《爬虫》专题
-
 Python爬虫爬取新闻资讯案例详解
Python爬虫爬取新闻资讯案例详解本文向大家介绍Python爬虫爬取新闻资讯案例详解,包括了Python爬虫爬取新闻资讯案例详解的使用技巧和注意事项,需要的朋友参考一下 前言 本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。 一个简单的Python资讯采集案例,列表页到详情页,到数据保存,保存为txt文档,网站网页结构算是比较规整,简单清晰明了,资讯新闻内容的采
-
小程序的爬虫能爬动态数据吗?
页面的内容如果是刚加载时从后台动态拉取的,那么像微信小程序这样的爬虫能爬吗? 如果不能爬的话,如果是浏览器,可以使用服务器渲染的技术来做 SEO,那么小程序是怎么做这种搜索优化
-
爬虫对象类
一个爬虫对象下面可能会有多个爬虫项目,他们都是相关联的。 定义示例: 继承Yurun\Crawler\Module\Crawler\Contract\BaseCrawler类,并实现方法。 <?php namespace Yurun\CrawlerApp\Module\YurunBlog; use Imi\Bean\Annotation\Bean; use Imi\Cron\Consts\Cro
-
 Python爬虫:通过关键字爬取百度图片
Python爬虫:通过关键字爬取百度图片本文向大家介绍Python爬虫:通过关键字爬取百度图片,包括了Python爬虫:通过关键字爬取百度图片的使用技巧和注意事项,需要的朋友参考一下 使用工具:Python2.7 点我下载 scrapy框架 sublime text3 一。搭建python(Windows版本) 1.安装python2.7 ---然后在cmd当中输入python,界面如下则安装成功 2.集成Scrapy框架----输
-
 Python爬虫爬取美剧网站的实现代码
Python爬虫爬取美剧网站的实现代码本文向大家介绍Python爬虫爬取美剧网站的实现代码,包括了Python爬虫爬取美剧网站的实现代码的使用技巧和注意事项,需要的朋友参考一下 一直有爱看美剧的习惯,一方面锻炼一下英语听力,一方面打发一下时间。之前是能在视频网站上面在线看的,可是自从广电总局的限制令之后,进口的美剧英剧等貌似就不在像以前一样同步更新了。但是,作为一个宅diao的我又怎甘心没剧追呢,所以网上随便查了一下就找到一个能用迅雷
-
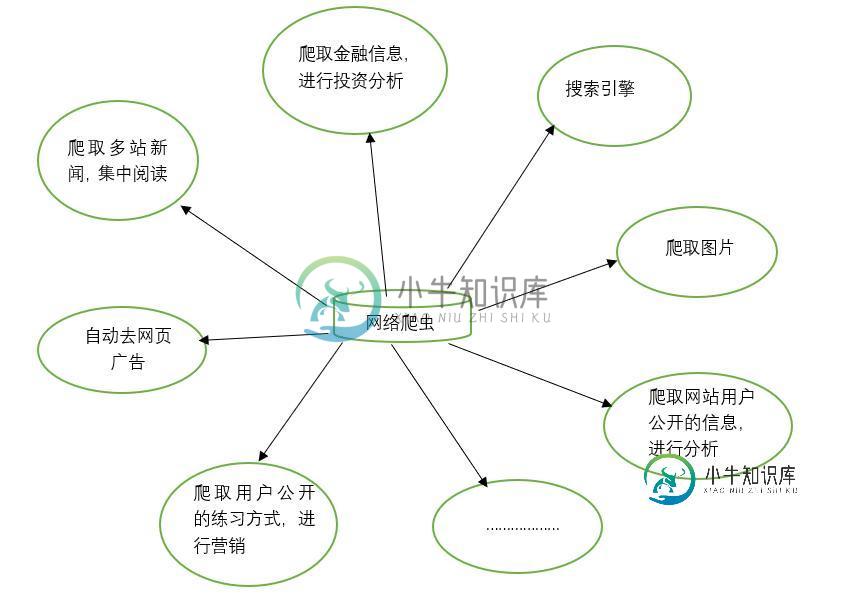 python爬虫爬取网页数据并解析数据
python爬虫爬取网页数据并解析数据本文向大家介绍python爬虫爬取网页数据并解析数据,包括了python爬虫爬取网页数据并解析数据的使用技巧和注意事项,需要的朋友参考一下 1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。 只要浏览器能够做的事情,原则上,爬虫都能够做到。 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以
-
python爬虫 - Python爬虫WinError 10061连接拒绝问题?
python爬虫时显示 [WinError 10061] 由于目标计算机积极拒绝,无法连接。 import csv import random import time import pandas as pd import requests from bs4 import BeautifulSoup import matplotlib.pyplot as plt plt.rcParams["font
-
 python爬虫 - python3 爬虫,请问这是什么编码?
python爬虫 - python3 爬虫,请问这是什么编码?原始content: decode('utf-8')报错: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe8 in position 1: invalid continuation byte decode('utf-8', 'ignore'): decode('gbk', 'ignore'): decode('utf-16', 'ig
-
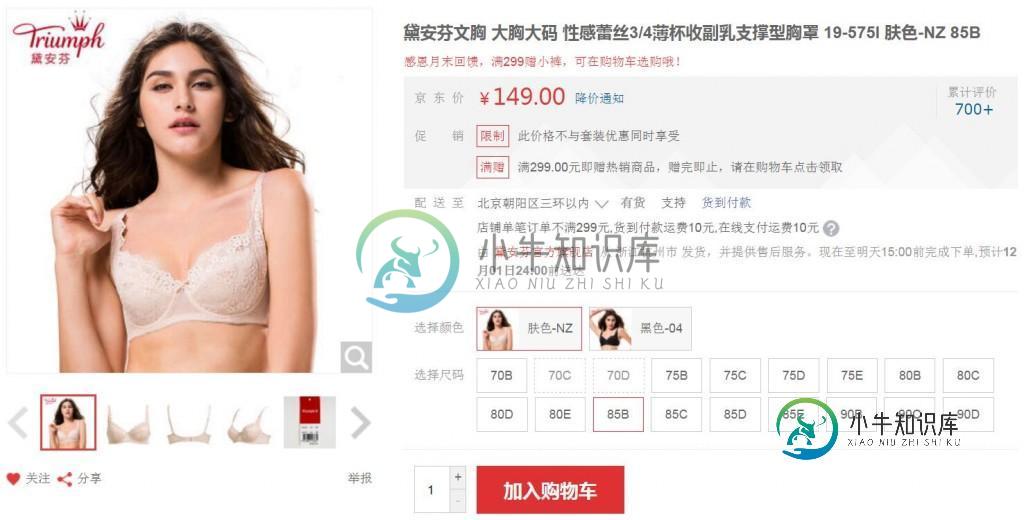 python制作爬虫爬取京东商品评论教程
python制作爬虫爬取京东商品评论教程本文向大家介绍python制作爬虫爬取京东商品评论教程,包括了python制作爬虫爬取京东商品评论教程的使用技巧和注意事项,需要的朋友参考一下 本篇文章是python爬虫系列的第三篇,介绍如何抓取京东商城商品评论信息,并对这些评论信息进行分析和可视化。下面是要抓取的商品信息,一款女士文胸。这个商品共有红色,黑色和肤色三种颜色, 70B到90D共18个尺寸,以及超过700条的购买评论。 京东商品评论
-
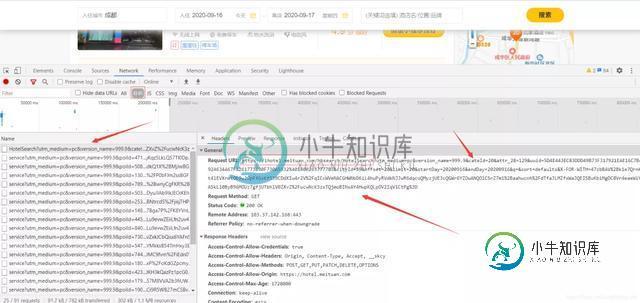 如何基于Python爬虫爬取美团酒店信息
如何基于Python爬虫爬取美团酒店信息本文向大家介绍如何基于Python爬虫爬取美团酒店信息,包括了如何基于Python爬虫爬取美团酒店信息的使用技巧和注意事项,需要的朋友参考一下 一、分析网页 网站的页面是 JavaScript 渲染而成的,我们所看到的内容都是网页加载后又执行了JavaScript代码之后才呈现出来的,因此这些数据并不存在于原始 HTML 代码中,而 requests 仅仅抓取的是原始 HTML 代码。抓取这种类型
-
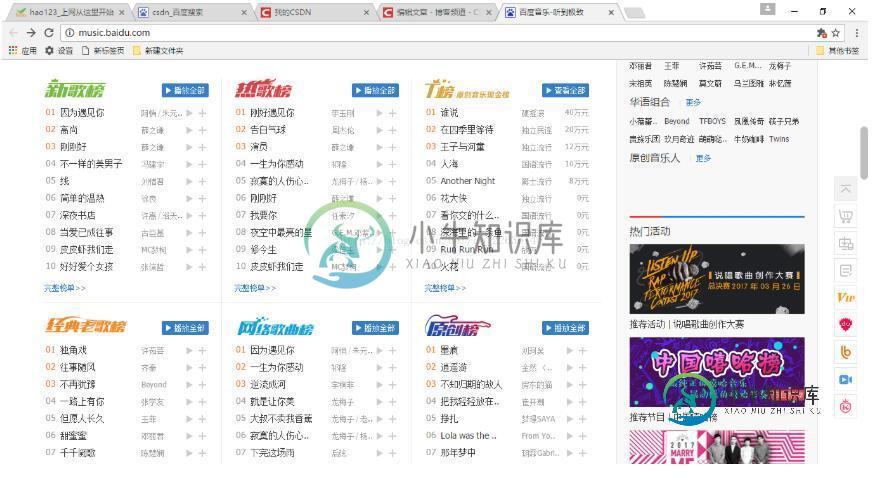 python爬虫之爬取百度音乐的实现方法
python爬虫之爬取百度音乐的实现方法本文向大家介绍python爬虫之爬取百度音乐的实现方法,包括了python爬虫之爬取百度音乐的实现方法的使用技巧和注意事项,需要的朋友参考一下 在上次的爬虫中,抓取的数据主要用到的是第三方的Beautifulsoup库,然后对每一个具体的数据在网页中的selecter来找到它,每一个类别便有一个select方法。对网页有过接触的都知道很多有用的数据都放在一个共同的父节点上,只是其子节点不同。在上次
-
关于爬虫和反爬虫的简略方案分享
本文向大家介绍关于爬虫和反爬虫的简略方案分享,包括了关于爬虫和反爬虫的简略方案分享的使用技巧和注意事项,需要的朋友参考一下 前言 爬虫和反爬虫日益成为每家公司的标配系统。 爬虫在情报获取、虚假流量、动态定价、恶意攻击、薅羊毛等方面都能起到很关键的作用,所以每家公司都或多或少的需要开发一些爬虫程序,业界在这方面的成熟的方案也非常多。 有矛就有盾,每家公司也相应的需要反爬虫系统来达到数据保护、系统稳定
-
 Python Scrapy爬虫框架
Python Scrapy爬虫框架主要内容:Scrapy下载安装,创建Scrapy爬虫项目,Scrapy爬虫工作流程,settings配置文件Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架使用纯 Python 语言编写。Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等。 提示:Twisted 是一个基于事件驱动的网络引擎框架,同样采用 Python 实现。 Scrapy下载安装 Scrapy 支持常见的主流平台,比如 Linux、Mac、Windows 等,因此你可以很方便的安装它
-
 Python多线程爬虫
Python多线程爬虫主要内容:多线程使用流程,Queue队列模型,多线程爬虫案例网络爬虫程序是一种 IO 密集型程序,程序中涉及了很多网络 IO 以及本地磁盘 IO 操作,这些都会消耗大量的时间,从而降低程序的执行效率,而 Python 提供的多线程能够在一定程度上提升 IO 密集型程序的执行效率。 如果想学习 Python 多进程、多线程以及 Python GIL 全局解释器锁的相关知识,可参考《Python并发编程教程》。 多线程使用流程 Python 提供了两个支持多线
-
6.7 分布式爬虫
互联网时代的信息爆炸是很多人倍感头痛的问题,应接不暇的新闻、信息、视频,无孔不入地侵占着我们的碎片时间。但另一方面,在我们真正需要数据的时候,却感觉数据并不是那么容易获取的。比如我们想要分析现在人在讨论些什么,关心些什么。甚至有时候,可能我们只是暂时没有时间去一一阅览心仪的小说,但又想能用技术手段把它们存在自己的资料库里。哪怕是几个月或一年后再来回顾。再或者我们想要把互联网上这些稍纵即逝的有用信息