《爬虫》专题
-
 宇润爬虫框架 Yurun Crawler 帮助文档
宇润爬虫框架 Yurun Crawler 帮助文档宇润爬虫框架 Yurun Crawler 是一个低代码、高性能、分布式爬虫采集框架,基于 imi 框架开发,运行在 Swoole 常驻内存的协程环境。
-
python cookie反爬处理的实现
本文向大家介绍python cookie反爬处理的实现,包括了python cookie反爬处理的实现的使用技巧和注意事项,需要的朋友参考一下 Cookies的处理 作用 保存客户端的相关状态 在爬虫中如果遇到了cookie的反爬如何处理? 手动处理 在抓包工具中捕获cookie,将其封装在headers中 应用场景:cookie没有有效时长且不是动态变化 自动处理 使用sess
-
在Jmeter的线程组中爬升
我对在JMeter中设置斜坡有异议。 下面描述了我的测试场景。 null
-
 python动态网页批量爬取
python动态网页批量爬取本文向大家介绍python动态网页批量爬取,包括了python动态网页批量爬取的使用技巧和注意事项,需要的朋友参考一下 四六级成绩查询网站我所知道的有两个:学信网(http://www.chsi.com.cn/cet/)和99宿舍(http://cet.99sushe.com/),这两个网站采用的都是动态网页。我使用的是学信网,好了,网站截图如下: 网站的代码
-
python爬取51job中hr的邮箱
本文向大家介绍python爬取51job中hr的邮箱,包括了python爬取51job中hr的邮箱的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了python爬取51job中hr的邮箱具体代码,供大家参考,具体内容如下 city_list大家自己整理一下,只能帮你们到这里了,谢谢大家的阅读,继续关注呐喊教程更多精彩内容。
-
 详解python 爬取12306验证码
详解python 爬取12306验证码本文向大家介绍详解python 爬取12306验证码,包括了详解python 爬取12306验证码的使用技巧和注意事项,需要的朋友参考一下 一个简单的验证码爬取程序 本文介绍了在Python2.7环境下爬取网站验证码: 思路就是获取验证码对应的url,然后发起requst请求,读取该URL对应的内容,然后写入到一个本地文件,实现一个验证码的保存。大量下载可以把以上程序写入一个死循环 代码实现部分:
-
 Python编码爬坑指南(必看)
Python编码爬坑指南(必看)本文向大家介绍Python编码爬坑指南(必看),包括了Python编码爬坑指南(必看)的使用技巧和注意事项,需要的朋友参考一下 自己最近有在学习python,这实在是一门非常短小精悍的语言,很喜欢这种语言精悍背后又有强大函数库支撑的语言。可是刚接触不久就遇到了让人头疼的关于编码的问题,在网上查了很多资料现在在这里做一番总结,权当一个记录也为后来的兄弟姐妹们服务,如果可以让您少走一些弯路本人将倍感荣
-
使角度爬网-项目开始
问题内容: 使用angularJS开发网站时,在开始使用网站之前,您是否需要担心Web爬网程序,还是可以将其推迟到网站完成。 例如,我读过HTML快照是一个很好的解决方案。如果选择执行此操作,则可以在对网站进行编码后实现它,还是必须基于这种功能来创建网站。 问题答案: 我认为在项目开始时考虑该策略并在项目结束时实施该策略是很好的。 我们在我正在工作的公司中遇到了问题。 在所有情况下,您都需要向GE
-
 详解Vue爬坑之vuex初识
详解Vue爬坑之vuex初识本文向大家介绍详解Vue爬坑之vuex初识,包括了详解Vue爬坑之vuex初识的使用技巧和注意事项,需要的朋友参考一下 在 Vue.js 的项目中,如果项目结构简单, 父子组件之间的数据传递可以使用 props 或者 $emit 等方式. 但是如果是大型项目,很多时候都需要在子组件之间传递数据,使用之前的方式就不太方便。Vue 的状态管理工具 Vuex 完美的解决了这个问题。 一、安装并引入
-
Python使用Scrapy爬取妹子图
本文向大家介绍Python使用Scrapy爬取妹子图,包括了Python使用Scrapy爬取妹子图的使用技巧和注意事项,需要的朋友参考一下 Python Scrapy爬虫,听说妹子图挺火,我整站爬取了,上周一共搞了大概8000多张图片。和大家分享一下。 核心爬虫代码 项目地址:https://github.com/ZhangBohan/fun_crawler 以上所述就是本文的全部内容了,希望大家
-
刮痕爬行蜘蛛不连接
我在这里和其他网站上读了很多关于scrapy的文章,但我无法解决这个问题,所以我问你:P希望有人能帮助我。 我想在主客户端页面中验证登录名,然后解析所有类别和所有产品,并保存产品的标题、类别、数量和价格。 我的代码: 当我在终端上运行scrapy爬行蜘蛛时,我得到以下信息: 刮痒的)pi@raspberry:~/SCRAPY/combatzone/combatzone/spiders$SCRAPY
-
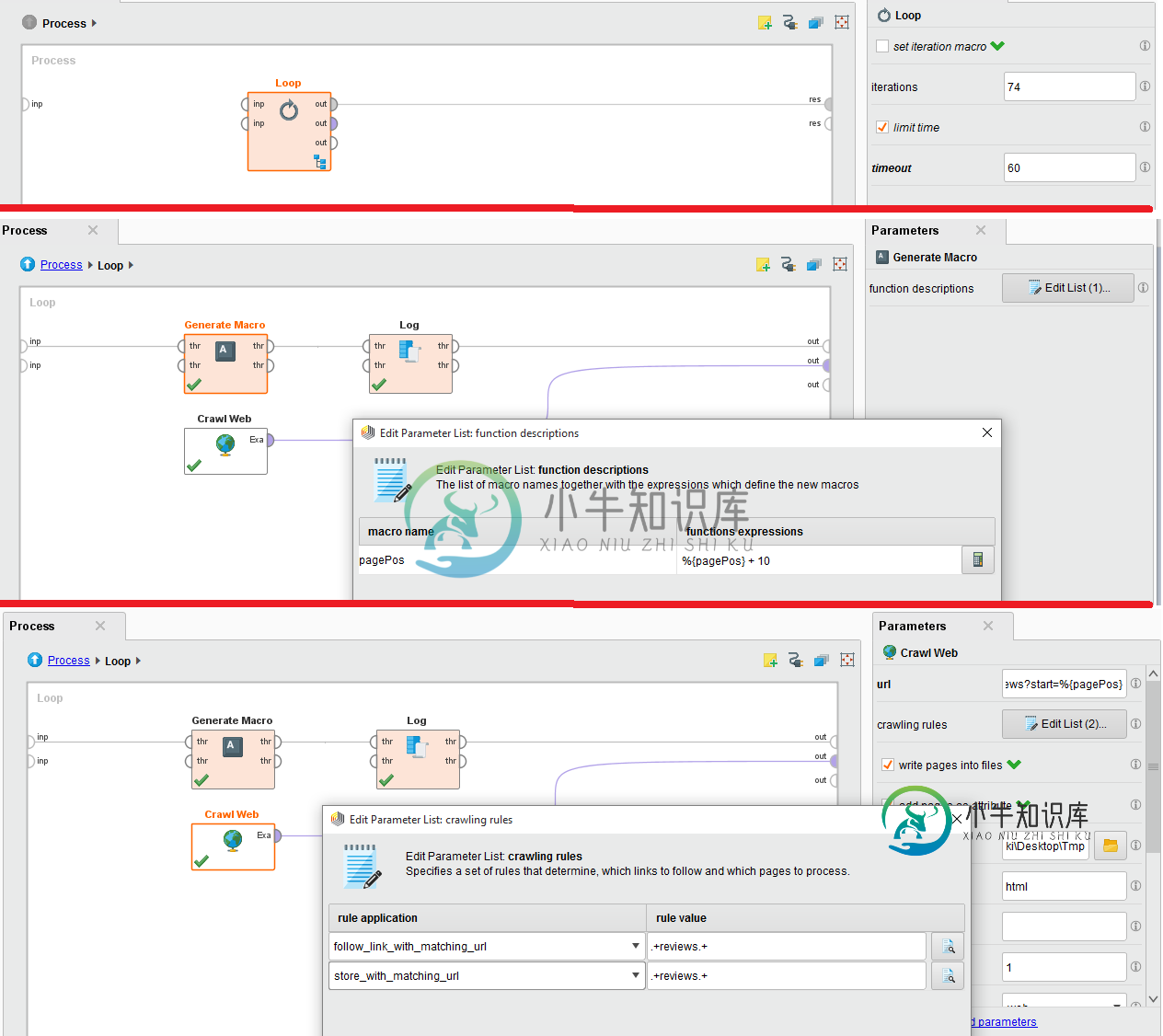 Rapid Miner不保存爬网结果
Rapid Miner不保存爬网结果我试图从IMDB网站抓取特定电影评论的评论。为此,我使用抓取网络,我有内嵌循环,因为有74个页面。 附件是配置的图像。请帮忙。我深陷其中。 爬网网站的URL为:http://www.imdb.com/title/tt0454876/reviews?start=%{pagePos}
-
教你用Python爬取表情包
“表情包”是一种利用图片来表示感情的一种方式。表情包是在社交软件活跃之后,形成的一种流行文化,表情包流行于互联网上面,基本人人都会发表情。 曾经你是否也有过找不到表情包去应对别人的时候。别担心~ 今天小编将分享如何用Python爬取批量表情包,想用什么表情包搜一下就有了!
-
16. 图片信息爬取实战
案例分析 任务:爬取京东指定商品图片信息,并存储在当期目录下。 url地址:https://list.jd.com/list.html?cat=9987,653,655 分析Web的响应内容,并作出对应处理准备: 具体实现代码: import requests from bs4 import BeautifulSoup from urllib.request import urlretrieve
-
 基于nodejs 的多页面爬虫实例代码
基于nodejs 的多页面爬虫实例代码本文向大家介绍基于nodejs 的多页面爬虫实例代码,包括了基于nodejs 的多页面爬虫实例代码的使用技巧和注意事项,需要的朋友参考一下 前言 前端时间再回顾了一下node.js,于是顺势做了一个爬虫来加深自己对node的理解。 主要用的到是request,cheerio,async三个模块 request 用于请求地址和快速下载图片流。 https://github.com/request/r