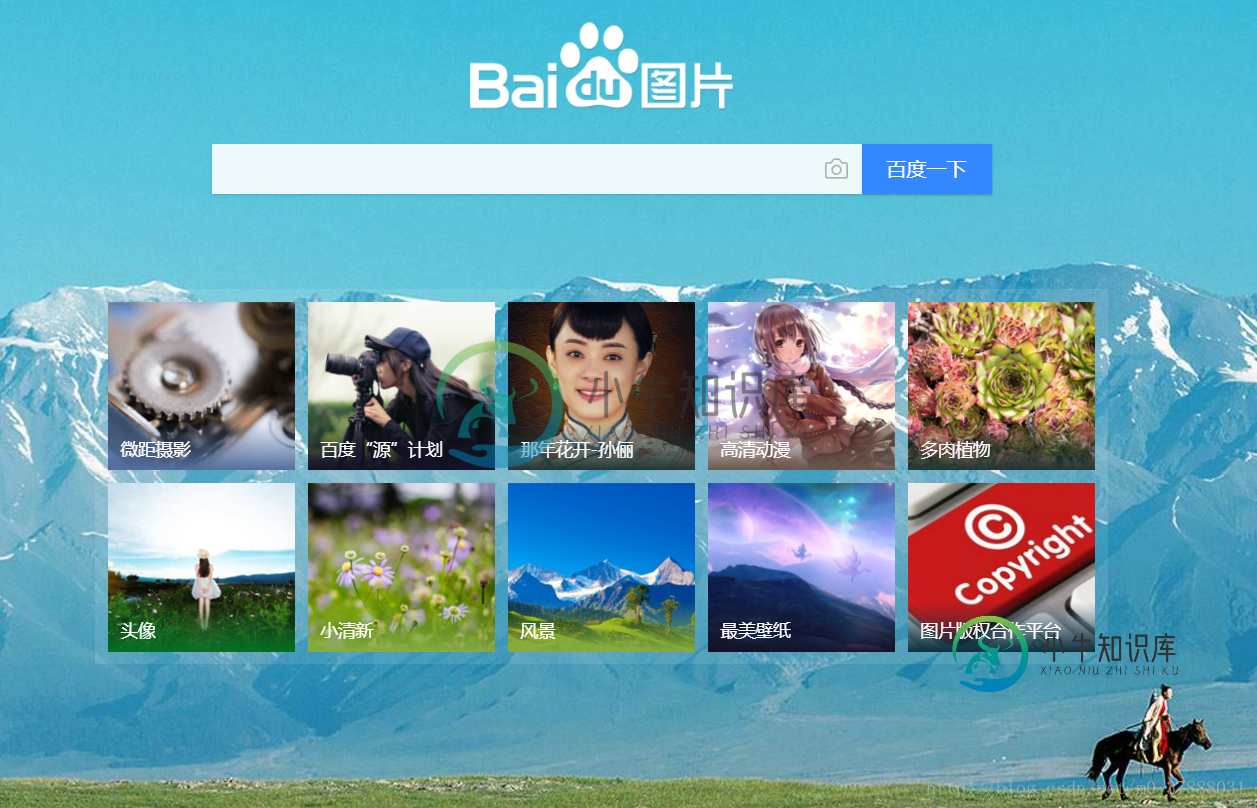
我们以百度图库的首页为例
b.php
<?php
header( "Content-type:text/html;Charset=utf-8" );
$ch = curl_init();
$url="http://image.baidu.com/";
curl_setopt ($ch , CURLOPT_USERAGENT ,"Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.113 Safari/537.36" );
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$content=curl_exec($ch);
$string=file_get_contents($url);
preg_match_all("/<img([^>]*)\s*src=('|\")([^'\"]+)('|\")/", $string,$matches);
$new_arr=array_unique($matches[3]);
foreach($new_arr as $key) {
echo "<img src=$key>";
}
然后,我们就获得了下面的页面:

相对链接
百度图库的图片的链接大部分是绝对链接,那么当我们遇到网页图片为相对链接的时候,我们该怎么处理呢?其实很简单,我们只需要将循环那部分改为
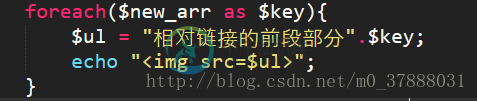
那么我们就可以同样在浏览器中输出图片了;
到此这篇关于PHP实现爬虫爬取图片代码实例的文章就介绍到这了,更多相关PHP实现爬虫内容请搜索小牛知识库以前的文章或继续浏览下面的相关文章希望大家以后多多支持小牛知识库!
-
本文向大家介绍python爬虫爬取图片的简单代码,包括了python爬虫爬取图片的简单代码的使用技巧和注意事项,需要的朋友参考一下 Python是很好的爬虫工具不用再说了,它可以满足我们爬取网络内容的需求,那最简单的爬取网络上的图片,可以通过很简单的方法实现。只需导入正则表达式模块,并利用spider原理通过使用定义函数的方法可以轻松的实现爬取图片的需求。 1、spider原理 spider就是定
-
本文向大家介绍Python爬虫爬取美剧网站的实现代码,包括了Python爬虫爬取美剧网站的实现代码的使用技巧和注意事项,需要的朋友参考一下 一直有爱看美剧的习惯,一方面锻炼一下英语听力,一方面打发一下时间。之前是能在视频网站上面在线看的,可是自从广电总局的限制令之后,进口的美剧英剧等貌似就不在像以前一样同步更新了。但是,作为一个宅diao的我又怎甘心没剧追呢,所以网上随便查了一下就找到一个能用迅雷
-
本文向大家介绍Python爬虫抓取指定网页图片代码实例,包括了Python爬虫抓取指定网页图片代码实例的使用技巧和注意事项,需要的朋友参考一下 想要爬取指定网页中的图片主要需要以下三个步骤: (1)指定网站链接,抓取该网站的源代码(如果使用google浏览器就是按下鼠标右键 -> Inspect-> Elements 中的 html 内容) (2)根据你要抓取的内容设置正则表达式以匹配要抓取的内容
-
本文向大家介绍PHP代码实现爬虫记录——超管用,包括了PHP代码实现爬虫记录——超管用的使用技巧和注意事项,需要的朋友参考一下 实现爬虫记录本文从创建crawler 数据库,robot.php记录来访的爬虫从而将信息插入数据库crawler,然后从数据库中就可以获得所有的爬虫信息。实现代码具体如下: 数据库设计 以下文件 robot.php 记录来访的爬虫,并将信息写入数据库: 成功了,现在访问数
-
25.1 数据库的准备: 启动MySQL和Redis数据库 在MySQL数据库中创建数据库:doubandb,并进入数据库中创建books数据表 CREATE TABLE `books` ( `id` bigint(20) unsigned NOT NULL COMMENT 'ID号',
-
本文向大家介绍Python爬取知乎图片代码实现解析,包括了Python爬取知乎图片代码实现解析的使用技巧和注意事项,需要的朋友参考一下 首先,需要获取任意知乎的问题,只需要你输入问题的ID,就可以获取相关的页面信息,比如最重要的合计有多少人回答问题。 问题ID为如下标红数字 编写代码,下面的代码用来检测用户输入的是否是正确的ID,并且通过拼接URL去获取该问题下面合计有多少答案。 完善图片下载部分