
nodeJs爬虫获取数据简单实现代码

本文实例为大家分享了nodeJs爬虫获取数据代码,供大家参考,具体内容如下
var http=require('http'); var cheerio=require('cheerio');//页面获取到的数据模块 var url='http://www.jcpeixun.com/lesson/1512/'; function filterData(html){ /*所要获取到的目标数组 var courseData=[{ chapterTitle:"", videosData:{ videoTitle:title, videoId:id, videoPrice:price } }] */ var $=cheerio.load(html); var courseData=[]; var chapters=$(".list-collapse"); chapters.each(function(item){ var chapterTitle=$(this).find(".collapse-head").find("label").text(); var videos=$(this).find(".listview5").children("li"); var chaptersData={ chaptersTitle:chapterTitle, videosData:[] } videos.each(function(item){ var videoTitle=$(this).find(".ml10").attr('data-lesson-name'); var videoId=$(this).find(".ml10").attr('data-lesson-id'); var vadeoPrice=$(this).find(".colblue").text(); chaptersData.videosData.push({ title:videoTitle, id:videoId, price:vadeoPrice }) }) courseData.push(chaptersData) }) return courseData } function printCourseInfo(courseData){ courseData.forEach(function(item){ console.log(item.chaptersTitle+'\n'); item.videosData.forEach(function(item){ console.log(item.title+'【'+item.id+'】'+item.price+'\n') }) }) } http.get(url,function(res){ html=""; res.on("data",function(data){ html+=data }) res.on('end',function(){ var courseData=filterData(html); printCourseInfo(courseData) }) })
效果图:
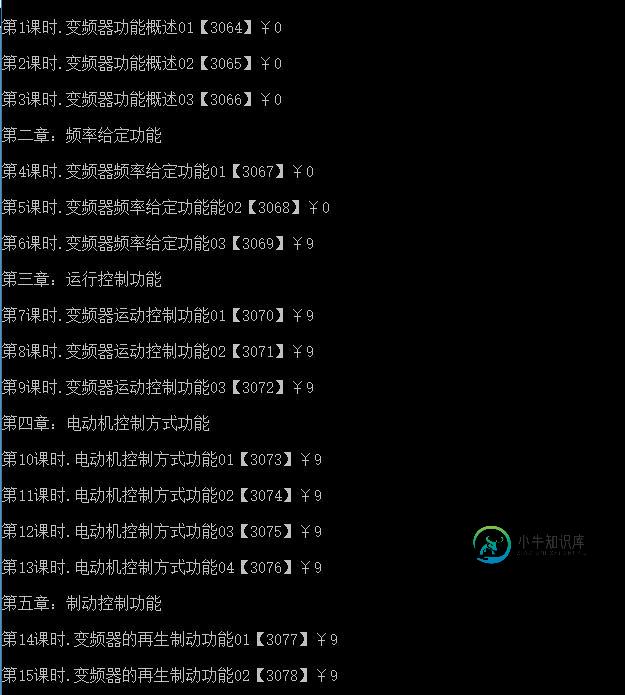
以上就是nodeJs爬虫获取数据的相关代码,希望对大家的学习有所帮助。
-
本文向大家介绍Nodejs实现爬虫抓取数据实例解析,包括了Nodejs实现爬虫抓取数据实例解析的使用技巧和注意事项,需要的朋友参考一下 开始之前请先确保自己安装了Node.js环境,如果没有安装,大家可以到呐喊教程下载安装。 1.在项目文件夹安装两个必须的依赖包 superagent 是一个轻量的,渐进式的ajax api,可读性好,学习曲线低,内部依赖nodejs原生的请求api,适用于node
-
本文向大家介绍python爬虫爬取图片的简单代码,包括了python爬虫爬取图片的简单代码的使用技巧和注意事项,需要的朋友参考一下 Python是很好的爬虫工具不用再说了,它可以满足我们爬取网络内容的需求,那最简单的爬取网络上的图片,可以通过很简单的方法实现。只需导入正则表达式模块,并利用spider原理通过使用定义函数的方法可以轻松的实现爬取图片的需求。 1、spider原理 spider就是定
-
主要内容:1 Swing实现简单爬虫1 Swing实现简单爬虫 我们可以借助网络,带有事件处理的Swing开发Java中的URL源代码生成器。让我们看一下用Java创建URL源代码生成器的代码。 核心代码: 让我们看一下生成URL源代码的代码。 输出结果为:
-
本文向大家介绍Python实现爬取知乎神回复简单爬虫代码分享,包括了Python实现爬取知乎神回复简单爬虫代码分享的使用技巧和注意事项,需要的朋友参考一下 看知乎的时候发现了一个 “如何正确地吐槽” 收藏夹,里面的一些神回复实在很搞笑,但是一页一页地看又有点麻烦,而且每次都要打开网页,于是想如果全部爬下来到一个文件里面,是不是看起来很爽,并且随时可以看到全部的,于是就开始动手了。 工具 1.Pyt
-
本文向大家介绍NodeJs实现简单的爬虫功能案例分析,包括了NodeJs实现简单的爬虫功能案例分析的使用技巧和注意事项,需要的朋友参考一下 1.爬虫:爬虫,是一种按照一定的规则,自动地抓取网页信息的程序或者脚本;利用NodeJS实现一个简单的爬虫案例,爬取Boss直聘网站的web前端相关的招聘信息,以广州地区为例; 2.脚本所用到的nodejs模块 express 用来搭建一个服务,将结果
-
本文向大家介绍PHP实现爬虫爬取图片代码实例,包括了PHP实现爬虫爬取图片代码实例的使用技巧和注意事项,需要的朋友参考一下 文字信息 我们尝试获取表的信息,这里,我们就用某校的课表来代替: 接下来我们就上代码: a.php 然后咱们就运行一下: 成功获取到课表; 图片获取 绝对链接 我们以百度图库的首页为例 b.php 然后,我们就获得了下面的页面: 相对链接 百度图库的图片的链接大部