
Python爬虫抓取指定网页图片代码实例

想要爬取指定网页中的图片主要需要以下三个步骤:
(1)指定网站链接,抓取该网站的源代码(如果使用google浏览器就是按下鼠标右键 -> Inspect-> Elements 中的 html 内容)
(2)根据你要抓取的内容设置正则表达式以匹配要抓取的内容
(3)设置循环列表,重复抓取和保存内容
以下介绍了两种方法实现抓取指定网页中图片
(1)方法一:使用正则表达式过滤抓到的 html 内容字符串
# 第一个简单的爬取图片的程序
import urllib.request # python自带的爬操作url的库
import re # 正则表达式
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36'
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode('UTF-8')
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组
# imageList = re.findall(r'(https:[^\s]*?(png))"', page)
imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page)
x = 0
# 循环列表
for imageUrl in imageList:
try:
print('正在下载: %s' % imageUrl[0])
# 这个image文件夹需要先创建好才能看到结果
image_save_path = './image/%d.png' % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(imageUrl[0], image_save_path)
x = x + 1
except:
continue
pass
if __name__ == '__main__':
# 指定要爬取的网站
url = "https://www.cnblogs.com/ttweixiao-IT-program/p/13324826.html"
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
# print(page)
注意,代码中需要修改的就是imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page) 这一块内容,如何设计正则表达式需要根据你想要抓取的内容设置。我的设计来源如下:
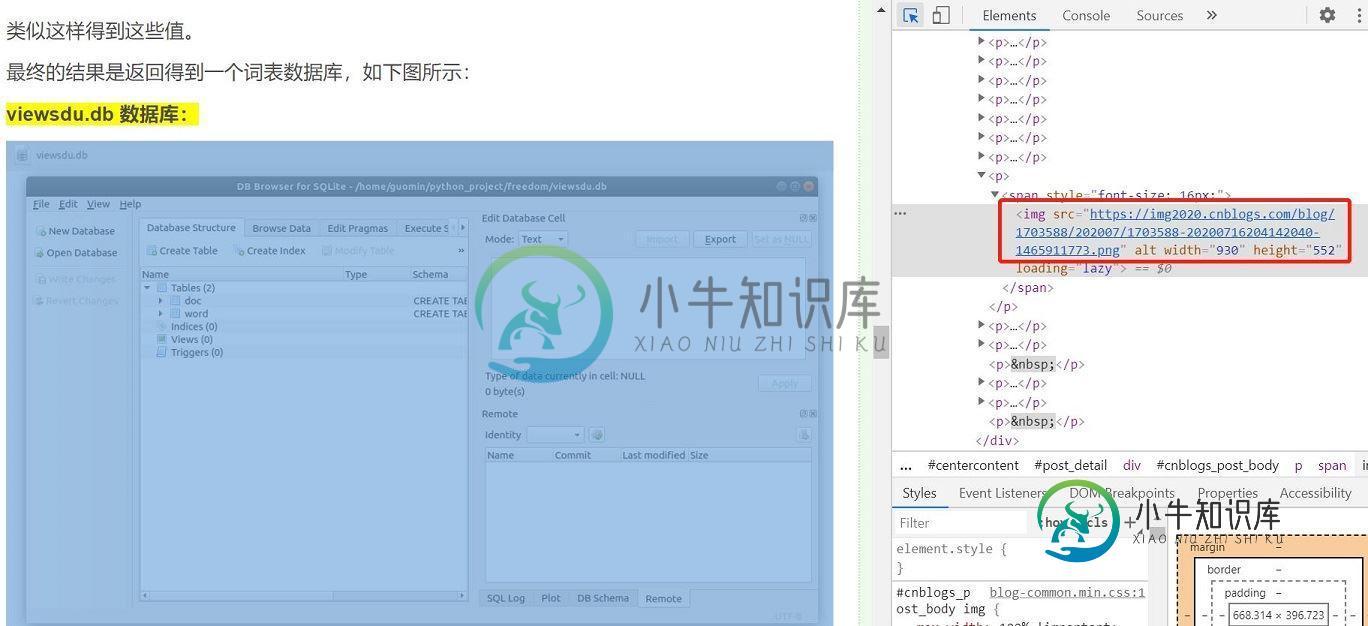
可以看到,因为这个网页上的图片都是 png 格式,所以写成imageList = re.findall(r'(https:[^\s]*?(png))"', page)也是可以的。
(2)方法二:使用 BeautifulSoup 库解析 html 网页
from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具 import urllib # python自带的爬操作url的库 # 该方法传入url,返回url的html的源代码 def getHtmlCode(url): # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求 headers = { 'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \ AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36' } # 将headers头部添加到url,模拟浏览器访问 url = urllib.request.Request(url, headers=headers) # 将url页面的源代码保存成字符串 page = urllib.request.urlopen(url).read() # 字符串转码 page = page.decode('UTF-8') return page # 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机 def getImage(page): # 按照html格式解析页面 soup = BeautifulSoup(page, 'html.parser') # 格式化输出DOM树的内容 print(soup.prettify()) # 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是<img src="..." alt=".." /> imgList = soup.find_all('img') x = 0 # 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片 for imgUrl in imgList[1:]: print('正在下载: %s ' % imgUrl.get('src')) # 得到scr的内容,这里返回的就是Url字符串链接,如'https://img2020.cnblogs.com/blog/1703588/202007/1703588-20200716203143042-623499171.png' image_url = imgUrl.get('src') # 这个image文件夹需要先创建好才能看到结果 image_save_path = './image/%d.png' % x # 下载图片并且保存到指定文件夹中 urllib.request.urlretrieve(image_url, image_save_path) x = x + 1 if __name__ == '__main__': # 指定要爬取的网站 url = 'https://www.cnblogs.com/ttweixiao-IT-program/p/13324826.html' # 得到该网站的源代码 page = getHtmlCode(url) # 爬取该网站的图片并且保存 getImage(page)
这两种方法各有利弊,我觉得可以灵活结合使用这两种方法,比如先使用方法2中指定标签的方法缩小要寻找的内容范围,然后再使用正则表达式匹配想要的内容,这样做起来更加简洁明了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
主要内容:导入所需模块,拼接URL地址,向URL发送请求,保存为本地文件,函数式编程修改程序本节讲解第一个 Python 爬虫实战案例:抓取您想要的网页,并将其保存至本地计算机。 首先我们对要编写的爬虫程序进行简单地分析,该程序可分为以下三个部分: 拼接 url 地址 发送请求 将照片保存至本地 明确逻辑后,我们就可以正式编写爬虫程序了。 导入所需模块 本节内容使用 urllib 库来编写爬虫,下面导入程序所用模块: 拼接URL地址 定义 URL 变量,拼接 url 地址。代码如下所示:
-
本文向大家介绍PHP实现爬虫爬取图片代码实例,包括了PHP实现爬虫爬取图片代码实例的使用技巧和注意事项,需要的朋友参考一下 文字信息 我们尝试获取表的信息,这里,我们就用某校的课表来代替: 接下来我们就上代码: a.php 然后咱们就运行一下: 成功获取到课表; 图片获取 绝对链接 我们以百度图库的首页为例 b.php 然后,我们就获得了下面的页面: 相对链接 百度图库的图片的链接大部
-
本文向大家介绍python爬虫爬取图片的简单代码,包括了python爬虫爬取图片的简单代码的使用技巧和注意事项,需要的朋友参考一下 Python是很好的爬虫工具不用再说了,它可以满足我们爬取网络内容的需求,那最简单的爬取网络上的图片,可以通过很简单的方法实现。只需导入正则表达式模块,并利用spider原理通过使用定义函数的方法可以轻松的实现爬取图片的需求。 1、spider原理 spider就是定
-
本文向大家介绍Python爬虫学习之获取指定网页源码,包括了Python爬虫学习之获取指定网页源码的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了Python获取指定网页源码的具体代码,供大家参考,具体内容如下 1、任务简介 前段时间一直在学习Python基础知识,故未更新博客,近段时间学习了一些关于爬虫的知识,我会分为多篇博客对所学知识进行更新,今天分享的是获取指定网页源码的方法,
-
本文向大家介绍简单的Python抓taobao图片爬虫,包括了简单的Python抓taobao图片爬虫的使用技巧和注意事项,需要的朋友参考一下 写了一个抓taobao图片的爬虫,全是用if,for,while写的,比较简陋,入门作品。 从网页http://mm.taobao.com/json/request_top_list.htm?type=0&page=中提取taobao模特的照片。
-
本文向大家介绍Python爬虫爬取美剧网站的实现代码,包括了Python爬虫爬取美剧网站的实现代码的使用技巧和注意事项,需要的朋友参考一下 一直有爱看美剧的习惯,一方面锻炼一下英语听力,一方面打发一下时间。之前是能在视频网站上面在线看的,可是自从广电总局的限制令之后,进口的美剧英剧等貌似就不在像以前一样同步更新了。但是,作为一个宅diao的我又怎甘心没剧追呢,所以网上随便查了一下就找到一个能用迅雷