《爬虫》专题
-
Scrapy爬虫提取URL,但错过了一半回调
我在尝试刮取此URL时遇到了一个奇怪的问题: 为了执行爬行,我设计了这个: 我从命令行启动spider,我可以看到URL通常被删除,但是,对于其中一些URL,回调不起作用(大约一半的URL通常被删除)。 由于此页面上有150多个链接,这可能解释了爬虫程序缺少回调(太多作业)的原因。你们中的一些人对此有什么想法吗? 这是日志: 2015-12-25 09:02:55[scrapy]信息:存储在中的c
-
Python爬取读者并制作成PDF
本文向大家介绍Python爬取读者并制作成PDF,包括了Python爬取读者并制作成PDF的使用技巧和注意事项,需要的朋友参考一下 学了下beautifulsoup后,做个个网络爬虫,爬取读者杂志并用reportlab制作成pdf.. crawler.py getpdf.py 以上就是本文的全部内容了,希望大家能够喜欢。
-
T-SQL Puzzler-爬行对象依赖项
问题内容: 此代码涉及一个递归存储过程调用和一种避免游标名称冲突的“不太好”的方法。最后,我不在乎它是否使用游标。只是在寻找最优雅的方法。我主要将其用作跟踪Stored Proc层次结构的简单方法(无需购买产品)。我在“动态sql”中尝试了游标,但运气不佳。我想深入十个层次。 所需的输出: 它不是很漂亮,但是这里是代码(它没有按预期工作) 问题答案: 对于ms sql服务器,您可以使用CURSOR
-
谷歌爬网503服务不可用
当我在我的服务器上用wget、curl或python爬行谷歌搜索引擎时,我遇到了一个非常奇怪的问题。Google将我重定向到以[ipv4 | ipv6]开头的地址。谷歌。fr/抱歉/索引重定向。。。最后发送503错误,服务不可用。。。 有时抓取工作正常,有时不是在白天,我尝试了几乎所有可能的方法:强制ipv4/ipv6而不是主机名、引用者、用户代理、vpn、. com/. fr/、代理和tor,.
-
python爬取NUS-WIDE数据库图片
本文向大家介绍python爬取NUS-WIDE数据库图片,包括了python爬取NUS-WIDE数据库图片的使用技巧和注意事项,需要的朋友参考一下 实验室需要NUS-WIDE数据库中的原图,数据集的地址为http://lms.comp.nus.edu.sg/research/NUS-WIDE.htm 由于这个数据只给了每个图片的URL,所以需要一个小爬虫程序来爬取这些图片。在图片的下载过程中建
-
如何解决段:爬网/段/*错误
在点击此链接时,我收到此错误,但无法弄清楚它 http://wiki.apache.org/nutch/NutchTutorial runtime/local$bin/nutch parse$s1 ParseSegment:开始于2013-10-11 17:43:36 ParseSemment:segment:craw/segments/20131011173126线程“main”java.io.
-
执行爬网时出现Nutch问题
我正在尝试让nutch 1.11执行爬网。我正在使用cygwin在windows 7中运行这些命令。 Nutch正在运行,运行bin/Nutch会得到结果,但当我尝试运行爬网时,会不断收到错误消息。 当我尝试使用 nutch 运行爬网执行时,我收到以下错误: 运行时出错:/cygdrive/c/Users/User5/Documents/Nutch/apache-Nutch-1.11/runtim
-
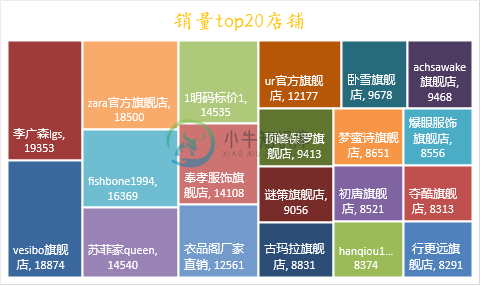 用Python爬取某宝商品数据
用Python爬取某宝商品数据数据采集是数据可视化分析的第一步,也是最基础的一步,数据采集的数量和质量越高,后面分析的准确的也就越高,我们来看一下淘宝网的数据该如何爬取。 淘宝网站是一个动态加载的网站,我们之前可以采用解析接口或者用Selenium自动化测试工具来爬取数据,但是现在淘宝对接口进行了加密,使我们很难分析出来其中的规律,同时淘宝也对Selenium进行了反爬限制,所以我们要换种思路来进行数据获取。
-
26. 使用web展示爬取信息
26.1 创建项目myweb和应用web # 创建项目框架myweb $ django-admin startproject myweb $ cd myweb # 在项目中创建一个web应用 $ python3 manage.py startapp web # 创建模板目录 $ mkdir templates $ mkdir t
-
12. POST请求爬取数据实战
import json json.loads(json_str) # json字符串转换成字典 json.dumps(dict) # 字典转换成json字符串 使用urllib发送POST数据,并抓取百度翻译信息 from urllib import request,parse import json url = 'http://fanyi.baidu.com/sug' # 定义
-
11. GET请求爬取数据实战
使用urllib的GET获取58同城中关于python的招聘信息 from urllib import request from urllib import error import re url = "http://bj.58.com/job/?key=python&final=1&jump=1" req = request.Request(url) try: response = r
-
第十五章 爬取维基百科
在本章中,我展示了上一个练习的解决方案,并分析了 Web 索引算法的性能。然后我们构建一个简单的 Web 爬虫。 15.1 基于 Redis 的索引器 在我的解决方案中,我们在 Redis 中存储两种结构: 对于每个检索词,我们有一个URLSet,它是一个 Redis 集合,包含检索词的 URL。 对于每个网址,我们有一个TermCounter,这是一个 Redis 哈希表,将每个检索词映射到它出
-
Python爬虫正则表达式常用符号和方法
本文向大家介绍Python爬虫正则表达式常用符号和方法,包括了Python爬虫正则表达式常用符号和方法的使用技巧和注意事项,需要的朋友参考一下 正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程
-
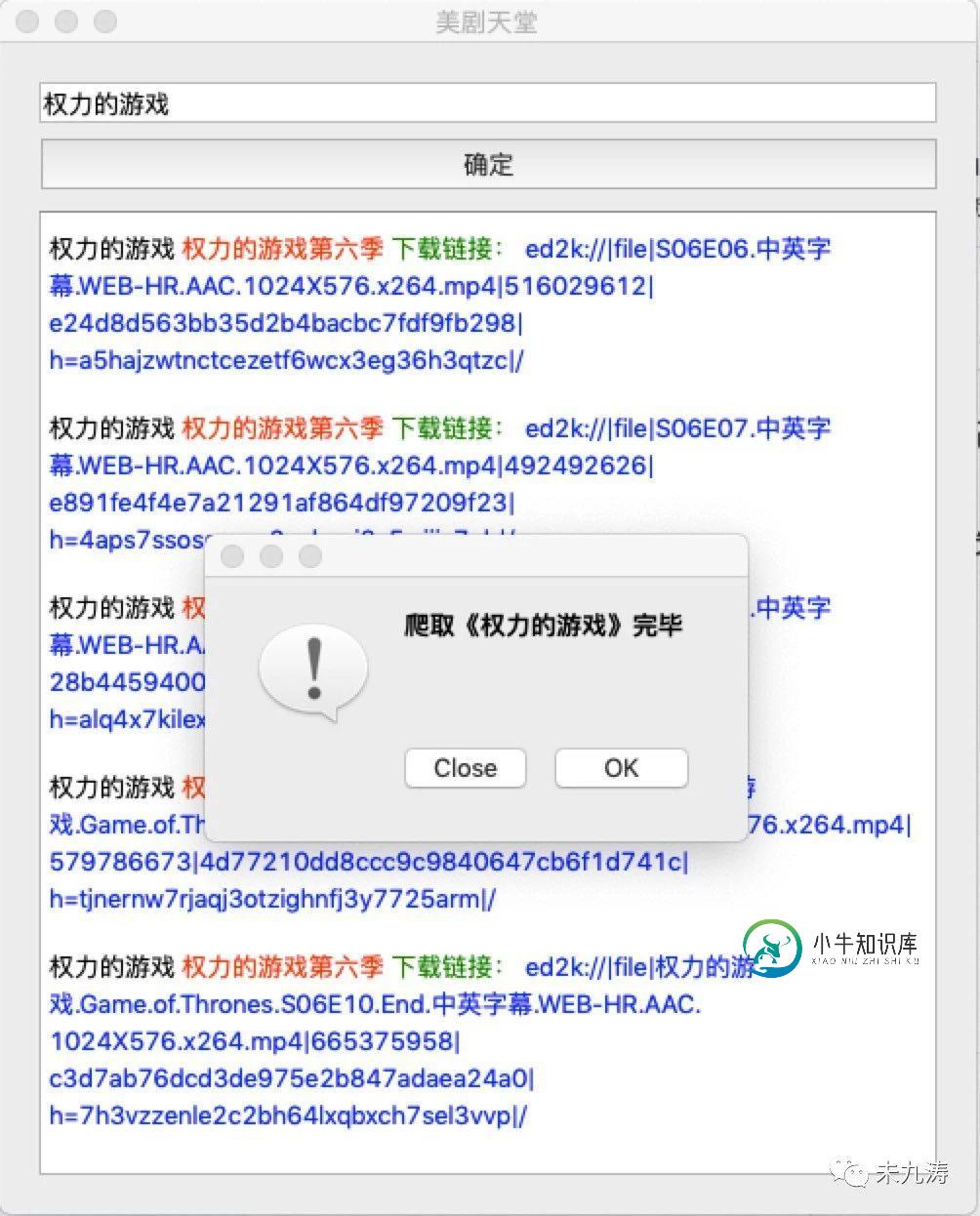 Python+PyQt5实现美剧爬虫可视工具的方法
Python+PyQt5实现美剧爬虫可视工具的方法本文向大家介绍Python+PyQt5实现美剧爬虫可视工具的方法,包括了Python+PyQt5实现美剧爬虫可视工具的方法的使用技巧和注意事项,需要的朋友参考一下 美剧《权力的游戏》终于要开播最后一季了,作为马丁老爷子的忠实粉丝,为了能够看得懂第八季复杂庞大的剧情架构,本人想着将前几季再稳固一下,所以就上美剧天堂下载来看,可是每次都上去下载太麻烦了,于是干脆自己写个爬虫爬下来得了。 话不多说,先上
-
 java网络爬虫连接超时解决实例代码
java网络爬虫连接超时解决实例代码本文向大家介绍java网络爬虫连接超时解决实例代码,包括了java网络爬虫连接超时解决实例代码的使用技巧和注意事项,需要的朋友参考一下 本文研究的主要是java网络爬虫连接超时的问题,具体如下。 在网络爬虫中,经常会遇到如下报错。即连接超时。针对此问题,一般解决思路为:将连接时间、请求时间设置长一下。如果出现连接超时的情况,则在重新请求【设置重新请求次数】。 下面的代码便是使用httpclient