《爬虫》专题
-
通用爬虫(Broad Crawls)
Scrapy默认对特定爬取进行优化。这些站点一般被一个单独的Scrapy spider进行处理, 不过这并不是必须或要求的(例如,也有通用的爬虫能处理任何给定的站点)。 除了这种爬取完某个站点或没有更多请求就停止的”专注的爬虫”,还有一种通用的爬取类型,其能爬取大量(甚至是无限)的网站, 仅仅受限于时间或其他的限制。 这种爬虫叫做”通用爬虫(broad crawls)”,一般用于搜索引擎。 通用爬
-
使用 bs4 的爬虫
我们以 亚马逊Kindle电子书销售排行榜 商品页面来做演示:https://www.amazon.cn/gp/bestsellers/digital-text/116169071 使用BeautifuSoup4解析器,将每件商品的的ASIN、标题、价格、star、评价数量,以及每件商品的链接爬取下来并存储在.csv文件中。 import csv import requests from
-
4.6 爬虫的监控
4.6 爬虫的监控 爬虫的监控是0.5.0新增的功能。利用这个功能,你可以查看爬虫的执行情况——已经下载了多少页面、还有多少页面、启动了多少线程等信息。该功能通过JMX实现,你可以使用Jconsole等JMX工具查看本地或者远程的爬虫信息。 如果你完全不会JMX也没关系,因为它的使用相对简单,本章会比较详细的讲解使用方法。如果要弄明白其中原理,你可能需要一些JMX的知识,推荐阅读:JMX整理。我很
-
神箭手云爬虫
神箭手云爬虫是一个帮助开发者快速开发爬虫系统的云框架。神箭手提供上手简单,灵活开放的爬虫云开发环境,让开发者只需要在线写几行js代码就可以实现一个爬虫。并且爬虫将自动运行在云服务器上,爬取速度更快,效率更高。 神箭手的主要功能包括: 1、完全脚本化,只需要编写简单的js就可以爬取任何网站。提供丰富的开放接口,同时支持所有的js自带函数。 2、自带防屏蔽函数,包括代理ip、验证码识别等。 3、爬取的
-
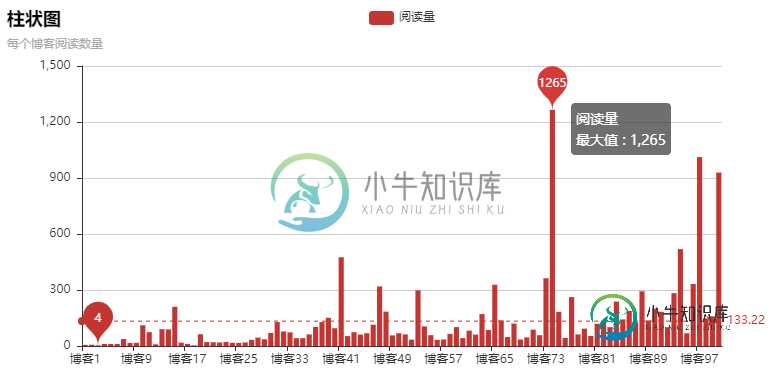 Python爬虫爬取博客实现可视化过程解析
Python爬虫爬取博客实现可视化过程解析本文向大家介绍Python爬虫爬取博客实现可视化过程解析,包括了Python爬虫爬取博客实现可视化过程解析的使用技巧和注意事项,需要的朋友参考一下 源码: 爬虫不是重点,只是拿来爬阅读数量,pyecharts是重点 这次爬的是我自己的博客,一共10页,每页10片文章,正好写了100篇博客 pyecharts安装: pip install wheelpip install pyecharts==0.
-
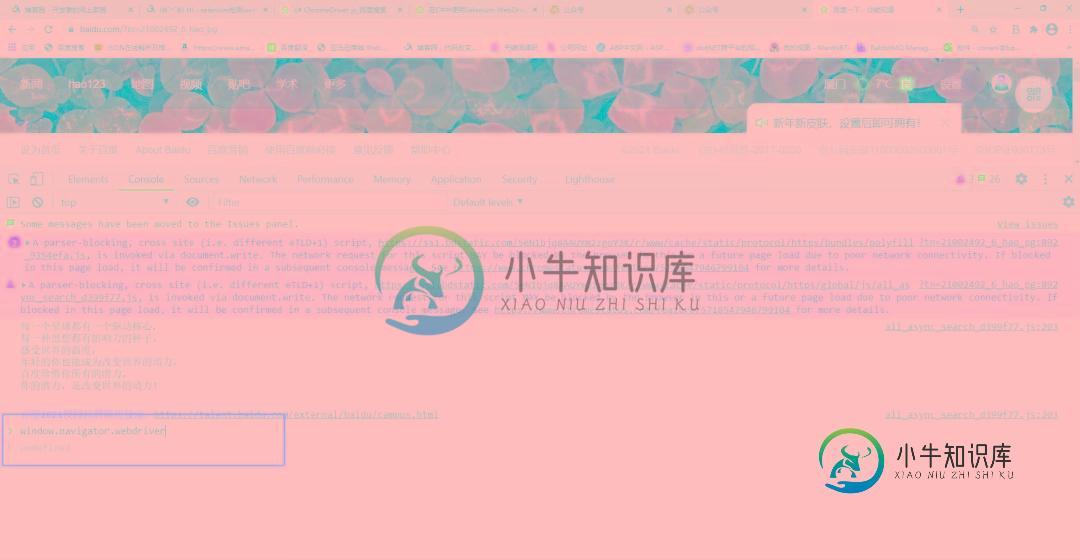 c# Selenium爬取数据时防止webdriver封爬虫的方法
c# Selenium爬取数据时防止webdriver封爬虫的方法本文向大家介绍c# Selenium爬取数据时防止webdriver封爬虫的方法,包括了c# Selenium爬取数据时防止webdriver封爬虫的方法的使用技巧和注意事项,需要的朋友参考一下 背景 大家在使用Selenium + Chromedriver爬取网站信息的时候,以为这样就能做到不被网站的反爬虫机制发现。但是实际上很多参数和实际浏览器还是不一样的,只要网站进行判断处理,就能轻轻松松识
-
基于python 爬虫爬到含空格的url的处理方法
本文向大家介绍基于python 爬虫爬到含空格的url的处理方法,包括了基于python 爬虫爬到含空格的url的处理方法的使用技巧和注意事项,需要的朋友参考一下 道友问我的一个问题,之前确实没遇见过,在此记录一下。 问题描述 在某网站主页提取url进行迭代,爬虫请求主页时没有问题,返回正常,但是在访问在主页提取到的url时出现了400状态码(400 Bad Request)。 结论 先贴出结论来
-
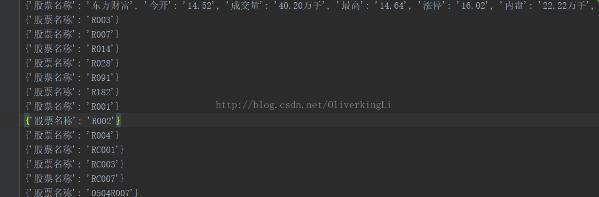 使用python爬虫实现网络股票信息爬取的demo
使用python爬虫实现网络股票信息爬取的demo本文向大家介绍使用python爬虫实现网络股票信息爬取的demo,包括了使用python爬虫实现网络股票信息爬取的demo的使用技巧和注意事项,需要的朋友参考一下 实例如下所示: 优化并且加入进度条显示 以上这篇使用python爬虫实现网络股票信息爬取的demo就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。
-
零基础写python爬虫之爬虫的定义及URL构成
本文向大家介绍零基础写python爬虫之爬虫的定义及URL构成,包括了零基础写python爬虫之爬虫的定义及URL构成的使用技巧和注意事项,需要的朋友参考一下 一、网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字。 把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。 网络蜘蛛是通过网页的链接地址来寻找网页的。 从网站某一个页面(通常是首页)开始,读取网页的内容
-
 网络爬虫是什么
网络爬虫是什么主要内容:认识爬虫,爬虫分类,爬虫应用,爬虫是一把双刃剑,为什么用Python做爬虫,编写爬虫的流程网络爬虫又称网络蜘蛛、网络机器人,它是一种按照一定的规则自动浏览、检索网页信息的程序或者脚本。网络爬虫能够自动请求网页,并将所需要的数据抓取下来。通过对抓取的数据进行处理,从而提取出有价值的信息。 认识爬虫 我们所熟悉的一系列搜索引擎都是大型的网络爬虫,比如百度、搜狗、360浏览器、谷歌搜索等等。每个搜索引擎都拥有自己的爬虫程序,比如 360 浏览器的爬虫称作 360Spider,搜狗的爬虫叫做
-
python爬虫容易学吗
本文向大家介绍python爬虫容易学吗,包括了python爬虫容易学吗的使用技巧和注意事项,需要的朋友参考一下 随着大数据时代的到来,数据将如同煤电气油一样,成为我们最重要的能源之一,然而这种能源是可以源源不断产生、可再生的。而Python爬虫作为获取数据的关键一环,在大数据时代有着极为重要的作用。于是许多同学就前来咨询:Python爬虫好学吗? 什么是爬虫? 网络爬虫,又被称为网页蜘蛛,网络机器
-
Jobs: 暂停,恢复爬虫
有些情况下,例如爬取大的站点,我们希望能暂停爬取,之后再恢复运行。 Scrapy通过如下工具支持这个功能: 一个把调度请求保存在磁盘的调度器 一个把访问请求保存在磁盘的副本过滤器[duplicates filter] 一个能持续保持爬虫状态(键/值对)的扩展 Job 路径 要启用持久化支持,你只需要通过 JOBDIR 设置 job directory 选项。这个路径将会存储 所有的请求数据来保持一
-
8. 网络爬虫实战
案例:爬取百度新闻首页的新闻标题信息 url地址:http://news.baidu.com/ 具体实现步骤: 导入urlib库和re正则 使用urllib.request.Request()创建request请求对象 使用urllib.request.urlopen执行信息爬取,并返回Response对象 使用read()读取信息,使用decode()执行解码 使用re正则解析结果 遍历输出结果
-
5. 网络爬虫概述
5.1 网络爬虫概述: 网络爬虫(Web Spider)又称网络蜘蛛、网络机器人,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。 网络爬虫按照系统结构和实现技术,大致可分为一下集中类型: 通用网络爬虫:就是尽可能大的网络覆盖率,如 搜索引擎(百度、雅虎和谷歌等…)。 聚焦网络爬虫:有目标性,选择性地访问万维网来爬取信息。 增量式网络爬虫:只爬取新产生的或者已经更新的页面信息。特点:耗费
-
 Python 原生爬虫教程
Python 原生爬虫教程网络爬虫(又称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。