
Python爬虫爬取新闻资讯案例详解

前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
一个简单的Python资讯采集案例,列表页到详情页,到数据保存,保存为txt文档,网站网页结构算是比较规整,简单清晰明了,资讯新闻内容的采集和保存!
应用到的库
requests,time,re,UserAgent,etree
import requests,time,re
from fake_useragent import UserAgent
from lxml import etree
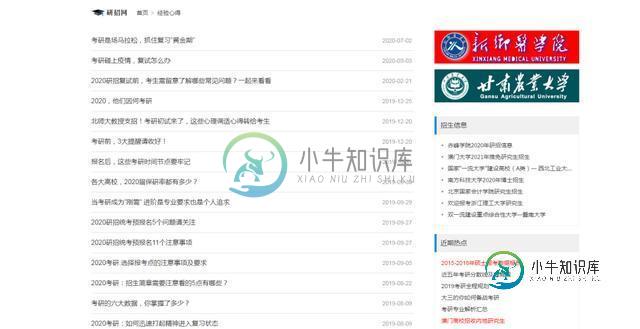
列表页面

列表页,链接xpath解析
href_list=req.xpath('//ul[@class="news-list"]/li/a/@href')
详情页
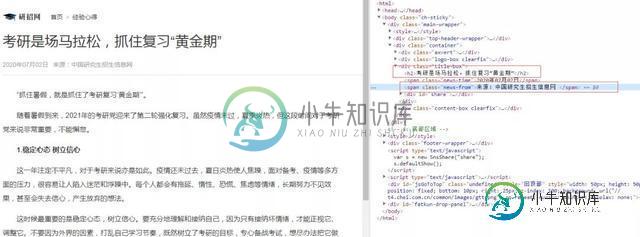

内容xpath解析
h2=req.xpath('//div[@class="title-box"]/h2/text()')[0]
author=req.xpath('//div[@class="title-box"]/span[@class="news-from"]/text()')[0]
details=req.xpath('//div[@class="content-l detail"]/p/text()')
内容格式化处理
detail='\n'.join(details)
标题格式化处理,替换非法字符
pattern = r"[\/\\\:\*\?\"\<\>\|]"
new_title = re.sub(pattern, "_", title) # 替换为下划线
保存数据,保存为txt文本
def save(self,h2, author, detail):
with open(f'{h2}.txt','w',encoding='utf-8') as f:
f.write('%s%s%s%s%s'%(h2,'\n',detail,'\n',author))print(f"保存{h2}.txt文本成功!")
遍历数据采集,yield处理
def get_tasks(self):
data_list = self.parse_home_list(self.url)
for item in data_list:
yield item
程序运行效果

程序采集效果
附源码参考:
# -*- coding: UTF-8 -*- import requests,time,re from fake_useragent import UserAgent from lxml import etree class RandomHeaders(object): ua=UserAgent() @property def random_headers(self): return { 'User-Agent': self.ua.random, } class Spider(RandomHeaders): def __init__(self,url): self.url=url def parse_home_list(self,url): response=requests.get(url,headers=self.random_headers).content.decode('utf-8') req=etree.HTML(response) href_list=req.xpath('//ul[@class="news-list"]/li/a/@href') print(href_list) for href in href_list: item = self.parse_detail(f'https://yz.chsi.com.cn{href}') yield item def parse_detail(self,url): print(f">>正在爬取{url}") try: response = requests.get(url, headers=self.random_headers).content.decode('utf-8') time.sleep(2) except Exception as e: print(e.args) self.parse_detail(url) else: req = etree.HTML(response) try: h2=req.xpath('//div[@class="title-box"]/h2/text()')[0] h2=self.validate_title(h2) author=req.xpath('//div[@class="title-box"]/span[@class="news-from"]/text()')[0] details=req.xpath('//div[@class="content-l detail"]/p/text()') detail='\n'.join(details) print(h2, author, detail) self.save(h2, author, detail) return h2, author, detail except IndexError: print(">>>采集出错需延时,5s后重试..") time.sleep(5) self.parse_detail(url) @staticmethod def validate_title(title): pattern = r"[\/\\\:\*\?\"\<\>\|]" new_title = re.sub(pattern, "_", title) # 替换为下划线 return new_title def save(self,h2, author, detail): with open(f'{h2}.txt','w',encoding='utf-8') as f: f.write('%s%s%s%s%s'%(h2,'\n',detail,'\n',author)) print(f"保存{h2}.txt文本成功!") def get_tasks(self): data_list = self.parse_home_list(self.url) for item in data_list: yield item if __name__=="__main__": url="https://yz.chsi.com.cn/kyzx/jyxd/" spider=Spider(url) for data in spider.get_tasks(): print(data)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍python爬虫线程池案例详解(梨视频短视频爬取),包括了python爬虫线程池案例详解(梨视频短视频爬取)的使用技巧和注意事项,需要的朋友参考一下 python爬虫-梨视频短视频爬取(线程池) 示例代码 知识点扩展: Python爬虫下载视频(梨视频) 梨视频示例:Ctrl+Alt+L格式化代码 到此这篇关于python爬虫线程池案例详解(梨视频短视频爬取)的文章就介绍到这了,更多
-
本文向大家介绍python 中xpath爬虫实例详解,包括了python 中xpath爬虫实例详解的使用技巧和注意事项,需要的朋友参考一下 案例一: 某套图网站,套图以封面形式展现在页面,需要依次点击套图,点击广告盘链接,最后到达百度网盘展示页面。 这一过程通过爬虫来实现,收集百度网盘地址和提取码,采用xpath爬虫技术 1、首先分析图片列表页,该页按照更新先后顺序暂时套图封面,查看HTML结构。
-
本文向大家介绍Python爬虫爬取、解析数据操作示例,包括了Python爬虫爬取、解析数据操作示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫爬取、解析数据操作。分享给大家供大家参考,具体如下: 爬虫 当当网 http://search.dangdang.com/?key=python&act=input&page_index=1 获取书籍相关信息 面向对象思想 利用不
-
任务:爬取腾讯网中关于指定条件的所有社会招聘信息,搜索条件为北京地区,Python关键字的就业岗位,并将信息存储到MySql数据库中。 网址:https://hr.tencent.com/position.php?keywords=python&lid=2156 实现思路:首先爬取每页的招聘信息列表,再爬取对应的招聘详情信息 ① 创建项目 在命令行编写下面命令,创建项目tencent scrapy
-
本文向大家介绍python爬虫爬取淘宝商品信息,包括了python爬虫爬取淘宝商品信息的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 效果图: 更多内容请参考专题《python爬取功能汇总》进行学习。 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
有的时候,当我们的爬虫程序完成了,并且在本地测试也没有问题,爬取了一段时间之后突然就发现报错无法抓取页面内容了。这个时候,我们很有可能是遇到了网站的反爬虫拦截。 我们知道,网站一方面想要爬虫爬取网站,比如让搜索引擎爬虫去爬取网站的内容,来增加网站的搜索排名。另一方面,由于网站的服务器资源有限,过多的非真实的用户对网站的大量访问,会增加运营成本和服务器负担。 因此,有些网站会设置一些反爬虫的措施。我