《爬虫》专题
-
15 爬虫与反爬虫
有的时候,当我们的爬虫程序完成了,并且在本地测试也没有问题,爬取了一段时间之后突然就发现报错无法抓取页面内容了。这个时候,我们很有可能是遇到了网站的反爬虫拦截。 我们知道,网站一方面想要爬虫爬取网站,比如让搜索引擎爬虫去爬取网站的内容,来增加网站的搜索排名。另一方面,由于网站的服务器资源有限,过多的非真实的用户对网站的大量访问,会增加运营成本和服务器负担。 因此,有些网站会设置一些反爬虫的措施。我
-
爬虫
这一章将会介绍使用一些新的模块(optparse,spider)去完成一个爬虫的web应用。爬虫其实就是一个枚举出一个网站上面的所有链接,以帮助你创建一个网站地图的web应用程序。而使用Python则可以很快的帮助你开发出一个爬虫脚本. 你可以创建一个爬虫脚本通过href标签对请求的响应内容进行解析,并且可以在解析的同时创建一个新的请求,你还可以直接调用spider模块来实现,这样就不需要自己去写
-
通用爬虫和聚焦爬虫
根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种. 通用爬虫 通用网络爬虫 就是 捜索引擎抓取系统,目的是将互联网上的所有的网页下载到本地,形成一个互联网内容的镜像备份。 它决定着整个搜索引擎内容的丰富性和时效性,因此它的性能优劣直接影响着搜索引擎的效果。 通用搜索引擎(Search Engine)工作原理 第一步:抓取网页 搜索引擎网络爬虫的基本工作流程如下: 首先选取一部分的初始UR
-
爬虫项
爬虫项是什么呢?比如采集文章列表、文章详情页,他们都是不同的采集项。 定义示例: 继承Yurun\Crawler\Module\Crawler\Contract\BaseCrawlerItem类。 <?php namespace Yurun\CrawlerApp\Module\YurunBlog\Article; use Imi\Bean\Annotation\Bean; use Yurun\C
-
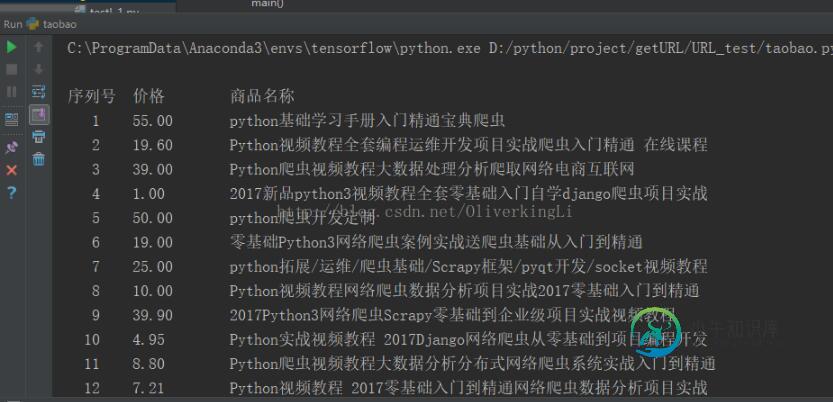 python爬虫爬取淘宝商品信息
python爬虫爬取淘宝商品信息本文向大家介绍python爬虫爬取淘宝商品信息,包括了python爬虫爬取淘宝商品信息的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 效果图: 更多内容请参考专题《python爬取功能汇总》进行学习。 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
爬虫面试
拼多多爬虫工程师面试题 电话面: http协议、tcp协议(几次握手) top命令 Linux/Mac 下虚拟内存(Swap) 线程、进程、协程 Async 相关、事件驱动相关 阻塞、非阻塞 Python GIL 布隆过滤器原理:如何实现、一般要几次哈希函数 给我留下了一个作业:抓取天猫超市上某些商品的可以配送省份信息。(当时做这个也花了很久,主要是需要解决PC端的登陆问题,后来通过h5接口) 现
-
爬虫介绍
什么是数据采集 定义 就我个人而说,更喜欢说数据采集而不是”爬虫“。其实更标准的叫法是网络爬虫,在wiki上是这样定义的: 网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。 就比如百度、谷歌,都是网络爬虫,把互联网上所有的数据采集下来,保存到自己的数据库中,并根据各种各种规则建立排名和索引,向用户提供搜索服务。
-
 爬虫课件
爬虫课件每天,来自商业、社会以及我们的日常生活所产生「图像、音频、视频、文本、定位信息」等各种各样的海量数据,注入到我们的万维网(WWW)、计算机和各种数据存储设备,其中万维网则是最大的信息载体。
-
 node.js爬虫爬取拉勾网职位信息
node.js爬虫爬取拉勾网职位信息本文向大家介绍node.js爬虫爬取拉勾网职位信息,包括了node.js爬虫爬取拉勾网职位信息的使用技巧和注意事项,需要的朋友参考一下 简介 用node.js写了一个简单的小爬虫,用来爬取拉勾网上的招聘信息,共爬取了北京、上海、广州、深圳、杭州、西安、成都7个城市的数据,分别以前端、PHP、java、c++、python、Android、ios作为关键词进行爬取,爬到的数据以json格式储存到本地
-
python爬虫爬取图片的简单代码
本文向大家介绍python爬虫爬取图片的简单代码,包括了python爬虫爬取图片的简单代码的使用技巧和注意事项,需要的朋友参考一下 Python是很好的爬虫工具不用再说了,它可以满足我们爬取网络内容的需求,那最简单的爬取网络上的图片,可以通过很简单的方法实现。只需导入正则表达式模块,并利用spider原理通过使用定义函数的方法可以轻松的实现爬取图片的需求。 1、spider原理 spider就是定
-
Python爬虫:常用的爬虫技巧总结
python应用最多的场景还是web快速开发、爬虫、自动化运维:写过简单网站、写过自动发帖脚本、写过收发邮件脚本、写过简单验证码识别脚本。 爬虫在开发过程中也有很多复用的过程,这里总结一下,以后也能省些事情。
-
 PHP实现爬虫爬取图片代码实例
PHP实现爬虫爬取图片代码实例本文向大家介绍PHP实现爬虫爬取图片代码实例,包括了PHP实现爬虫爬取图片代码实例的使用技巧和注意事项,需要的朋友参考一下 文字信息 我们尝试获取表的信息,这里,我们就用某校的课表来代替: 接下来我们就上代码: a.php 然后咱们就运行一下: 成功获取到课表; 图片获取 绝对链接 我们以百度图库的首页为例 b.php 然后,我们就获得了下面的页面: 相对链接 百度图库的图片的链接大部
-
Python爬虫爬取、解析数据操作示例
本文向大家介绍Python爬虫爬取、解析数据操作示例,包括了Python爬虫爬取、解析数据操作示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫爬取、解析数据操作。分享给大家供大家参考,具体如下: 爬虫 当当网 http://search.dangdang.com/?key=python&act=input&page_index=1 获取书籍相关信息 面向对象思想 利用不
-
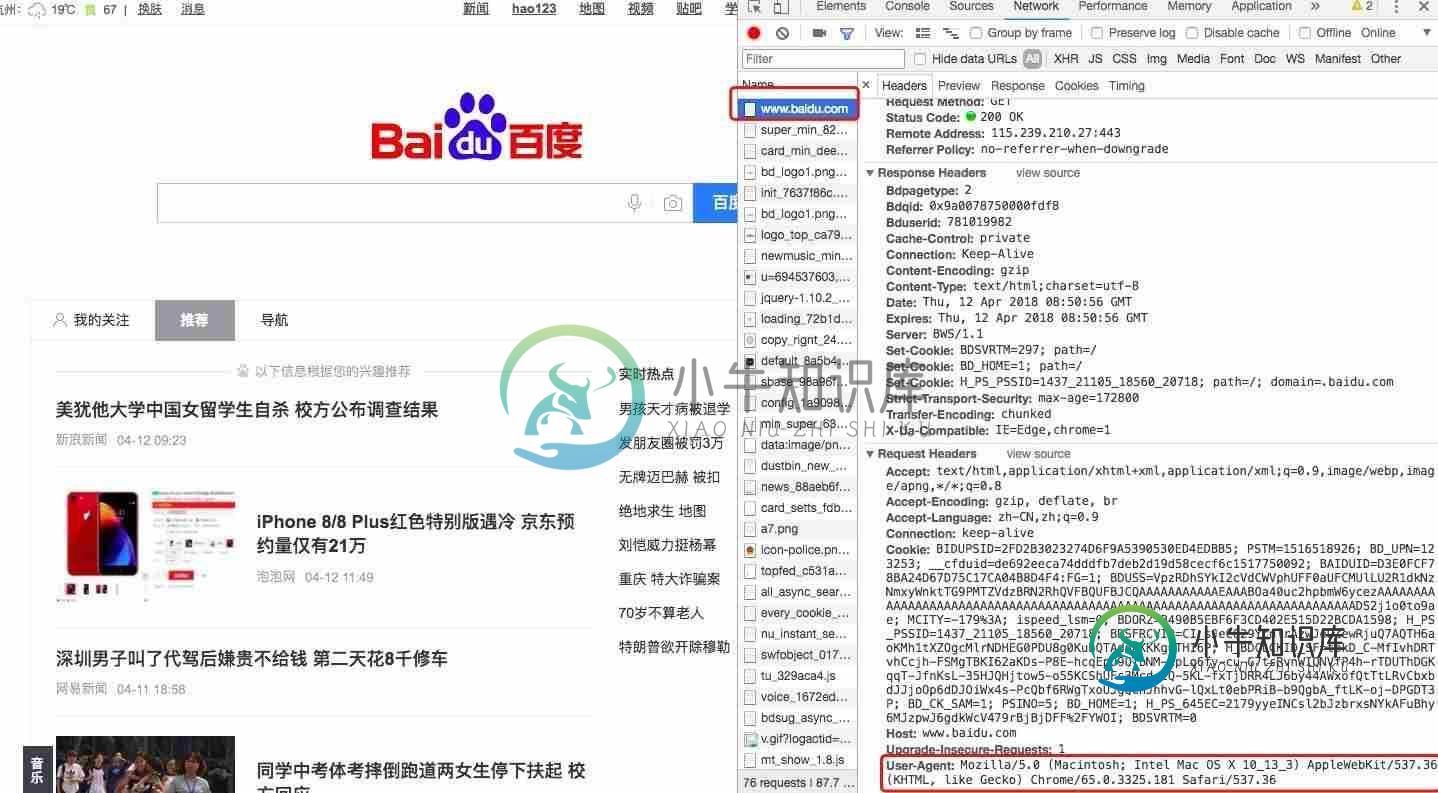 Python反爬虫伪装浏览器进行爬虫
Python反爬虫伪装浏览器进行爬虫本文向大家介绍Python反爬虫伪装浏览器进行爬虫,包括了Python反爬虫伪装浏览器进行爬虫的使用技巧和注意事项,需要的朋友参考一下 对于爬虫中部分网站设置了请求次数过多后会封杀ip,现在模拟浏览器进行爬虫,也就是说让服务器认识到访问他的是真正的浏览器而不是机器操作 简单的直接添加请求头,将浏览器的信息在请求数据时传入: 打开浏览器--打开开发者模式--请求任意网站 如下图:找到请求的的名字,打
-
 python爬虫爬取某站上海租房图片
python爬虫爬取某站上海租房图片本文向大家介绍python爬虫爬取某站上海租房图片,包括了python爬虫爬取某站上海租房图片的使用技巧和注意事项,需要的朋友参考一下 对于一个net开发这爬虫真真的以前没有写过。这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup。python 版本:python3.6 ,IDE :pycharm