《爬虫》专题
-
01 网络爬虫简介
图片来源于网络 1. 爬虫的定义 网络爬虫(又称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。—— 百度百科定义 详细定义参照 慕课网注解: 爬虫其实是一种自动化信息采集程序或脚本,可以方便的帮助大家获得自己想要的特定信息。比如说,像百度,谷歌等搜索引擎
-
百度云分享爬虫
百度云分享爬虫项目 github上有好几个这样的开源项目,但是都只提供了爬虫部分,这个项目在爬虫的基础上还增加了保存数据,建立elasticsearch索引的模块,可以用在实际生产环境中,不过web模块还是需要自己开发 安装 安装node.js和pm2,node用来运行爬虫程序和索引程序,pm2用来管理node任务 安装mysql和mongodb,mysql用来保存爬虫数据,mongodb用来保存
-
Scrapy-爬行器开始爬行后更改规则
我的查询是针对
-
 Python实现爬取知乎神回复简单爬虫代码分享
Python实现爬取知乎神回复简单爬虫代码分享本文向大家介绍Python实现爬取知乎神回复简单爬虫代码分享,包括了Python实现爬取知乎神回复简单爬虫代码分享的使用技巧和注意事项,需要的朋友参考一下 看知乎的时候发现了一个 “如何正确地吐槽” 收藏夹,里面的一些神回复实在很搞笑,但是一页一页地看又有点麻烦,而且每次都要打开网页,于是想如果全部爬下来到一个文件里面,是不是看起来很爽,并且随时可以看到全部的,于是就开始动手了。 工具 1.Pyt
-
 Python使用爬虫爬取静态网页图片的方法详解
Python使用爬虫爬取静态网页图片的方法详解本文向大家介绍Python使用爬虫爬取静态网页图片的方法详解,包括了Python使用爬虫爬取静态网页图片的方法详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python使用爬虫爬取静态网页图片的方法。分享给大家供大家参考,具体如下: 爬虫理论基础 其实爬虫没有大家想象的那么复杂,有时候也就是几行代码的事儿,千万不要把自己吓倒了。这篇就清晰地讲解一下利用Python爬虫的理论基础。 首
-
python爬虫线程池案例详解(梨视频短视频爬取)
本文向大家介绍python爬虫线程池案例详解(梨视频短视频爬取),包括了python爬虫线程池案例详解(梨视频短视频爬取)的使用技巧和注意事项,需要的朋友参考一下 python爬虫-梨视频短视频爬取(线程池) 示例代码 知识点扩展: Python爬虫下载视频(梨视频) 梨视频示例:Ctrl+Alt+L格式化代码 到此这篇关于python爬虫线程池案例详解(梨视频短视频爬取)的文章就介绍到这了,更多
-
 Python 3实战爬虫之爬取京东图书的图片详解
Python 3实战爬虫之爬取京东图书的图片详解本文向大家介绍Python 3实战爬虫之爬取京东图书的图片详解,包括了Python 3实战爬虫之爬取京东图书的图片详解的使用技巧和注意事项,需要的朋友参考一下 前言 最近工作中遇到一个需求,需要将京东上图书的图片下载下来,假如我们想把京东商城图书类的图片类商品图片全部下载到本地,通过手工复制粘贴将是一项非常庞大的工程,此时,可以用Python网络爬虫实现,这类爬虫称为图片爬虫,接下来,我们将实现该
-
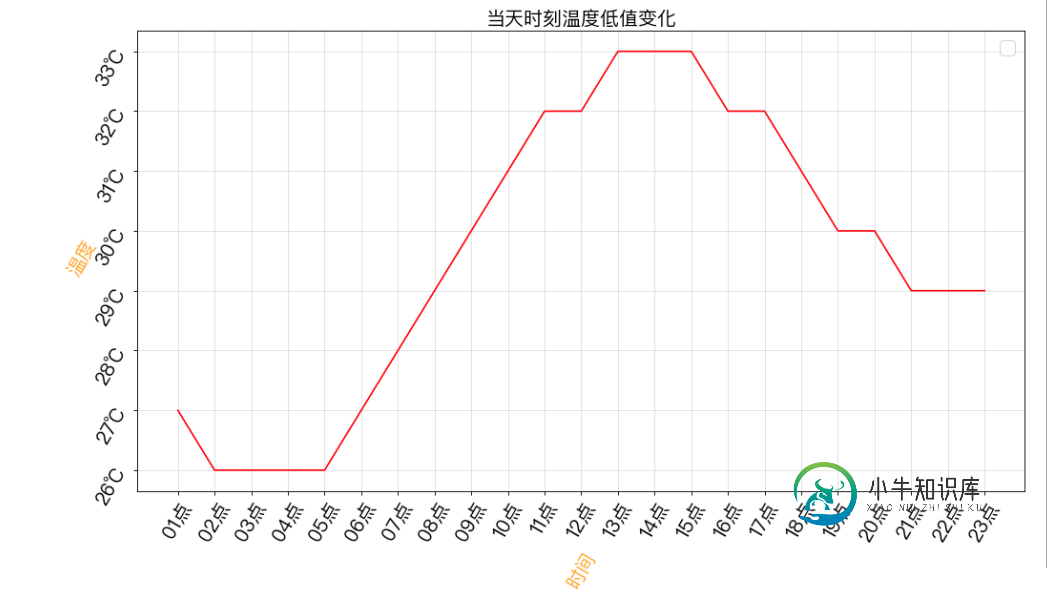 Python爬虫爬取杭州24时温度并展示操作示例
Python爬虫爬取杭州24时温度并展示操作示例本文向大家介绍Python爬虫爬取杭州24时温度并展示操作示例,包括了Python爬虫爬取杭州24时温度并展示操作示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫爬取杭州24时温度并展示操作。分享给大家供大家参考,具体如下: 散点图 爬虫杭州今日24时温度 https://www.baidutianqi.com/today/58457.htm 利用正则表达式爬取杭州温度
-
python爬虫入门教程之糗百图片爬虫代码分享
本文向大家介绍python爬虫入门教程之糗百图片爬虫代码分享,包括了python爬虫入门教程之糗百图片爬虫代码分享的使用技巧和注意事项,需要的朋友参考一下 学习python少不了写爬虫,不仅能以点带面地学习、练习使用python,爬虫本身也是有用且有趣的,大量重复性的下载、统计工作完全可以写一个爬虫程序完成。 用python写爬虫需要python的基础知识、涉及网络的几个模块、正则表达式、文件操作
-
Runnig Ex爬行器
嗨,我正在运行这个开源Ex-Crawler的罐子 但我总是收到这样的错误:og4j:WARN找不到记录器的追加器(eu.medsea.mimeutil.TextMimeDetector)。log4j:警告请正确初始化log4j系统。log4j:请参阅http://logging.apache.org/log4j/1.2/faq.html#noconfig更多信息
-
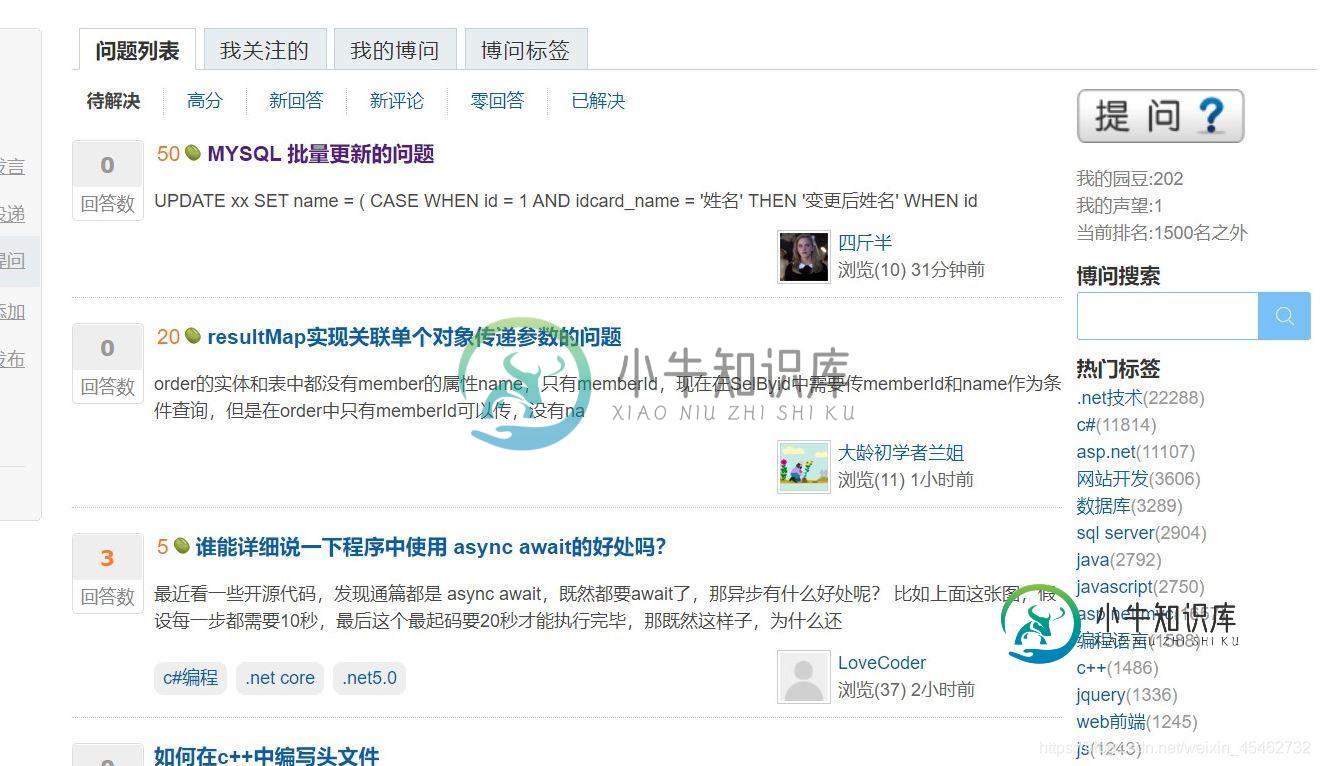 详解Python爬虫爬取博客园问题列表所有的问题
详解Python爬虫爬取博客园问题列表所有的问题本文向大家介绍详解Python爬虫爬取博客园问题列表所有的问题,包括了详解Python爬虫爬取博客园问题列表所有的问题的使用技巧和注意事项,需要的朋友参考一下 一.准备工作 首先,本文使用的技术为 python+requests+bs4,没有了解过可以先去了解一下。 我们的需求是将博客园问题列表中的所有问题的题目爬取下来。 二.分析: 首先博客园问题列表页面右键点击检查 通过Element查找
-
java能写爬虫程序吗
本文向大家介绍java能写爬虫程序吗,包括了java能写爬虫程序吗的使用技巧和注意事项,需要的朋友参考一下 我们经常会使用网络爬虫去爬取需要的内容,提到爬虫,可能大家伙都会想到python,其实除了python,还有java。java的编程语言简单规范,是很好的爬虫工具。而且java爬虫的语言运行速度比python快,另外,java的多线程是可以利用多核的。 1、java为什么可以应用于网络爬虫?
-
 Python使用爬虫猜密码
Python使用爬虫猜密码本文向大家介绍Python使用爬虫猜密码,包括了Python使用爬虫猜密码的使用技巧和注意事项,需要的朋友参考一下 我们可以通过python 来实现这样一个简单的爬虫猜密码功能。下面就看看如何使用python来实现这样一个功能。 这里我们知道用户的昵称为:heibanke 密码是30以内的一个数字,要使用requests库循环提交来猜密码 主要需要用到的库是requests库 安装requests
-
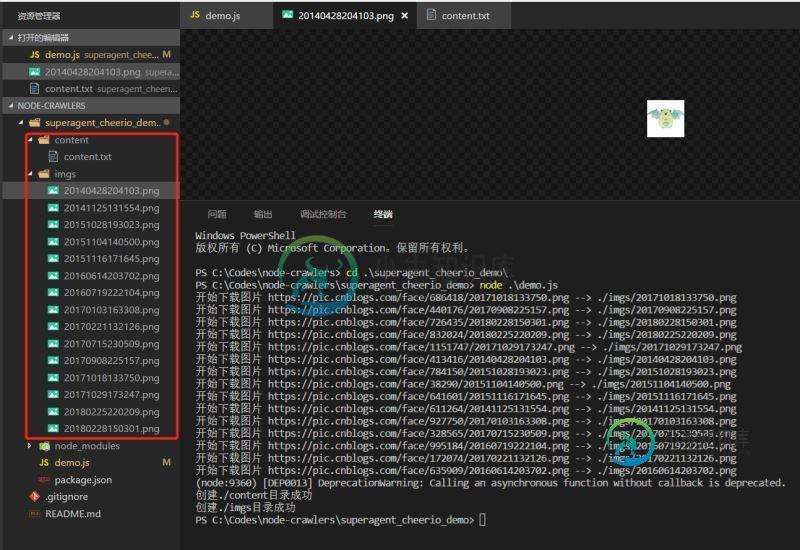 nodejs爬虫初试superagent和cheerio
nodejs爬虫初试superagent和cheerio本文向大家介绍nodejs爬虫初试superagent和cheerio,包括了nodejs爬虫初试superagent和cheerio的使用技巧和注意事项,需要的朋友参考一下 前言 早就听过爬虫,这几天开始学习nodejs,写了个爬虫https://github.com/leichangchun/node-crawlers/tree/master/superagent_cheerio_demo
-
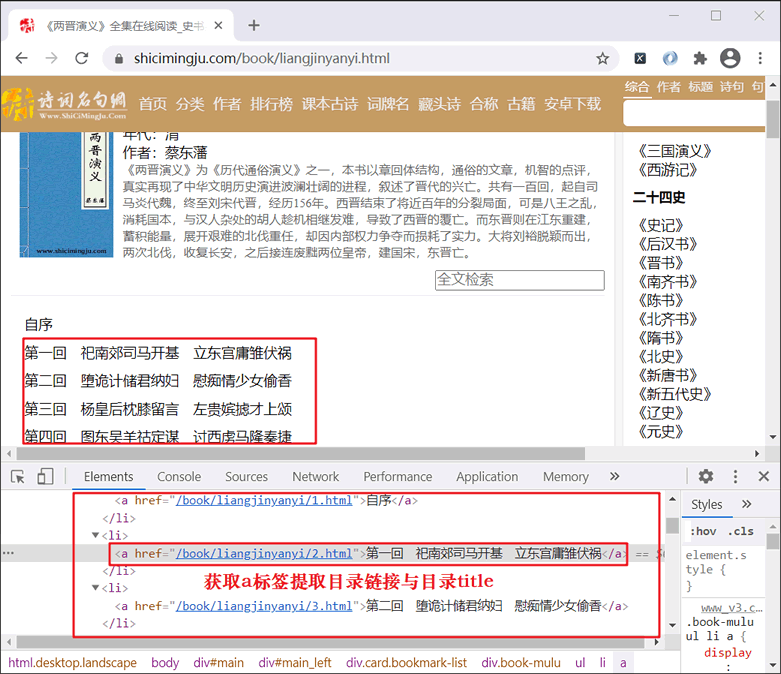 [实例]爬虫下载小说
[实例]爬虫下载小说主要内容:案例简单分析,编写爬虫程序本节通过具体的爬虫程序,演示 BS4 解析库的实际应用。爬虫程序目标:下载诗词名句网( https://www.shicimingju.com/book/)《 两晋演义》小说。 关于分析网页分过程,这里不再做详细介绍了,只要通读了前面的文章,那么关于如何分析网页,此时您应该了然于胸了。其实,无论您爬取什么类型的网站,分析过程总是相似的。 案例简单分析 首先判网站属于静态网站,因此您的主要任务是分析