《爬虫》专题
-
Java Web爬网程序库
问题内容: 我想做一个基于Java的网络爬虫进行实验。我听说如果您是第一次使用Java编写Web爬虫,那是必须走的路。但是,我有两个重要问题。 我的程序如何“访问”或“连接”到网页?请简要说明。(我了解从硬件到软件的抽象层的基础,这里我对Java抽象感兴趣) 我应该使用哪些库?我假设我需要一个用于连接到网页的库,一个用于HTTP / HTTPS协议的库和一个用于HTML解析的库。 问题答案: 这是
-
python 爬取微信文章
本文向大家介绍python 爬取微信文章,包括了python 爬取微信文章的使用技巧和注意事项,需要的朋友参考一下 本人想搞个采集微信文章的网站,无奈实在从微信本生无法找到入口链接,网上翻看了大量的资料,发现大家的做法总体来说大同小异,都是以搜狗为入口。下文是笔者整理的一份python爬取微信文章的代码,有兴趣的欢迎阅读
-
Nutch爬行不起作用
我想使用Apache Nutch1.12爬网一个站点,并将数据索引到Apache Solr中。我已经遵循了这个教程。 我的seed.txt文件的url是http://nutch.apache.org/ 在我的regex url筛选器中,我有如下所示+^http://([a-z0-9]*.)*nutch.apache.org/ 当我试图获取数据时,我只得到seed.txt文件中的url。 我在这里错
-
使用Firebug进行爬取
注解 本教程所使用的样例站Google Directory已经 被Google关闭 了。不过教程中的概念任然适用。 如果您打算使用一个新的网站来更新本教程,您的贡献是再欢迎不过了。 详细信息请参考 Contributing to Scrapy 。 介绍 本文档介绍了如何适用 Firebug (一个Firefox的插件)来使得爬取更为简单,有趣。 更多有意思的Firefox插件请参考 对爬取有帮助的
-
18. App的信息爬取
之前我们讲解的都是Web网页信息爬取,随着移动互联的发展,越来越多的企业并没有提供Web网页端的服务,而是直接开发App。 App的爬取相比Web端爬取更加容易,反爬中能力没有那么强,而且响应数据大多都是JSON形式,解析更加简单。 在APP端若想查看和分析内容那就需要借助抓包软件,常用的有:Filddler、Charles、mitmproxy、Appium等。 mitmproxy是一个支持HTT
-
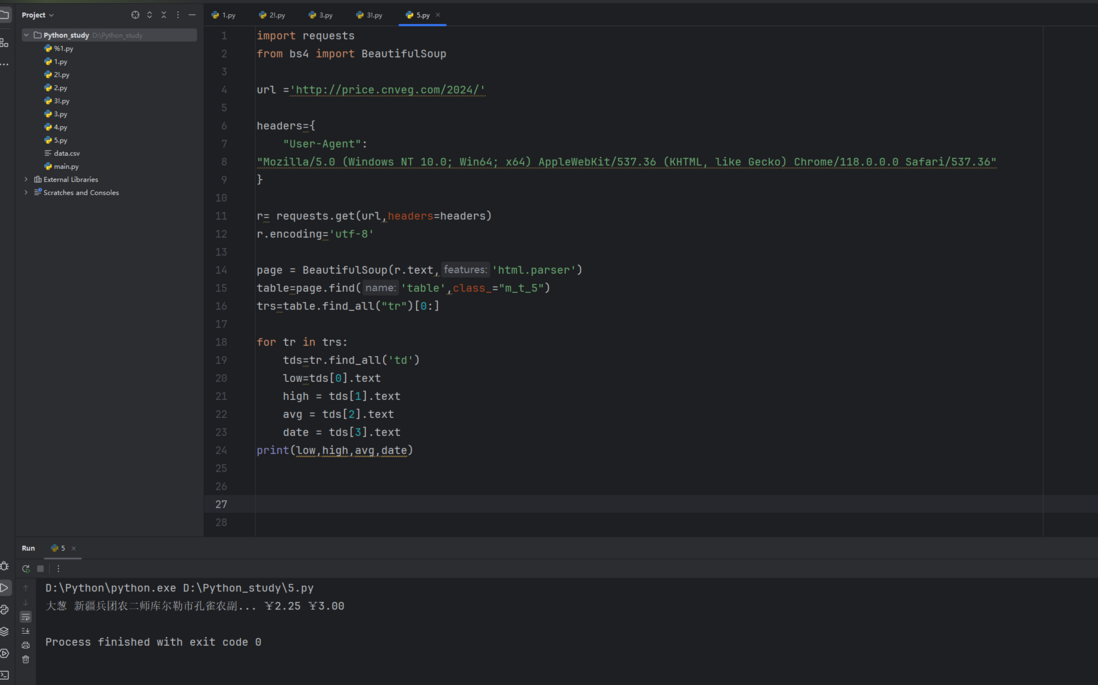 网络爬虫 - 如何解决爬虫切片时只能获取单个数据项的问题?
网络爬虫 - 如何解决爬虫切片时只能获取单个数据项的问题?我看做过切片所爬取的还是很全的
-
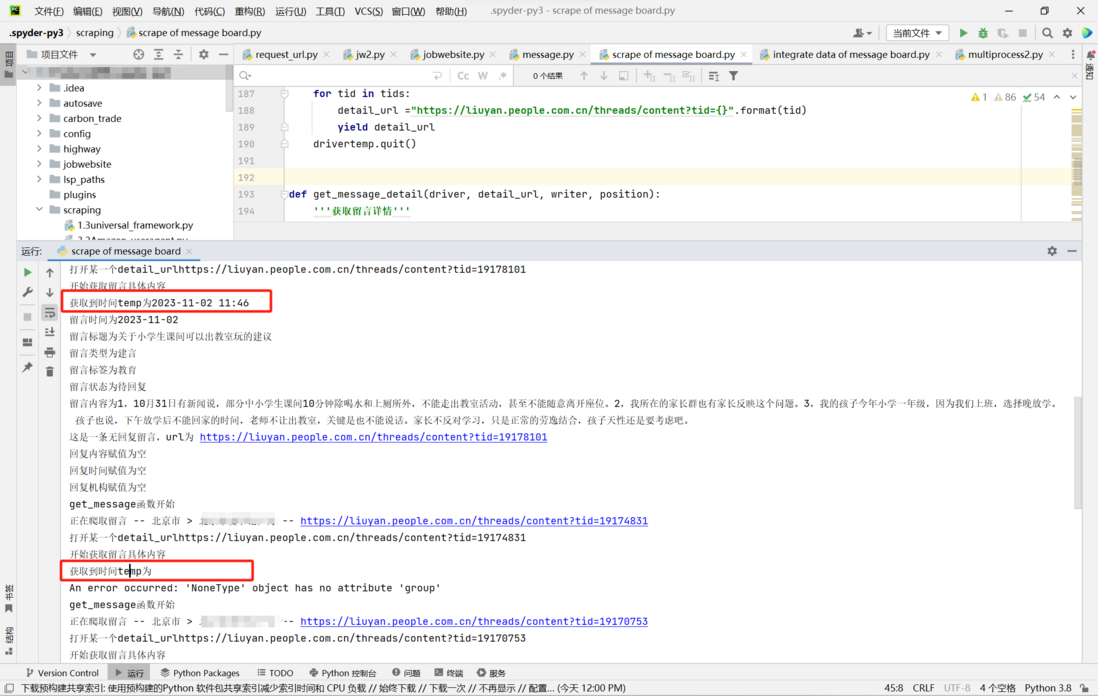 前端 - 爬虫爬取到标签内容有时为空有时正常,请问怎么解决?
前端 - 爬虫爬取到标签内容有时为空有时正常,请问怎么解决?在爬取人民网领导留言板数据时,在留言详情页面按照xpath提取留言时间的信息,但是有的留言可以提取出时间,有的留言提取出来是空,看起来非常随机,不明白这是为什么...当提取时间内容为空时,反复提取十几次,有时候是三十几次,又可以提取出来,不知道这是为什么?应该如何解决呢 此外不知道大家还有没有什么可以提高爬取速度的修改建议,或者可以实现爬取一部分存储一部分,中断后可以继续爬取不用从头再来的修改建议
-
 python爬虫神器Pyppeteer入门及使用
python爬虫神器Pyppeteer入门及使用本文向大家介绍python爬虫神器Pyppeteer入门及使用,包括了python爬虫神器Pyppeteer入门及使用的使用技巧和注意事项,需要的朋友参考一下 前言 提起selenium想必大家都不陌生,作为一款知名的Web自动化测试框架,selenium支持多款主流浏览器,提供了功能丰富的API接口,经常被我们用作爬虫工具来使用。但是selenium的缺点也很明显,比如速度太慢、对版本配置要求严
-
 Python 制作糗事百科爬虫实例
Python 制作糗事百科爬虫实例本文向大家介绍Python 制作糗事百科爬虫实例,包括了Python 制作糗事百科爬虫实例的使用技巧和注意事项,需要的朋友参考一下 早上起来闲来无事做,莫名其妙的就弹出了糗事百科的段子,转念一想既然你送上门来,那我就写个爬虫到你网站上爬一爬吧,一来当做练练手,二来也算找点乐子。 其实这两天也正在接触数据库的内容,可以将爬取下来的数据保存在数据库中,以待以后的利用。好了,废话不多说了,先来看看程序爬
-
 Node.js 实现简单小说爬虫实例
Node.js 实现简单小说爬虫实例本文向大家介绍Node.js 实现简单小说爬虫实例,包括了Node.js 实现简单小说爬虫实例的使用技巧和注意事项,需要的朋友参考一下 最近因为剧荒,老大追了爱奇艺的一部网剧,由丁墨的同名小说《美人为馅》改编,目前已经放出两季,虽然整部剧槽点满满,但是老大看得不亦乐乎,并且在看完第二季之后跟我要小说资源,直接要奔原著去看结局…… 随手搜了下,都是在线资源,下载的话需要登录,注册登录好麻烦,写个爬虫
-
 Python爬虫学习之翻译小程序
Python爬虫学习之翻译小程序本文向大家介绍Python爬虫学习之翻译小程序,包括了Python爬虫学习之翻译小程序的使用技巧和注意事项,需要的朋友参考一下 本次博客分享的内容为基于有道在线翻译实现一个实时翻译小程序,本次任务是参考小甲鱼的书《零基础入门学习Python》完成的,书中代码对于当前的有道词典并不适用,使用后无法实现翻译功能,在网上进行学习之后解决了这一问题。 2、前置工作 1)由于有道在线翻译是“反爬虫”的,所以
-
最佳爬虫确定与技术构建?
BuiltWith.com和类似的服务提供(收费)使用SalesForce或NationBuilder等特定技术构建的域列表。有一些我感兴趣的技术builtwith没有扫描,可能是因为它们的市场份额太小。 如果我们知道某个网站使用了某种技术的页面签名,那么识别尽可能多的这些网站的最佳方法是什么?我们希望有1000个,我们对那些在前1000万网站的流量感兴趣。(我们不认为最大的网站使用这种技术。)
-
Queue 示例 - 一个并发网络爬虫
Tornado 的 模块对于协程实现了异步的 生产者 / 消费者 模型, 实现了类似于 Python 标准库中线程中的 模块. 一个协程 yield 将会在队列中有值时暂停. 如果队列设置了最大值, 协程会 yield 暂停直到有空间来存放. 从零开始维护了一系列未完成的任务. 增加计数; 来减少它. 在这个网络爬虫的例子中, 队列开始仅包含 base_url. 当一个 worker 获取一个页面
-
python爬虫面试宝典(常见问题)
本文向大家介绍python爬虫面试宝典(常见问题),包括了python爬虫面试宝典(常见问题)的使用技巧和注意事项,需要的朋友参考一下 是否了解线程的同步和异步? 线程同步:多个线程同时访问同一资源,等待资源访问结束,浪费时间,效率低 线程异步:在访问资源时在空闲等待时同时访问其他资源,实现多线程机制 是否了解网络的同步和异步? 同步:提交请求->等待服务器处理->处理完毕返回 这个期间客户端浏览
-
 python3制作捧腹网段子页爬虫
python3制作捧腹网段子页爬虫本文向大家介绍python3制作捧腹网段子页爬虫,包括了python3制作捧腹网段子页爬虫的使用技巧和注意事项,需要的朋友参考一下 0x01 春节闲着没事(是有多闲),就写了个简单的程序,来爬点笑话看,顺带记录下写程序的过程。第一次接触爬虫是看了这么一个帖子,一个逗逼,爬取煎蛋网上妹子的照片,简直不要太方便。于是乎就自己照猫画虎,抓了点图片。 科技启迪未来,身为一个程序员,怎么能干这种事呢,还是爬