
详解Python爬虫爬取博客园问题列表所有的问题

一.准备工作
- 首先,本文使用的技术为 python+requests+bs4,没有了解过可以先去了解一下。
- 我们的需求是将博客园问题列表中的所有问题的题目爬取下来。
二.分析:
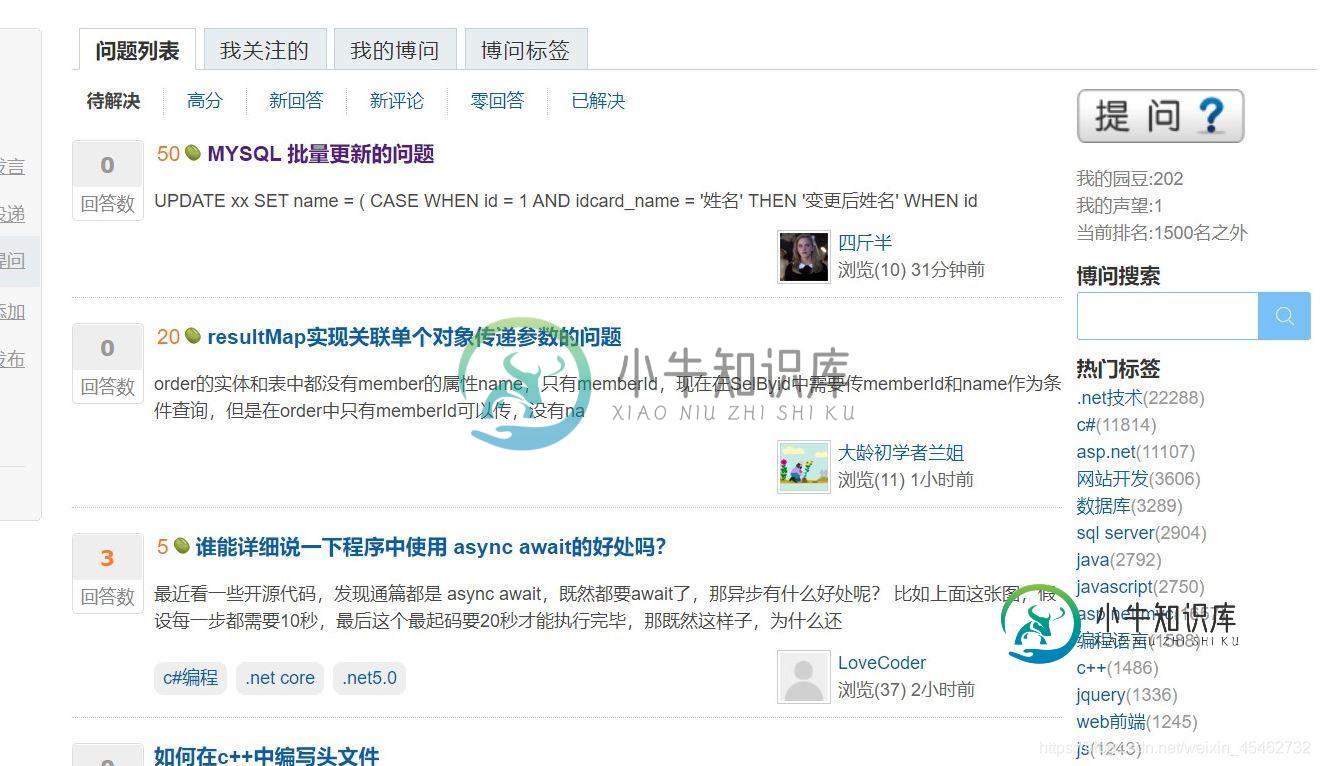
- 首先博客园问题列表页面右键点击检查
- 通过Element查找问题所对应的属性或标签
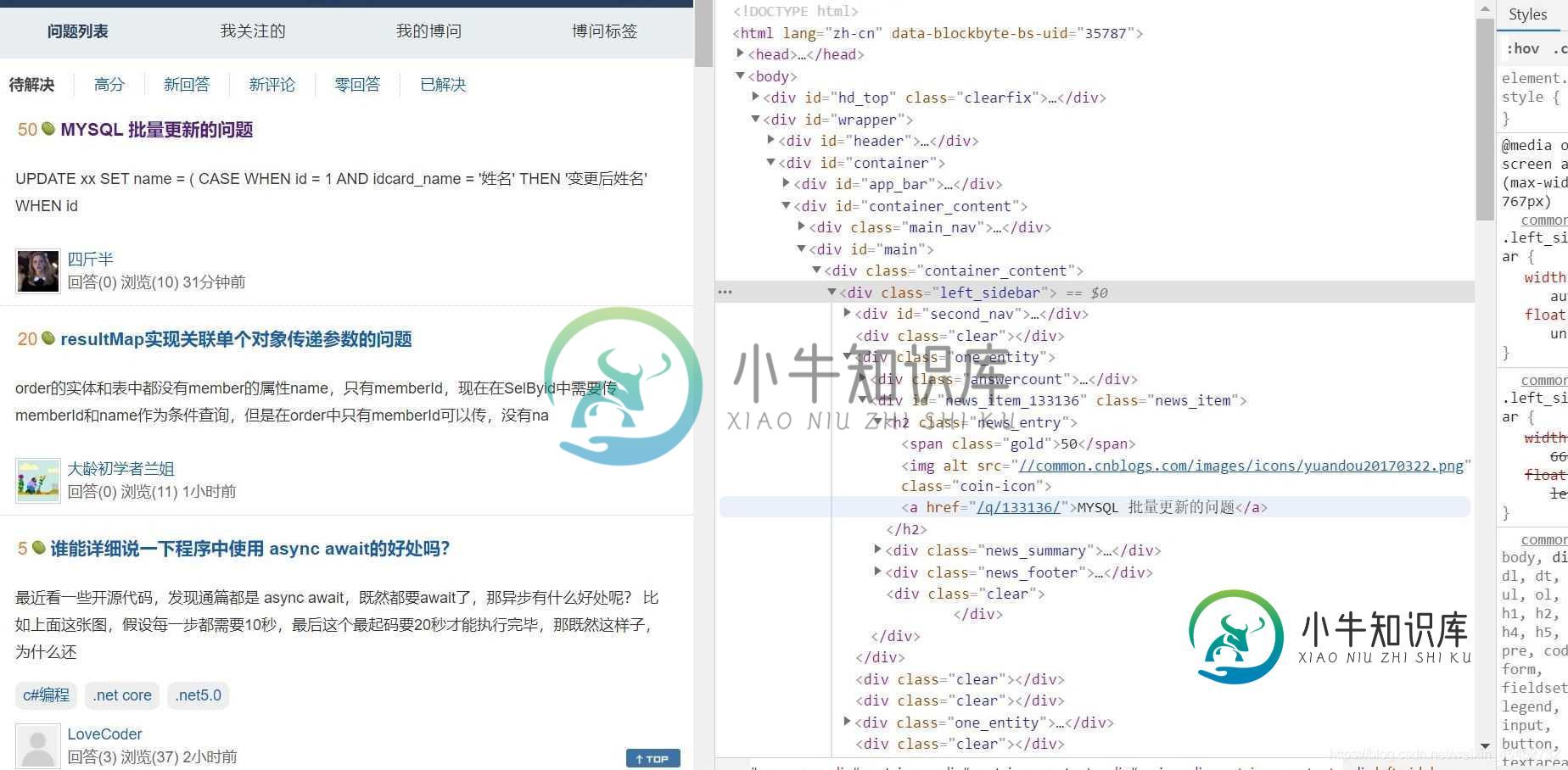
可以发现在div class ="one_entity"中存在页面中分别对应每一个问题
接着div class ="news_item"中h2标签下是我们想要拿到的数据
三.代码实现
首先导入requests和BeautifulSoup
import requests from bs4 import BeautifulSoup
由于很多网站定义了反爬策略,所以进行伪装一下
headers = {
'User-Agent': 'Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 87.0.4280.141Safari / 537.36'
}
在这里User-Agent只是其中的一种方式,而且大家的User-Agent可能不同。
爬取数据main代码
url = 'https://q.cnblogs.com/list/unsolved?'
fp = open('blog', 'w', encoding='utf-8')
for page in range(1,26):
page = str(page)
param = {
'page':page
}
page_text = requests.get(url=url,params=param,headers=headers).text
page_soup = BeautifulSoup(page_text,'lxml')
text_list = page_soup.select('.one_entity > .news_item > h2')
for h2 in text_list:
text = h2.a.string
fp.write(text+'\n')
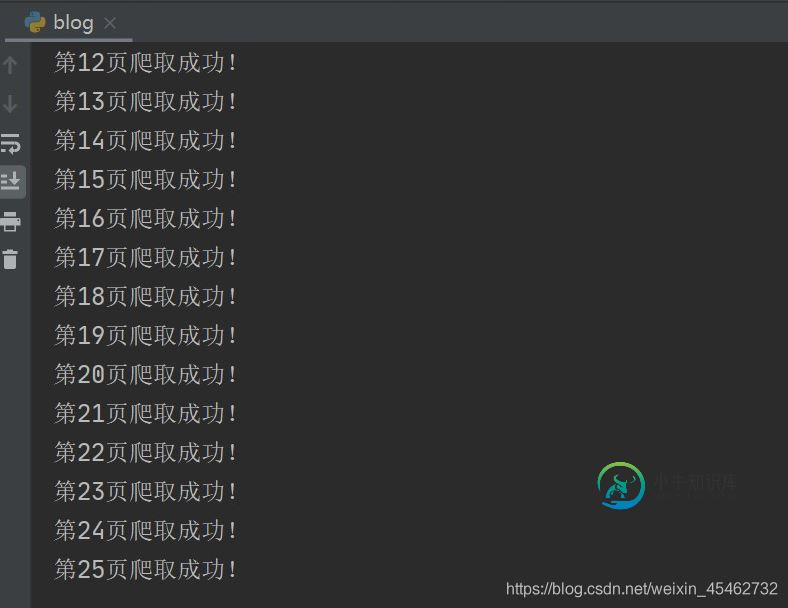
print('第'+page+'页爬取成功!')
注意一下这里,由于我们需要的是多张页面的数据,所以在发送请求的url中我们就要针对不同的页面发送请求,https://q.cnblogs.com/list/unsolved?page=我们要做的是在发送请求的url时候,根据参数来填充页数page,
代码实现:
url = 'https://q.cnblogs.com/list/unsolved?'
for page in range(1,26):
page = str(page)
param = {
'page':page
}
page_text = requests.get(url=url,params=param,headers=headers).text
将所有的h2数组拿到,进行遍历,通过取出h2中a标签中的文本,并将每取出来的文本写入到文件中,由于要遍历多次,所以保存文件在上面的代码中。
text_list = page_soup.select('.one_entity > .news_item > h2') for h2 in text_list: text = h2.a.string fp.write(text+'\n')
完整代码如下:
import requests
from bs4 import BeautifulSoup
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 87.0.4280.141Safari / 537.36'
}
url = 'https://q.cnblogs.com/list/unsolved?'
fp = open('blog', 'w', encoding='utf-8')
for page in range(1,26):
page = str(page)
param = {
'page':page
}
page_text = requests.get(url=url,params=param,headers=headers).text
page_soup = BeautifulSoup(page_text,'lxml')
text_list = page_soup.select('.one_entity > .news_item > h2')
for h2 in text_list:
text = h2.a.string
fp.write(text+'\n')
print('第'+page+'页爬取成功!')
四.运行结果
运行代码:
到此这篇关于详解Python爬虫爬取博客园问题列表所有的问题的文章就介绍到这了,更多相关Python爬虫爬取列表内容请搜索小牛知识库以前的文章或继续浏览下面的相关文章希望大家以后多多支持小牛知识库!
-
python爬虫时显示 [WinError 10061] 由于目标计算机积极拒绝,无法连接。 import csv import random import time import pandas as pd import requests from bs4 import BeautifulSoup import matplotlib.pyplot as plt plt.rcParams["font
-
本文向大家介绍Python爬虫爬取博客实现可视化过程解析,包括了Python爬虫爬取博客实现可视化过程解析的使用技巧和注意事项,需要的朋友参考一下 源码: 爬虫不是重点,只是拿来爬阅读数量,pyecharts是重点 这次爬的是我自己的博客,一共10页,每页10片文章,正好写了100篇博客 pyecharts安装: pip install wheelpip install pyecharts==0.
-
本文向大家介绍Python爬虫爬取新闻资讯案例详解,包括了Python爬虫爬取新闻资讯案例详解的使用技巧和注意事项,需要的朋友参考一下 前言 本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。 一个简单的Python资讯采集案例,列表页到详情页,到数据保存,保存为txt文档,网站网页结构算是比较规整,简单清晰明了,资讯新闻内容的采
-
本文向大家介绍如何使用python爬取csdn博客访问量,包括了如何使用python爬取csdn博客访问量的使用技巧和注意事项,需要的朋友参考一下 最近学习了python和爬虫,想写一个程序练练手,所以我就想到了大家都比较关心的自己的博客访问量,使用python来获取自己博客的访问量,这也是后边我将要进行的项目的一部分,后边我会对博客的访问量进行分析,以折线图和饼图等可视化的方式展示自己博客被访问
-
我要把downstream_port传到tiktok_response_interceptor.py脚本, 我目前的方法是 tiktok_response_interceptor-9092.py tiktok_response_interceptor-9093.py tiktok_response_interceptor-9094.py 然后文件中也写死 这大概不是最好的方法
-
原始content: decode('utf-8')报错: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe8 in position 1: invalid continuation byte decode('utf-8', 'ignore'): decode('gbk', 'ignore'): decode('utf-16', 'ig