《爬虫》专题
-
python3.x - 爬虫:如何获得vn30指数构成公司的symbol?
"https://cn.investing.com/indices/hnx-30-components",这个网页包含了hnx30公司的构成,我只要爬取下来,用一个字典来容纳结果,键是公司名,值是一个链接,点击这个链接,可以跳转到公司名的网页,这个公司名对应的symbol就在里面。 下面我要做的是,获得每个公司的symbol,发现,居然无法用playwright,来模拟跳转,并获取跳转后的网页,请
-
使用python实现抓取腾讯视频所有电影的爬虫
本文向大家介绍使用python实现抓取腾讯视频所有电影的爬虫,包括了使用python实现抓取腾讯视频所有电影的爬虫的使用技巧和注意事项,需要的朋友参考一下 用python实现的抓取腾讯视频所有电影的爬虫 总结 以上所述是小编给大家介绍的使用python实现抓取腾讯视频所有电影的爬虫,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
-
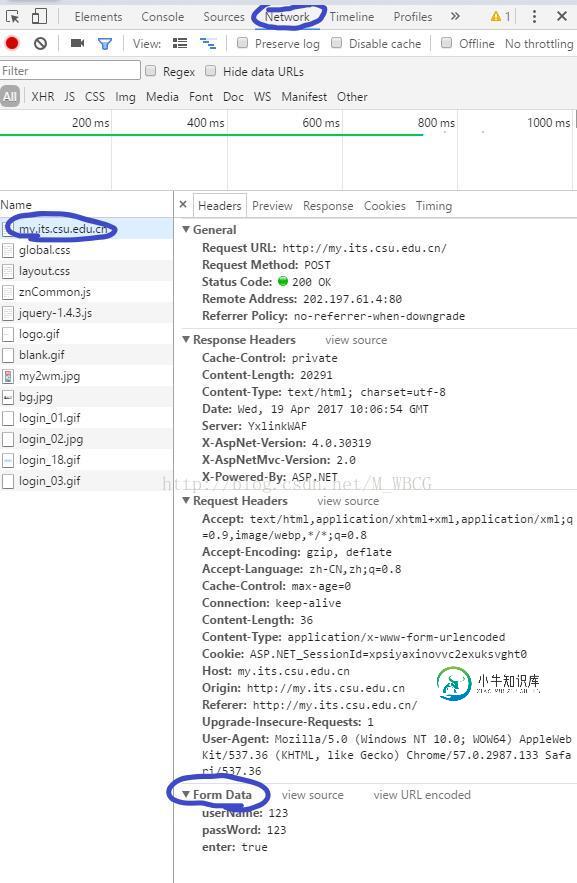 Python 网络爬虫--关于简单的模拟登录实例讲解
Python 网络爬虫--关于简单的模拟登录实例讲解本文向大家介绍Python 网络爬虫--关于简单的模拟登录实例讲解,包括了Python 网络爬虫--关于简单的模拟登录实例讲解的使用技巧和注意事项,需要的朋友参考一下 和获取网页上的信息不同,想要进行模拟登录还需要向服务器发送一些信息,如账号、密码等等。 模拟登录一个网站大致分为这么几步: 1.先将登录网站的隐藏信息找到,并将其内容先进行保存(由于我这里登录的网站并没有额外信息,所以这里没有进行信
-
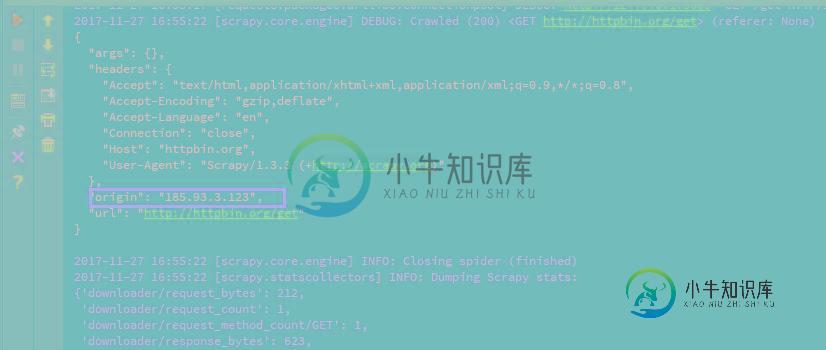 Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能示例
Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能示例本文向大家介绍Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能示例,包括了Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能。分享给大家供
-
 Python3网络爬虫之使用User Agent和代理IP隐藏身份
Python3网络爬虫之使用User Agent和代理IP隐藏身份本文向大家介绍Python3网络爬虫之使用User Agent和代理IP隐藏身份,包括了Python3网络爬虫之使用User Agent和代理IP隐藏身份的使用技巧和注意事项,需要的朋友参考一下 本文介绍了Python3网络爬虫之使用User Agent和代理IP隐藏身份,分享给大家,具体如下: 运行平台:Windows Python版本:Python3.x IDE:Sublime text3 一
-
 使用Python的urllib和urllib2模块制作爬虫的实例教程
使用Python的urllib和urllib2模块制作爬虫的实例教程本文向大家介绍使用Python的urllib和urllib2模块制作爬虫的实例教程,包括了使用Python的urllib和urllib2模块制作爬虫的实例教程的使用技巧和注意事项,需要的朋友参考一下 urllib 学习python完基础,有些迷茫.眼睛一闭,一种空白的窒息源源不断而来.还是缺少练习,遂拿爬虫来练练手.学习完斯巴达python爬虫课程后,将心得整理如下,供后续翻看.整篇笔记主要分以下
-
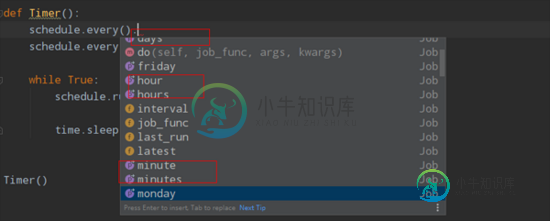 Python爬虫定时计划任务的几种常见方法(推荐)
Python爬虫定时计划任务的几种常见方法(推荐)本文向大家介绍Python爬虫定时计划任务的几种常见方法(推荐),包括了Python爬虫定时计划任务的几种常见方法(推荐)的使用技巧和注意事项,需要的朋友参考一下 记得以前的Windows任务定时是可以正常使用的,今天试了下,发现不能正常使用了,任务计划总是挂起。接下来记录下Python爬虫定时任务的几种解决方法。 1.方法一、while True 首先最容易的是while true死循环挂起,不
-
Linux部署python爬虫脚本,并设置定时任务的方法
本文向大家介绍Linux部署python爬虫脚本,并设置定时任务的方法,包括了Linux部署python爬虫脚本,并设置定时任务的方法的使用技巧和注意事项,需要的朋友参考一下 去年因项目需要,用python写了个爬虫。因爬到的数据需要存到生产环境的PG数据库。所以需要将脚本部署到CentOS服务器,并设置定时任务,自动启动脚本。 实施步骤如下: 1.安装pip(操作系统自带了python2.6可以
-
零基础写python爬虫之抓取百度贴吧代码分享
本文向大家介绍零基础写python爬虫之抓取百度贴吧代码分享,包括了零基础写python爬虫之抓取百度贴吧代码分享的使用技巧和注意事项,需要的朋友参考一下 这里就不给大家废话了,直接上代码,代码的解释都在注释里面,看不懂的也别来问我,好好学学基础知识去! 以上就是python抓取百度贴吧的一段简单的代码,非常的实用吧,各位可以自行扩展下。
-
网络爬虫是否读取WEB-INF文件夹内的JSP页面
我有一个使用jsp页面的网络应用程序。我故意没有把jsp页面放在WEB-INF文件夹中,因为jsp中只有最少的代码,而且因为当时(大约5年前)我读到网络爬虫找不到WEB-INF文件夹中的文件。因此影响了我的搜索引擎优化/排名/搜索引擎搜索结果。 我还将jsp文件的位置放在网站地图中。xml文件。我使用的是tomcat,该网站完全公开,没有登录/安全要求。 所以,快进到现在。我的网站排名不错,搜索结
-
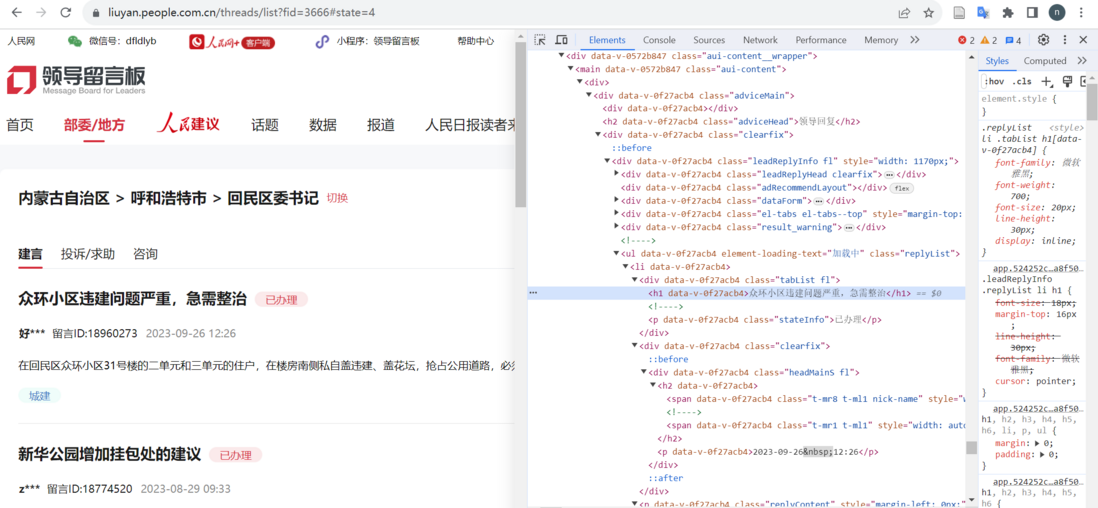 爬虫 - 为什么在F12中找不到网页中的超链接?
爬虫 - 为什么在F12中找不到网页中的超链接?如图,在爬人民网领导留言板数据时,这里每条留言都有一个超链接可以转到留言详情页,但在开发者工具中却找不到这个链接在哪里,查找tag_name为a的内容也没有找到,该怎么定位和提取超链接,求好心人帮助 网页链接为:https://liuyan.people.com.cn/threads/list?fid=3666 如图:
-
python爬取各类文档方法归类汇总
本文向大家介绍python爬取各类文档方法归类汇总,包括了python爬取各类文档方法归类汇总的使用技巧和注意事项,需要的朋友参考一下 HTML文档是互联网上的主要文档类型,但还存在如TXT、WORD、Excel、PDF、csv等多种类型的文档。网络爬虫不仅需要能够抓取HTML中的敏感信息,也需要有抓取其他类型文档的能力。下面简要记录一些个人已知的基于python3的抓取方法,以备查阅。 1.抓取
-
 Python爬取Coursera课程资源的详细过程
Python爬取Coursera课程资源的详细过程本文向大家介绍Python爬取Coursera课程资源的详细过程,包括了Python爬取Coursera课程资源的详细过程的使用技巧和注意事项,需要的朋友参考一下 有时候我们需要把一些经典的东西收藏起来,时时回味,而Coursera上的一些课程无疑就是经典之作。Coursera中的大部分完结课程都提供了完整的配套教学资源,包括ppt,视频以及字幕等,离线下来后会非常便于学习。很明显,我们不会去一个
-
 Python爬取京东的商品分类与链接
Python爬取京东的商品分类与链接本文向大家介绍Python爬取京东的商品分类与链接,包括了Python爬取京东的商品分类与链接的使用技巧和注意事项,需要的朋友参考一下 前言 本文主要的知识点是使用Python的BeautifulSoup进行多层的遍历。 如图所示。只是一个简单的哈,不是爬取里面的隐藏的东西。 示例代码 运行这段代码以及达到了我们的目的。 我们来解读一下这段代码。 首先我们要访问到京东的首页。 然后通过Beauti
-
Python多线程爬取豆瓣影评API接口
本文向大家介绍Python多线程爬取豆瓣影评API接口,包括了Python多线程爬取豆瓣影评API接口的使用技巧和注意事项,需要的朋友参考一下 爬虫库 使用简单的requests库,这是一个阻塞的库,速度比较慢。 解析使用XPATH表达式 总体采用类的形式 多线程 使用concurrent.future并发模块,建立线程池,把future对象扔进去执行即可实现并发爬取效果 数据存储 使用Pytho