
Python爬虫实现百度图片自动下载

制作爬虫的步骤
制作一个爬虫一般分以下几个步骤:
分析需求分析网页源代码,配合开发者工具编写正则表达式或者XPath表达式正式编写 python 爬虫代码 效果预览
运行效果如下:
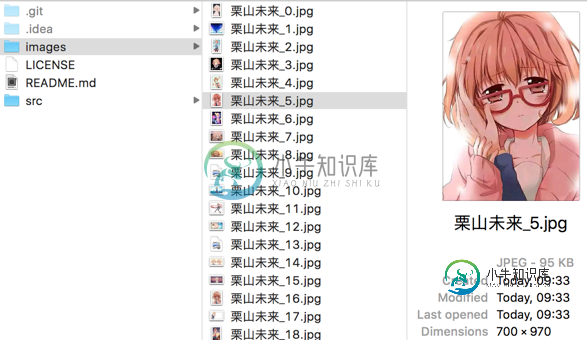
存放图片的文件夹:
需求分析
我们的爬虫至少要实现两个功能:一是搜索图片,二是自动下载。
搜索图片:最容易想到的是爬百度图片的结果,我们就上百度图片看看:

随便搜索几个关键字,可以看到已经搜索出来很多张图片:

分析网页
我们点击右键,查看源代码:
打开源代码之后,发现一堆源代码比较难找出我们想要的资源。
这个时候,就要用开发者工具!我们回到上一页面,调出开发者工具,我们需要用的是左上角那个东西:(鼠标跟随)。
然后选择你想看源代码的地方,就可以发现,下面的代码区自动定位到了相应的位置。如下图:
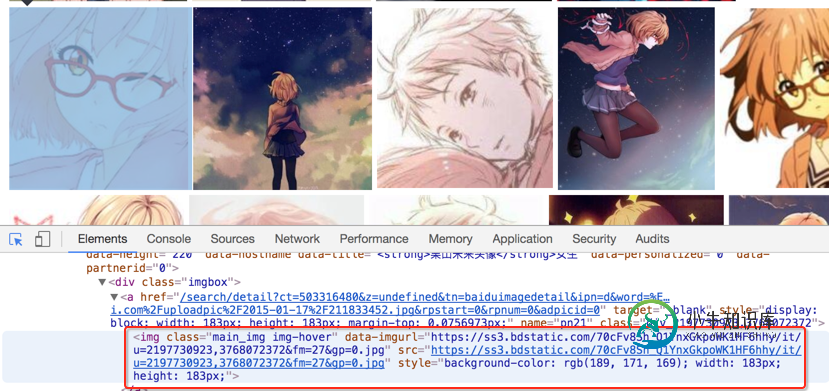

我们复制这个地址,然后到刚才的一堆源代码里搜索一下,发现了它的位置,但是这里我们又疑惑了,这个图片有这么多地址,到底用哪个呢?我们可以看到有thumbURL,middleURL,hoverURL,objURL

通过分析可以知道,前面两个是缩小的版本,hoverURL 是鼠标移动过后显示的版本,objURL 应该是我们需要的,可以分别打开这几个网址看看,发现 objURL 的那个最大最清晰。
找到了图片地址,接下来我们分析源代码。看看是不是所有的 objURL 都是图片。
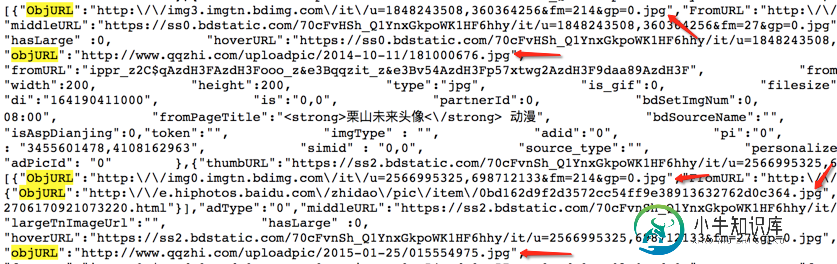
发现都是以.jpg格式结尾的图片。
编写正则表达式
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
编写爬虫代码
这里我们用了2个包,一个是正则,一个是 requests 包
#-*- coding:utf-8 -*- import re import requests
复制百度图片搜索的链接,传入 requests ,然后把正则表达式写好

url = 'https://image.baidu.com/search/index?tn=baiduimage&ie=utf-8&word=%E6%A0%97%E5%B1%B1%E6%9C%AA%E6%9D%A5%E5%A4%B4%E5%83%8F&ct=201326592&ic=0&lm=-1&width=&height=&v=index' html = requests.get(url).text pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
因为有很多张图片,所以要循环,我们打印出结果来看看,然后用 requests 获取网址,由于有些图片可能存在网址打不开的情况,所以加了10秒超时控制。
pic_url = re.findall('"objURL":"(.*?)",',html,re.S) i = 1 for each in pic_url:
print each
try:
pic= requests.get(each, timeout=10)
except requests.exceptions.ConnectionError: print('【错误】当前图片无法下载')
continue
接着就是把图片保存下来,我们事先建立好一个 images 目录,把图片都放进去,命名的时候,以数字命名。
dir = '../images/' + keyword + '_' + str(i) + '.jpg'
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
i += 1
完整的代码
# -*- coding:utf-8 -*-
import re
import requests
def dowmloadPic(html, keyword):
pic_url = re.findall('"objURL":"(.*?)",', html, re.S)
i = 1
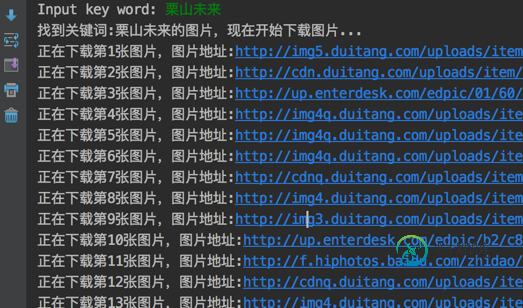
print('找到关键词:' + keyword + '的图片,现在开始下载图片...')
for each in pic_url:
print('正在下载第' + str(i) + '张图片,图片地址:' + str(each))
try:
pic = requests.get(each, timeout=10)
except requests.exceptions.ConnectionError:
print('【错误】当前图片无法下载')
continue
dir = '../images/' + keyword + '_' + str(i) + '.jpg'
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
i += 1
if __name__ == '__main__':
word = input("Input key word: ")
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&ct=201326592&v=flip'
result = requests.get(url)
dowmloadPic(result.text, word)
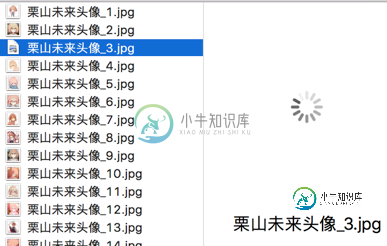

我们看到有的图片没显示出来,打开网址看,发现确实没了。

因为百度有些图片它缓存到百度的服务器上,所以我们在百度上还能看见它,但它的实际链接已经失效了。
总结
enjoy 我们的第一个图片下载爬虫吧!当然它不仅能下载百度的图片,依葫芦画瓢,你现在应该能做很多事情了,比如爬取头像,爬淘宝展示图等等。
完整代码已经放到Githut上 https://github.com/nnngu/BaiduImageDownload
-
本文向大家介绍python实现爬虫下载美女图片,包括了python实现爬虫下载美女图片的使用技巧和注意事项,需要的朋友参考一下 本次爬取的贴吧是百度的美女吧,给广大男同胞们一些激励 在爬取之前需要在浏览器先登录百度贴吧的帐号,各位也可以在代码中使用post提交或者加入cookie 爬行地址:http://tieba.baidu.com/f?kw=%E7%BE%8E%E5%A5%B3&ie=utf-
-
本文向大家介绍Python爬虫:通过关键字爬取百度图片,包括了Python爬虫:通过关键字爬取百度图片的使用技巧和注意事项,需要的朋友参考一下 使用工具:Python2.7 点我下载 scrapy框架 sublime text3 一。搭建python(Windows版本) 1.安装python2.7 ---然后在cmd当中输入python,界面如下则安装成功 2.集成Scrapy框架----输
-
本文向大家介绍Python实现爬取百度贴吧帖子所有楼层图片的爬虫示例,包括了Python实现爬取百度贴吧帖子所有楼层图片的爬虫示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python实现爬取百度贴吧帖子所有楼层图片的爬虫。分享给大家供大家参考,具体如下: 下载百度贴吧帖子图片,好好看 python2.7版本: PS:这里再为大家提供2款非常方便的正则表达式工具供大家参考使用: Ja
-
本文向大家介绍python爬虫之爬取百度音乐的实现方法,包括了python爬虫之爬取百度音乐的实现方法的使用技巧和注意事项,需要的朋友参考一下 在上次的爬虫中,抓取的数据主要用到的是第三方的Beautifulsoup库,然后对每一个具体的数据在网页中的selecter来找到它,每一个类别便有一个select方法。对网页有过接触的都知道很多有用的数据都放在一个共同的父节点上,只是其子节点不同。在上次
-
本文向大家介绍nodejs制作爬虫实现批量下载图片,包括了nodejs制作爬虫实现批量下载图片的使用技巧和注意事项,需要的朋友参考一下 今天想获取一大批猫的图片,然后就在360流浪器搜索框中输入 猫 ,然后点击图片。就看到了一大波猫的图片: http://image.so.com/i?q=%E7%8... ,我在想啊,要是审查元素,一张张手动下载,多麻烦,所以打算写程序来实现。不写不知道,一写发现
-
本文向大家介绍PHP实现爬虫爬取图片代码实例,包括了PHP实现爬虫爬取图片代码实例的使用技巧和注意事项,需要的朋友参考一下 文字信息 我们尝试获取表的信息,这里,我们就用某校的课表来代替: 接下来我们就上代码: a.php 然后咱们就运行一下: 成功获取到课表; 图片获取 绝对链接 我们以百度图库的首页为例 b.php 然后,我们就获得了下面的页面: 相对链接 百度图库的图片的链接大部