《爬虫》专题
-
python爬虫入门教程之点点美女图片爬虫代码分享
本文向大家介绍python爬虫入门教程之点点美女图片爬虫代码分享,包括了python爬虫入门教程之点点美女图片爬虫代码分享的使用技巧和注意事项,需要的朋友参考一下 继续鼓捣爬虫,今天贴出一个代码,爬取点点网「美女」标签下的图片,原图。 使用方法:新建一个文件夹,把代码保存为name.py文件,运行python name.py就可以把图片下载到文件夹。
-
带爬行器的爬行器初始化中的参数
我想用蜘蛛爬虫代码来获取一些房地产数据。但它一直给我这个错误: 回溯(最近一次呼叫最后一次): 文件“//anaconda/lib/python2.7/site packages/twisted/internet/defer.py”,第1301行,in_inlineCallbacks result=g.send(result) 文件“//anaconda/lib/python2.7/site pa
-
python实现爬虫统计学校BBS男女比例之多线程爬虫(二)
本文向大家介绍python实现爬虫统计学校BBS男女比例之多线程爬虫(二),包括了python实现爬虫统计学校BBS男女比例之多线程爬虫(二)的使用技巧和注意事项,需要的朋友参考一下 接着第一篇继续学习。 一、数据分类 正确数据:id、性别、活动时间三者都有 放在这个文件里file1 = 'ruisi\\correct%s-%s.txt' % (startNum, endNum) 数据格式为293
-
Nutch 1.11爬网问题
我已经遵循了教程,并使用Cygwin将nutch配置为在Windows 7上运行,我正在使用Solr 5.4.0对数据进行索引 但是坚果1.11在执行爬行时遇到了问题。 爬网命令 $ bin/crawl -i -D solr.server.url= 错误/异常 注入种子网址 /apache-nutch-1.11/bin/坚果注射 /测试爬网/抓取 /urls 注射器:从 2016-01-19 开始
-
JavaScript算法-爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 注意:给定 n 是一个正整数。 示例 1: 输入: 2 输出: 2 解释: 有两种方法可以爬到楼顶。 1. 1 阶 + 1 阶 2. 2 阶 示例 2: 输入: 3 输出: 3 解释: 有三种方法可以爬到楼顶。 1. 1 阶 + 1 阶 + 1 阶 2. 1 阶 + 2
-
借助Firefox来爬取
这里介绍一些使用Firefox进行爬取的点子及建议,以及一些帮助爬取的Firefox实用插件。 在浏览器中检查DOM的注意事项 Firefox插件操作的是活动的浏览器DOM(live browser DOM),这意味着当您检查网页源码的时候, 其已经不是原始的HTML,而是经过浏览器清理并执行一些Javascript代码后的结果。 Firefox是个典型的例子,其会在table中添加 <tbody
-
去旅游爬虫运动麻烦
问题内容: 我正在进行巡回演出,我觉得除了并发以外,我对这种语言有很好的理解。 在幻灯片72上,有一个练习,要求读者并行化Web爬网程序(并使其不覆盖重复的内容,但我还没有到达那里。) 这是我到目前为止的内容: 我的问题是在哪里打电话。如果我在方法中的某个地方放置了一个对象,那么我最终会在其中一个生成的goroutine中写入一个封闭的通道,因为该方法将在生成的goroutine之前完成执行。 如
-
 NodeJS制作爬虫全过程(续)
NodeJS制作爬虫全过程(续)本文向大家介绍NodeJS制作爬虫全过程(续),包括了NodeJS制作爬虫全过程(续)的使用技巧和注意事项,需要的朋友参考一下 书接上回,我们需要修改程序以达到连续抓取40个页面的内容。也就是说我们需要输出每篇文章的标题、链接、第一条评论、评论用户和论坛积分。 如图所示,$('.reply_author').eq(0).text().trim();得到的值即为正确的第一条评论的用户。 {<1>}
-
nodeJs爬虫的技术点总结
本文向大家介绍nodeJs爬虫的技术点总结,包括了nodeJs爬虫的技术点总结的使用技巧和注意事项,需要的朋友参考一下 背景 最近打算把之前看过的nodeJs相关的内容在复习下,顺便写几个爬虫来打发无聊,在爬的过程中发现一些问题,记录下以便备忘。 依赖 用到的是在网上烂大街的cheerio库来处理爬取的内容,使用superagent处理请求,log4js来记录日志。 日志配置 话不多说,直接上代码
-
围棋之旅练习#10:爬虫
我正在进行围棋之旅,我觉得除了并发性之外,我对这门语言有很好的理解。 幻灯片10是一个练习,要求读者并行化一个网络爬虫(并使其不覆盖重复,但我还没有做到。) 以下是我到目前为止的情况: 我的问题是,在哪里我把调用。 如果我在方法中的某个地方放置了,那么程序最终会从一个派生的goroutine写入一个闭合通道,因为对的调用将在派生的goroutine执行之前返回。 如果我省略了对的调用,正如我所演示
-
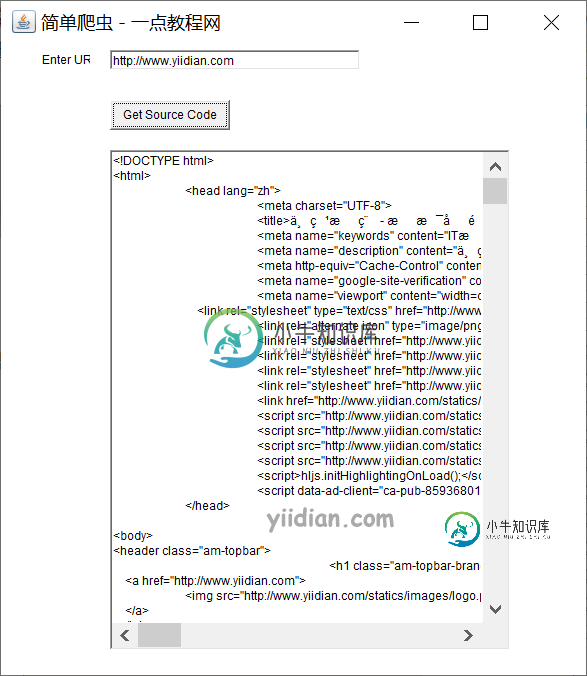 实战-Swing实现简单爬虫
实战-Swing实现简单爬虫主要内容:1 Swing实现简单爬虫1 Swing实现简单爬虫 我们可以借助网络,带有事件处理的Swing开发Java中的URL源代码生成器。让我们看一下用Java创建URL源代码生成器的代码。 核心代码: 让我们看一下生成URL源代码的代码。 输出结果为:
-
python scrapy爬虫代码及填坑
本文向大家介绍python scrapy爬虫代码及填坑,包括了python scrapy爬虫代码及填坑的使用技巧和注意事项,需要的朋友参考一下 涉及到详情页爬取 目录结构: kaoshi_bqg.py xmly.py item.py pipelines.py starts.py 然后是爬取到的数据 小说 xmly.json 记录一下爬取过程中遇到的一点点问题: 在爬取详情页的的时候, 刚开始不知道
-
 python 中xpath爬虫实例详解
python 中xpath爬虫实例详解本文向大家介绍python 中xpath爬虫实例详解,包括了python 中xpath爬虫实例详解的使用技巧和注意事项,需要的朋友参考一下 案例一: 某套图网站,套图以封面形式展现在页面,需要依次点击套图,点击广告盘链接,最后到达百度网盘展示页面。 这一过程通过爬虫来实现,收集百度网盘地址和提取码,采用xpath爬虫技术 1、首先分析图片列表页,该页按照更新先后顺序暂时套图封面,查看HTML结构。
-
 浅谈Python爬虫基本套路
浅谈Python爬虫基本套路本文向大家介绍浅谈Python爬虫基本套路,包括了浅谈Python爬虫基本套路的使用技巧和注意事项,需要的朋友参考一下 什么是爬虫? 网络爬虫也叫网络蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘蛛就是在网上爬来爬去的蜘蛛,爬虫程序通过请求url地址,根据响应的内容进行解析采集数据, 比如:如果响应内容是html,分析dom结构,进行dom解析、或者正则匹配,如果响应内容是xml/json数据,就可以
-
使用requests库制作Python爬虫
本文向大家介绍使用requests库制作Python爬虫,包括了使用requests库制作Python爬虫的使用技巧和注意事项,需要的朋友参考一下 使用python爬虫其实就是方便,它会有各种工具类供你来使用,很方便。Java不可以吗?也可以,使用httpclient工具、还有一个大神写的webmagic框架,这些都可以实现爬虫,只不过python集成工具库,使用几行爬取,而Java需要写更多的行