
5、常见的反爬手段和解决思路
1. 明确反反爬的主要思路
反反爬的主要思路就是:尽可能的去模拟浏览器,浏览器在如何操作,代码中就如何去实现。浏览器先请求了地址url1,保留了cookie在本地,之后请求地址url2,带上了之前的cookie,代码中也可以这样去实现。
很多时候,爬虫中携带的headers字段,cookie字段,url参数,post的参数很多,不清楚哪些有用,哪些没用的情况下,只能够去尝试,因为每个网站都是不相同的。当然在盲目尝试之前,可以参考别人的思路,我们自己也应该有一套尝试的流程。
2.通过headers字段来反爬
2.1 通过headers中的User-Agent字段来反爬
通过User-Agent字段反爬的话,只需要给他在请求之前添加User-Agent即可,更好的方式是使用User-Agent池来解决,我们可以考虑收集一堆User-Agent的方式,或者是随机生成User-Agent
import random
def get_ua():
first_num = random.randint(55,62)
third_num = random.randint(0,3200)
fourth_num = random.randint(0,140)
os_type =[
'(Windows NT 6.1; WOW64)','(Windows NT 10.0; WOW64)','(X11; Linux x86_64)',
'(Macintosh; Intel Mac OS X 10_12_6)'
]
chrome_version ='Chrome/{}.0.{}.{}'.format(first_num, third_num, fourth_num)
ua =' '.join(['Mozilla/5.0', random.choice(os_type),'AppleWebKit/537.36',
'(KHTML, like Gecko)', chrome_version,'Safari/537.36']
)
return ua2.2 通过referer字段或者是其他字段来反爬
例如豆瓣电视剧中,通过referer字段来反爬,我们只需要添加上即可
2.3 通过cookie来反爬
如果目标网站不需要登录 每次请求带上前一次返回的cookie,比如requests模块的session
如果目标网站需要登录 准备多个账号,通过一个程序获取账号对应的cookie,组成cookie池,其他程序使用这些cookie
3.通过js来反爬
3.1 通过js实现跳转来反爬
在请求目标网站的时候,我们看到的似乎就请求了一个网站,然而实际上在成功请求目标网站之前,中间可能有通过js实现的跳转,我们肉眼不可见,这个时候可以通过点击perserve log按钮实现观察页面跳转情况
在这些请求中,如果请求数量很多,一般来讲,只有那些response中带cookie字段的请求是有用的,意味着通过这个请求,对方服务器有设置cookie到本地
3.2 通过js生成了请求参数
对应的需要分析js,观察加密的实现过程,通过js2py获取js的执行结果,或者使用selenium来实现
3.3 通过js实现了数据的加密
对应的需要分析js,观察加密的实现过程,通过js2py获取js的执行结果,或者使用selenium来实现
4. 通过验证码来反爬
通过打码平台或者是机器学习的方法识别验证码,其中打码平台廉价易用,更值得推荐。
5. 通过ip地址来反爬
同一个ip大量请求了对方服务器,有更大的可能性会被识别为爬虫,对应的通过购买高质量的ip的方式能够解决问题
6. 其他的反爬方式
6.1 通过自定义字体来反爬
下图来自猫眼电影电脑版
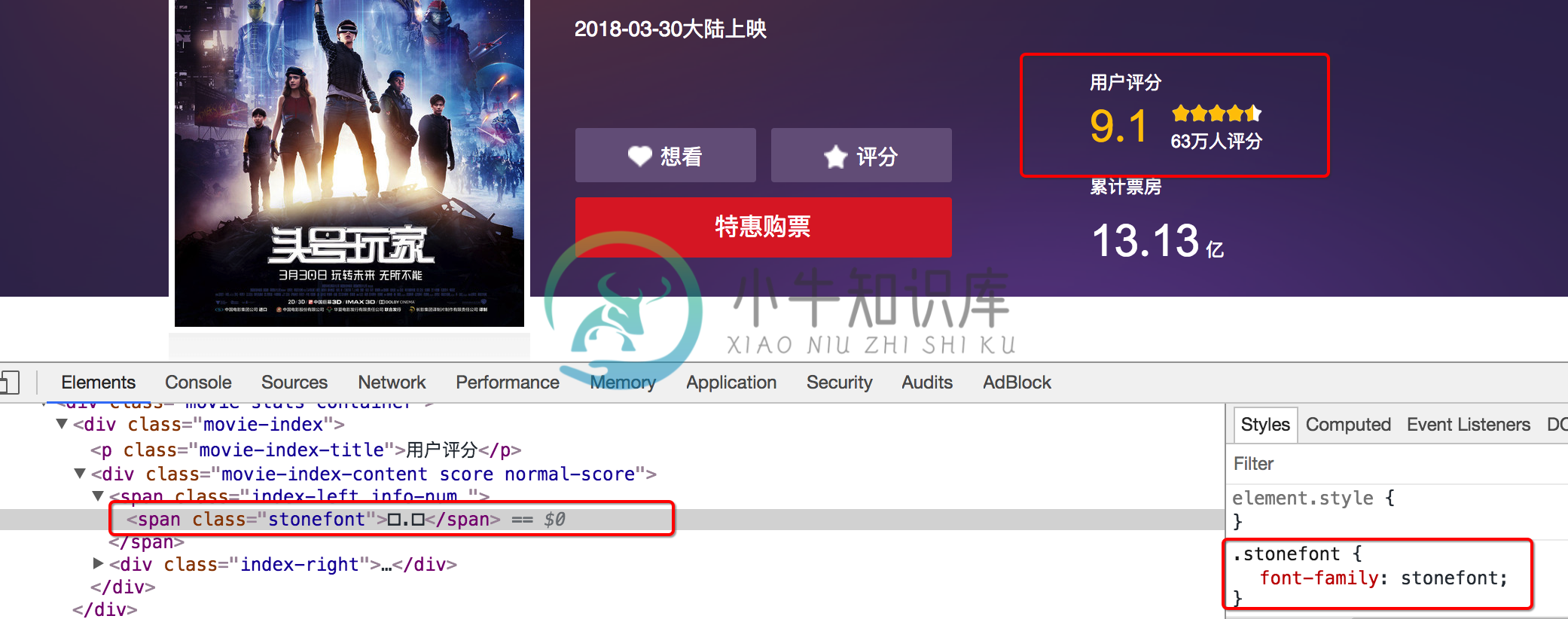
解决思路:切换到手机版
6.2 通过css来反爬
下图来自去哪儿电脑版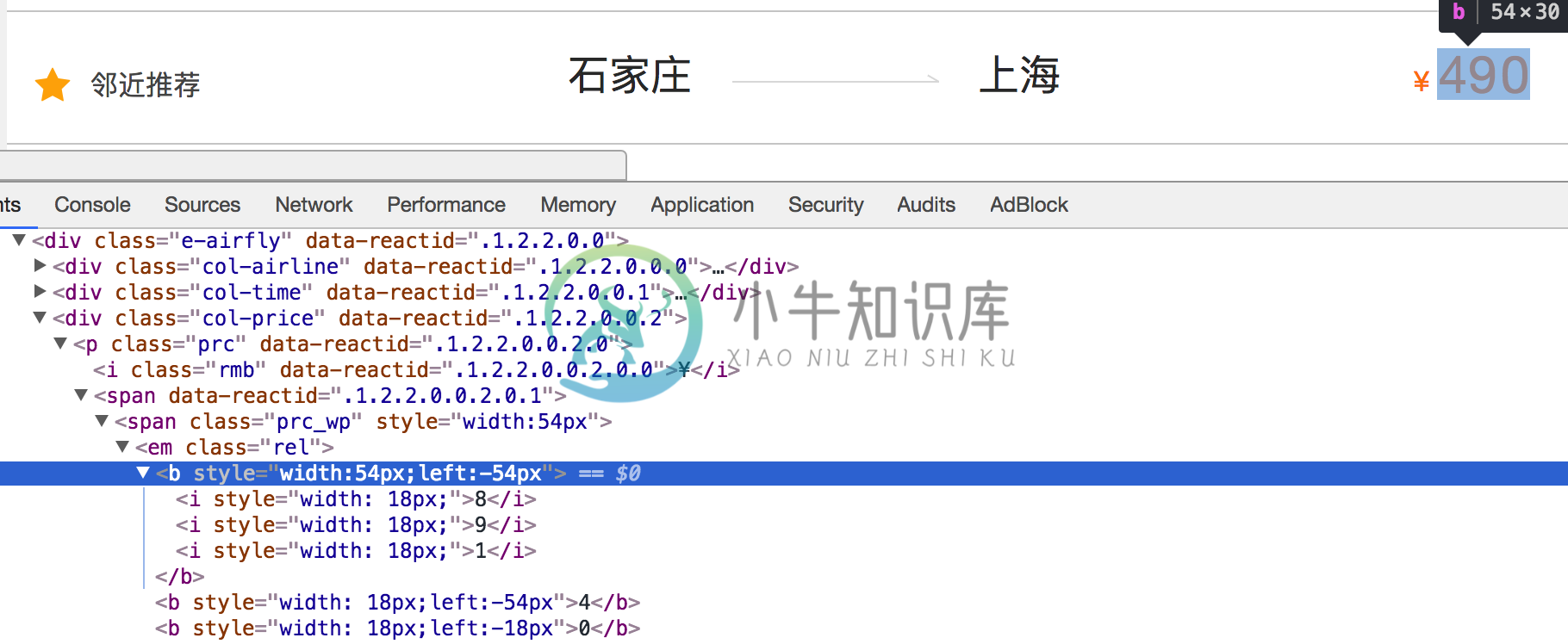
解决思路:计算css的偏移