
Python爬虫爬取博客实现可视化过程解析

源码:
from pyecharts import Bar
import re
import requests
num=0
b=[]
for i in range(1,11):
link='https://www.cnblogs.com/echoDetected/default.html?page='+str(i)
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'}
r=requests.get(link,headers=headers)
html=r.text
post=re.findall('<span class="post-view-count">(.*?)</span>',html)
for i in post:
i = i.replace("阅读(", "")
i = i.replace(")","")
b.append(i)
num=num+1
columns=[]
for i in range(1,num+1):
#设置行名
columns.append('博客'+str(i))
#设置数据
#设置柱状图的主标题与副标题
bar = Bar("柱状图", "每个博客阅读数量")
#添加柱状图的数据及配置项,先行后列
bar.add("阅读量", columns, b, mark_line=["average"], mark_point=["max", "min"])
#生成本地文件(默认为.html文件)
bar.render()
爬虫不是重点,只是拿来爬阅读数量,pyecharts是重点
这次爬的是我自己的博客,一共10页,每页10片文章,正好写了100篇博客
pyecharts安装:
pip install wheelpip install pyecharts==0.1.9.4
直接pip install pyecharts会下载最新版无法调用
注意点:pyecharts调用,貌似无法实现多个py文件一起调用(意思是编写时不能在多个文件里出现import语句)
步骤解释:
1.爬虫爬取阅读数
2.去除非法字符装入新的数组
3.设置横轴数据,生成柱状图
4.在当前目录下生成render.html,打开查看柱状图
结果:
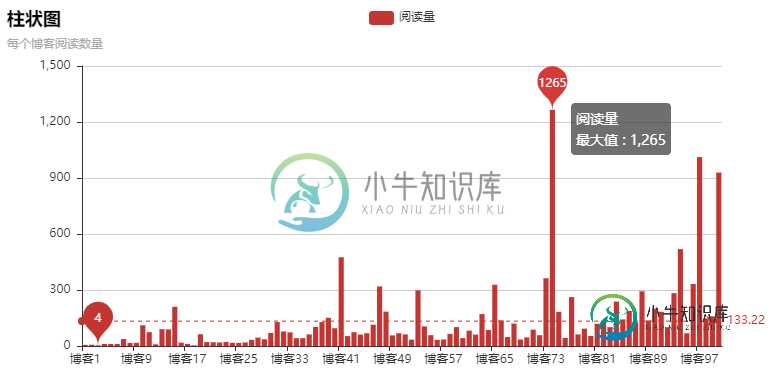
柱状图是动态的,不是静态的

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍详解Python爬虫爬取博客园问题列表所有的问题,包括了详解Python爬虫爬取博客园问题列表所有的问题的使用技巧和注意事项,需要的朋友参考一下 一.准备工作 首先,本文使用的技术为 python+requests+bs4,没有了解过可以先去了解一下。 我们的需求是将博客园问题列表中的所有问题的题目爬取下来。 二.分析: 首先博客园问题列表页面右键点击检查 通过Element查找
-
本文向大家介绍Python爬虫 bilibili视频弹幕提取过程详解,包括了Python爬虫 bilibili视频弹幕提取过程详解的使用技巧和注意事项,需要的朋友参考一下 两个重要点 1.获取弹幕的url是以 .xml 结尾 2.弹幕url的所需参数在视频url响应的 javascript 中 先看代码 先找到弹幕的url,以.xml结尾,所以先找到这串数字所在的位置,并获取这串数字发起第二次请求
-
本文向大家介绍基于python爬取梨视频实现过程解析,包括了基于python爬取梨视频实现过程解析的使用技巧和注意事项,需要的朋友参考一下 目标网址:梨视频 然后我们找到科技这一页:https://www.pearvideo.com/category_8。其实你要哪一页都行,你喜欢就行。嘿嘿… 这是动态网站,所以咱们直奔network 然后去到XHR: 找规律,这个应该不难,我就直接贴网址上来咯,
-
本文向大家介绍node.js实现博客小爬虫的实例代码,包括了node.js实现博客小爬虫的实例代码的使用技巧和注意事项,需要的朋友参考一下 前言 爬虫,是一种自动获取网页内容的程序。是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上就是针对爬虫而做出的优化。 这篇文章介绍的是利用node.js实现博客小爬虫,核心的注释我都标注好了,可以自行理解,只需修改url和按照要趴的博客内部dom构造改一下
-
本文向大家介绍python爬虫线程池案例详解(梨视频短视频爬取),包括了python爬虫线程池案例详解(梨视频短视频爬取)的使用技巧和注意事项,需要的朋友参考一下 python爬虫-梨视频短视频爬取(线程池) 示例代码 知识点扩展: Python爬虫下载视频(梨视频) 梨视频示例:Ctrl+Alt+L格式化代码 到此这篇关于python爬虫线程池案例详解(梨视频短视频爬取)的文章就介绍到这了,更多
-
本文向大家介绍Python爬虫爬取美剧网站的实现代码,包括了Python爬虫爬取美剧网站的实现代码的使用技巧和注意事项,需要的朋友参考一下 一直有爱看美剧的习惯,一方面锻炼一下英语听力,一方面打发一下时间。之前是能在视频网站上面在线看的,可是自从广电总局的限制令之后,进口的美剧英剧等貌似就不在像以前一样同步更新了。但是,作为一个宅diao的我又怎甘心没剧追呢,所以网上随便查了一下就找到一个能用迅雷