《爬虫》专题
-
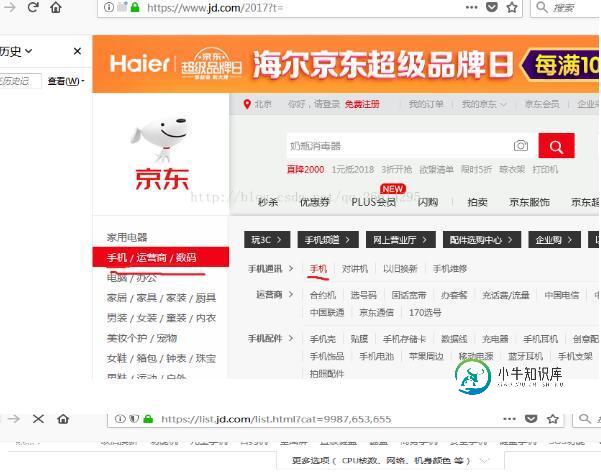 python爬虫获取京东手机图片的图文教程
python爬虫获取京东手机图片的图文教程本文向大家介绍python爬虫获取京东手机图片的图文教程,包括了python爬虫获取京东手机图片的图文教程的使用技巧和注意事项,需要的朋友参考一下 如题,首先当然是要打开京东的手机页面 因为要获取不同页面的所有手机图片,所以我们要跳转到不同页面观察页面地址的规律,这里观察第二页页面 由观察可以得到,第二页的链接地址很有可能是 https://list.jd.com/list.html?cat=99
-
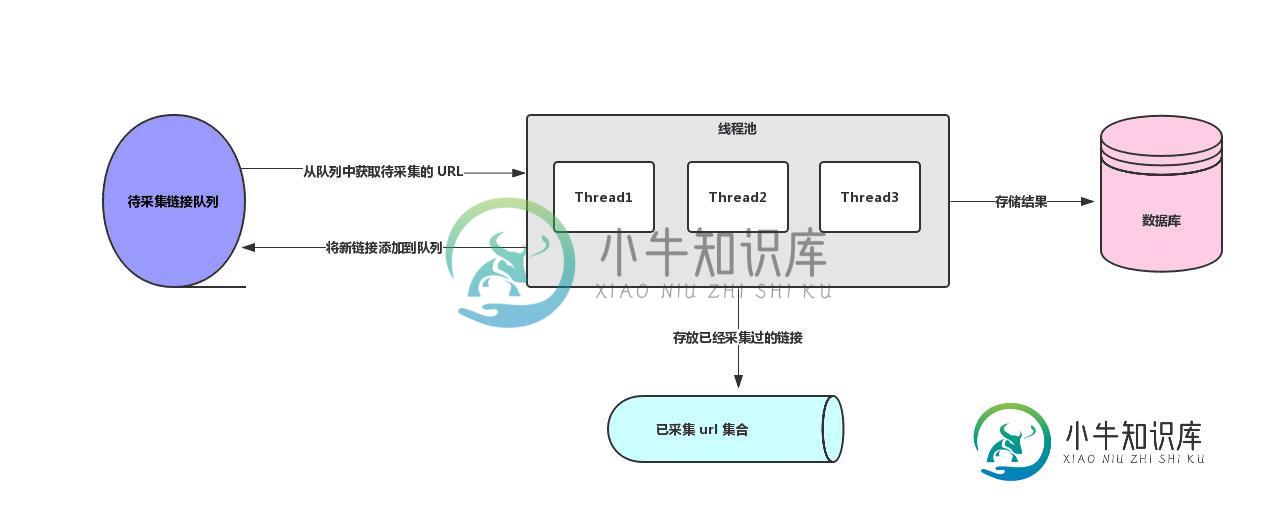 Java多线程及分布式爬虫架构原理解析
Java多线程及分布式爬虫架构原理解析本文向大家介绍Java多线程及分布式爬虫架构原理解析,包括了Java多线程及分布式爬虫架构原理解析的使用技巧和注意事项,需要的朋友参考一下 这是 Java 爬虫系列博文的第五篇,在上一篇Java 爬虫服务器被屏蔽的解决方案中,我们简单的聊反爬虫策略和反反爬虫方法,主要针对的是 IP 被封及其对应办法。前面几篇文章我们把爬虫相关的基本知识都讲的差不多啦。这一篇我们来聊一聊爬虫架构相关的内容。 前面几
-
 Android利用爬虫实现模拟登录的实现实例
Android利用爬虫实现模拟登录的实现实例本文向大家介绍Android利用爬虫实现模拟登录的实现实例,包括了Android利用爬虫实现模拟登录的实现实例的使用技巧和注意事项,需要的朋友参考一下 Android利用爬虫实现模拟登录的实现实例 为了用手机登录校网时不用一遍一遍的输入账号密码,于是决定用爬虫抓取学校登录界面,然后模拟填写本次保存的账号、密码,模拟点击登录按钮。实现过程折腾好几个。 一开始选择的是htmlunit解析登录界面htm
-
Python网络爬虫中的同步与异步示例详解
本文向大家介绍Python网络爬虫中的同步与异步示例详解,包括了Python网络爬虫中的同步与异步示例详解的使用技巧和注意事项,需要的朋友参考一下 一、同步与异步 模板 tips: await表达式中的对象必须是awaitable requests不支持非阻塞 aiohttp是用于异步请求的库 代码 gevent简介 gevent是一个python的并发库,它为各种并发和网络相关的任务提供了整洁的
-
详解Selenium-webdriver绕开反爬虫机制的4种方法
本文向大家介绍详解Selenium-webdriver绕开反爬虫机制的4种方法,包括了详解Selenium-webdriver绕开反爬虫机制的4种方法的使用技巧和注意事项,需要的朋友参考一下 之前爬美团外卖后台的时候出现的问题,各种方式拖动验证码都无法成功,包括直接控制拉动,模拟人工轨迹的随机拖动都失败了,最后发现只要用chrome driver打开页面,哪怕手动登录也不可以,猜测driver肯定
-
python爬虫 基于requests模块的get请求实现详解
本文向大家介绍python爬虫 基于requests模块的get请求实现详解,包括了python爬虫 基于requests模块的get请求实现详解的使用技巧和注意事项,需要的朋友参考一下 需求:爬取搜狗首页的页面数据 requests模块如何处理携带参数的get请求,返回携带参数的请求 需求:指定一个词条,获取搜狗搜索结果所对应的页面数据 之前urllib模块处理url上参数有中文的需要处理编码,
-
使用基于python scrapy的爬虫程序,但出现错误
嗨,伙计们,我已经写了一个Python爬虫刮...... 我不断地犯错误 “downloader/response_bytes”:9282,“downloader/response_count”:2,“downloader/response_status_count/200”:1,“downloader/response_status_count/301”:1,“finish_reason”:7,
-
java - 做爬虫时如何提取网站登录后的cookie?
我知道可以通过F12查看,我现在的需求是要完整的请求头的cookie内容,因为我需要放到爬虫的Jsoup的connection的head里, 有什么好的获取cookie的方法吗?我总不可能手动输入一个一个的键值对吧?
-
如何使用 LLM 来做爬虫的页面通用解析?
现在遇到的问题是 html 往往很大,甚至可以说体积是超级超级大,几百KB甚至几MB 但是 LLM 的上下文比较小,输入的 html 这么大,非常的糟糕 但是又不能去除掉所有的 html 标签,因为这样就是失去了原始信息了,怎么有选择性的把有效且精简的数据输入给 llm 呢?
-
php爬取天猫和淘宝商品数据
本文向大家介绍php爬取天猫和淘宝商品数据,包括了php爬取天猫和淘宝商品数据的使用技巧和注意事项,需要的朋友参考一下 一、思路 最近做了一个网站用到了从网址爬取天猫和淘宝的商品信息,首先看了下手机端的网页发现用的react,不太了解没法搞,所以就考虑从PC入口爬取数据,但是当爬取URL获取数据时并没有获取价格,库存等的信息,仔细研究了下发现是异步请求了另一个接口,但是接口要使用refer才能获取
-
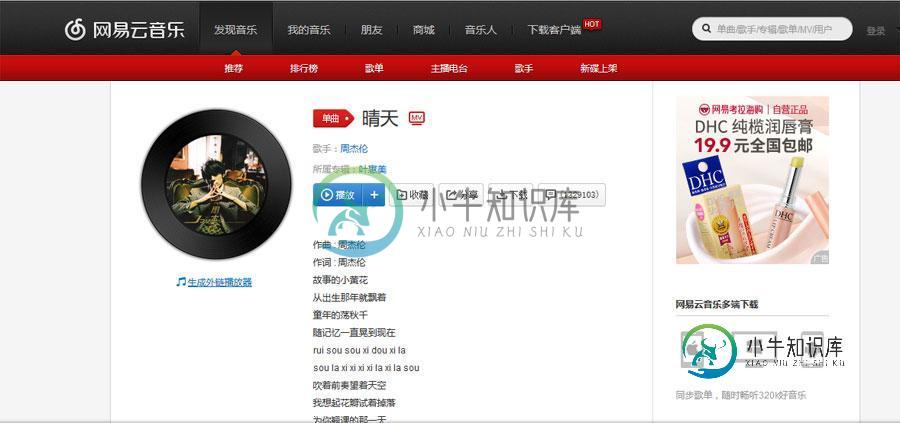 Python爬取网易云音乐热门评论
Python爬取网易云音乐热门评论本文向大家介绍Python爬取网易云音乐热门评论,包括了Python爬取网易云音乐热门评论的使用技巧和注意事项,需要的朋友参考一下 最近在研究文本挖掘相关的内容,所谓巧妇难为无米之炊,要想进行文本分析,首先得到有文本吧。获取文本的方式有很多,比如从网上下载现成的文本文档,或者通过第三方提供的API进行获取数据。但是有的时候我们想要的数据并不能直接获取,因为并不提供直接的下载渠道或者API供我们获取
-
Python 爬取必应壁纸的实例讲解
本文向大家介绍Python 爬取必应壁纸的实例讲解,包括了Python 爬取必应壁纸的实例讲解的使用技巧和注意事项,需要的朋友参考一下 最近看了下python,就想着获取下bing的图片,每天定时爬取,保存到本地,可以做背景图片用。 也在网上看了一些其他的例子。就自己动手写了一个小的爬图片的python脚本。 我们进来来爬取的是必应壁纸的相关实例,代码如下: 以上就是Python 爬取必应壁纸的实
-
Python实现爬取逐浪小说的方法
本文向大家介绍Python实现爬取逐浪小说的方法,包括了Python实现爬取逐浪小说的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python实现爬取逐浪小说的方法。分享给大家供大家参考。具体分析如下: 本人喜欢在网上看小说,一直使用的是小说下载阅读器,可以自动从网上下载想看的小说到本地,比较方便。最近在学习Python的爬虫,受此启发,突然就想到写一个爬取小说内容的脚本玩玩。于是
-
Python爬取三国演义的实现方法
本文向大家介绍Python爬取三国演义的实现方法,包括了Python爬取三国演义的实现方法的使用技巧和注意事项,需要的朋友参考一下 本文的爬虫教程分为四部: 1.从哪爬 where 2.爬什么 what 3.怎么爬 how 4.爬了之后信息如何保存 save 一、从哪爬 三国演义 二、爬什么 三国演义全文 三、怎么爬 在Chrome页面打开F12,就可以发现
-
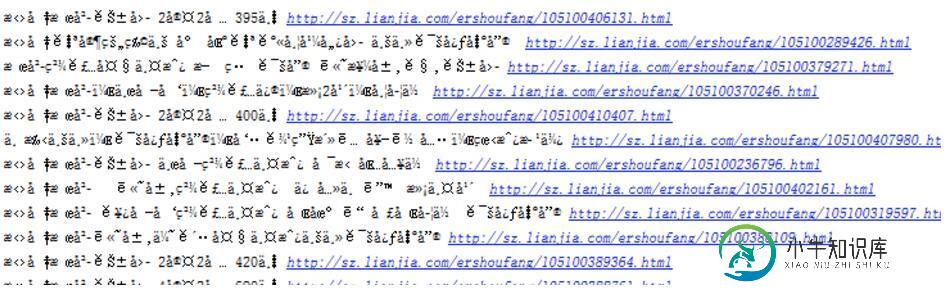 浅谈Python爬取网页的编码处理
浅谈Python爬取网页的编码处理本文向大家介绍浅谈Python爬取网页的编码处理,包括了浅谈Python爬取网页的编码处理的使用技巧和注意事项,需要的朋友参考一下 背景 中秋的时候,一个朋友给我发了一封邮件,说他在爬链家的时候,发现网页返回的代码都是乱码,让我帮他参谋参谋(中秋加班,真是敬业= =!),其实这个问题我很早就遇到过,之前在爬小说的时候稍微看了一下,不过没当回事,其实这个问题就是对编码的理解不到位导致的。 问题 很普