使用 bs4 的爬虫
我们以 亚马逊Kindle电子书销售排行榜 商品页面来做演示:https://www.amazon.cn/gp/bestsellers/digital-text/116169071
使用BeautifuSoup4解析器,将每件商品的的ASIN、标题、价格、star、评价数量,以及每件商品的链接爬取下来并存储在.csv文件中。
import csv
import requests
from bs4 importBeautifulSoup
def amazon():
base_url ='https://www.amazon.cn'
url ='https://www.amazon.cn/gp/bestsellers/digital-text/116169071'
headers ={
'Connection':'keep-alive',
'Cache-Control':'max-age=0',
'Upgrade-Insecure-Requests':'1',
'DNT':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Accept':'image/webp,image/apng,image/*,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-HK,zh-CN;q=0.9,zh;q=0.8',
'Referer':'https://www.amazon.cn/gp/bestsellers/digital-text/116169071',
}
# 给亚马逊发送请求
session = requests.session()
session.get('https://www.amazon.com')
resHtml = session.get(url, headers=headers).content.decode('utf-8')
# 将获取的对象转化为bs4对象
html_soup =BeautifulSoup(resHtml,'lxml')
# 获取所有商品的标签
all_goods_li = html_soup.find('ol', id='zg-ordered-list').find_all('li','zg-item-immersion')
for li in all_goods_li:
# 准备一个空列表,用于储存商品信息
goods_info_list =[]
# 商品链接
link = base_url + li.find('a', target='_blank')['href']
# 商品 asin
asin = link.split('/dp/')[1].split('/')[0]
# 标题
title = li.select("div[data-rows='1']")[0].get_text().strip()
# 价格
price = li.find('span','p13n-sc-price').text
# 星级
star = li.find('span','a-icon-alt').text
# 评价数
reviews = li.select("a[class='a-size-small a-link-normal']")[0].get_text()
# 将爬到的数据添加到列表中
goods_info_list.append(asin)
goods_info_list.append(title)
goods_info_list.append(price)
goods_info_list.append(star)
goods_info_list.append(reviews)
goods_info_list.append(link)
# 将数据写入 名为amazon_book.csv的文件中
csvFile = open('./amazon_book.csv','a', newline='', encoding='gb18030')# 设置newline,否则两行之间会空一行
writer = csv.writer(csvFile)
writer.writerow(goods_info_list)
csvFile.close()
if __name__ =='__main__':
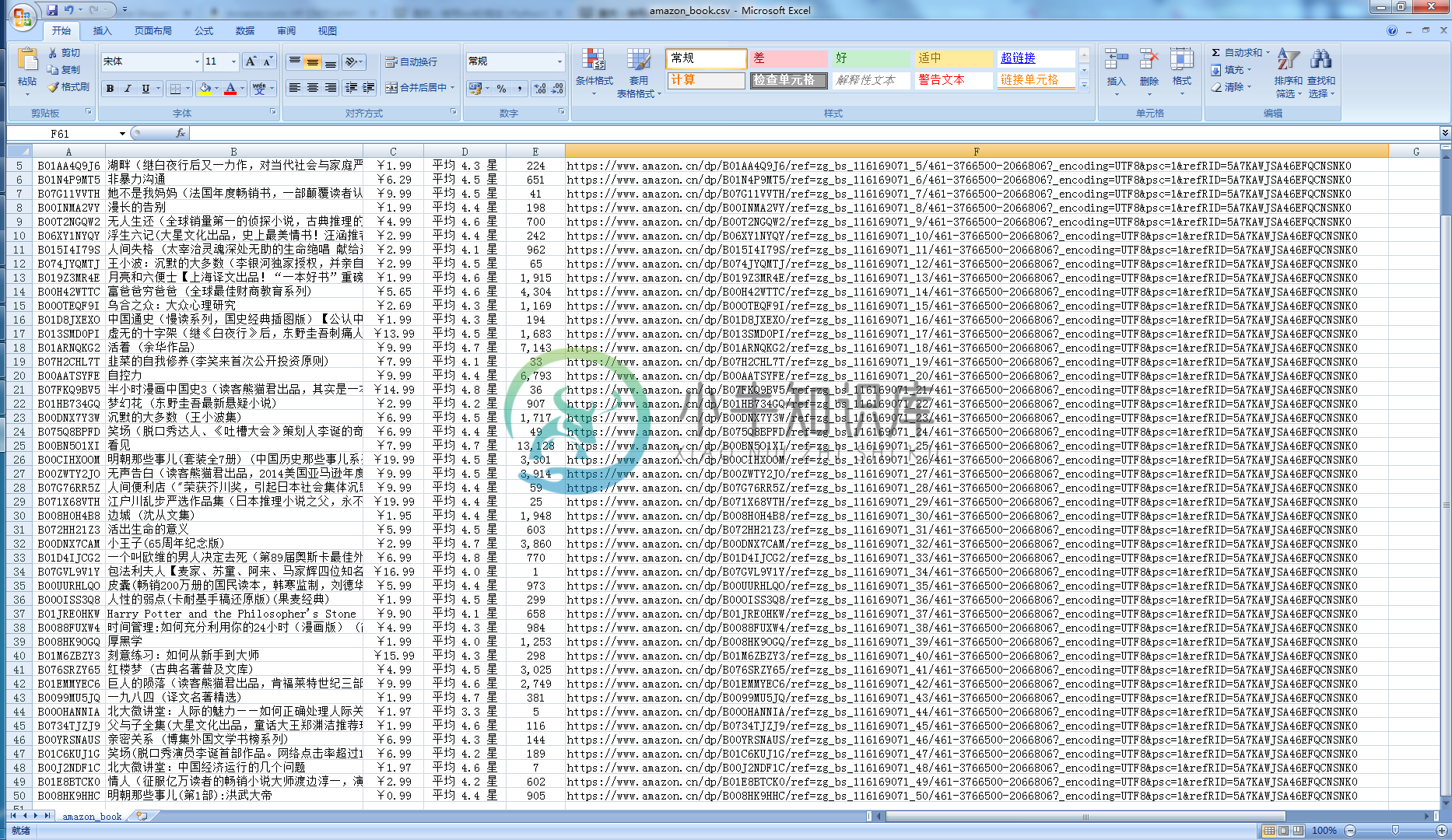
amazon()打开当前目录下的 amazon_book.csv 可见如图效果: