《爬虫》专题
-
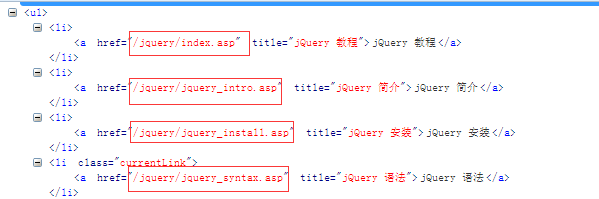 python爬取w3shcool的JQuery课程并且保存到本地
python爬取w3shcool的JQuery课程并且保存到本地本文向大家介绍python爬取w3shcool的JQuery课程并且保存到本地,包括了python爬取w3shcool的JQuery课程并且保存到本地的使用技巧和注意事项,需要的朋友参考一下 最近在忙于找工作,闲暇之余,也找点爬虫项目练练手,写写代码,知道自己是个菜鸟,但是要多加练习,书山有路勤为径。各位爷有测试坑可以给我介绍个啊,自动化,功能,接口都可以做。 首先呢,我们明确需求,很多同学呢,有
-
Okhttp3实现爬取验证码及获取Cookie的示例
本文向大家介绍Okhttp3实现爬取验证码及获取Cookie的示例,包括了Okhttp3实现爬取验证码及获取Cookie的示例的使用技巧和注意事项,需要的朋友参考一下 目前正在做毕业设计,一个关于校园服务的app,我会抽取已完成的相关代码写到文章里。一是为了造福这个曾经帮助过我的社区,二是写文章的同时更能巩固相关知识的记忆。 一、前言 在爬取教务系统的过程中,验证码的获取是非常重要的:在生成验证码
-
如何修复坚果爬行器中已存在的.locked?
我是nutch的初级用户。当我用bin/nutch抓取命令重新抓取时,我得到一个。锁定已经存在。 以下是我的例外。链接反转 /home/crawler_user/apache-nutch-1.14/bin/nutch invertlinks/data/crawlor_user/nutch/crawled-data/linkdb/data/crawle_user/nutch/crawled-data
-
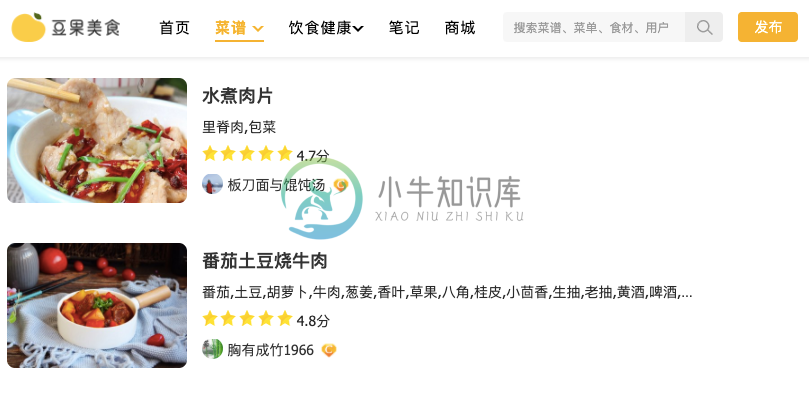 用Python爬取美食网站3032个菜谱并分析
用Python爬取美食网站3032个菜谱并分析打开各大美食网站,如豆果美食、下厨房、美食天下等。经过甄选,最终爬取了豆果网最新发布的中国菜系共3032个菜谱,然后清洗数据并做可视化分析,试图走上美食博主的康庄大道。 01.数据获取 豆果美食网的数据爬取比较简单 图片 豆果美食网 本次爬取的数据范围为川菜、粤菜、湘菜等八个中国菜系,包含菜谱名、链接、用料、评分、图片等字段。限于篇幅,仅给出核心代码。
-
以Python的Pyspider为例剖析搜索引擎的网络爬虫实现方法
本文向大家介绍以Python的Pyspider为例剖析搜索引擎的网络爬虫实现方法,包括了以Python的Pyspider为例剖析搜索引擎的网络爬虫实现方法的使用技巧和注意事项,需要的朋友参考一下 在这篇文章中,我们将分析一个网络爬虫。 网络爬虫是一个扫描网络内容并记录其有用信息的工具。它能打开一大堆网页,分析每个页面的内容以便寻找所有感兴趣的数据,并将这些数据存储在一个数据库中,然后对其他网页进行
-
Python爬虫实现网页信息抓取功能示例【URL与正则模块】
本文向大家介绍Python爬虫实现网页信息抓取功能示例【URL与正则模块】,包括了Python爬虫实现网页信息抓取功能示例【URL与正则模块】的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫实现网页信息抓取功能。分享给大家供大家参考,具体如下: 首先实现关于网页解析、读取等操作我们要用到以下几个模块 我们可以尝试一下用readline方法读某个网站,比如说百度 下面我们说一
-
AWS Glue作业将表转换为镶木地板,不需要另一个爬虫
有没有可能让粘合作业将JSON表重新分类为拼花,而不需要另一个爬虫来抓取拼花文件? 当前设置: 分区S3 bucket中的JSON文件每天爬网一次 我必须相信有一种方法可以在没有另一个爬虫的情况下转换表分类(但我以前被AWS烧伤过)。非常感谢任何帮助!
-
python3.x - 怎么解决python 爬虫运行多进程报错:TypeError: cannot pickle '_thread.lock' object?
python 爬虫运行多进程报错:TypeError: cannot pickle '_thread.lock' object 怎么解决python 爬虫运行多进程报错:TypeError: cannot pickle '_thread.lock' object
-
 如何准确判断请求是搜索引擎爬虫(蜘蛛)发出的请求
如何准确判断请求是搜索引擎爬虫(蜘蛛)发出的请求本文向大家介绍如何准确判断请求是搜索引擎爬虫(蜘蛛)发出的请求,包括了如何准确判断请求是搜索引擎爬虫(蜘蛛)发出的请求的使用技巧和注意事项,需要的朋友参考一下 网站经常会被各种爬虫光顾,有的是搜索引擎爬虫,有的不是,通常情况下这些爬虫都有UserAgent,而我们知道UserAgent是可以伪装的,UserAgent的本质是Http请求头中的一个选项设置,通过编程的方式可以给请求设置任意的User
-
 Node.js+jade+mongodb+mongoose实现爬虫分离入库与生成静态文件的方法
Node.js+jade+mongodb+mongoose实现爬虫分离入库与生成静态文件的方法本文向大家介绍Node.js+jade+mongodb+mongoose实现爬虫分离入库与生成静态文件的方法,包括了Node.js+jade+mongodb+mongoose实现爬虫分离入库与生成静态文件的方法的使用技巧和注意事项,需要的朋友参考一下 接着这篇文章Node.js+jade抓取博客所有文章生成静态html文件的实例继续,在这篇文章中实现了采集与静态文件的生成,在实际的采集项目中, 应
-
 Python爬虫通过替换http request header来欺骗浏览器实现登录功能
Python爬虫通过替换http request header来欺骗浏览器实现登录功能本文向大家介绍Python爬虫通过替换http request header来欺骗浏览器实现登录功能,包括了Python爬虫通过替换http request header来欺骗浏览器实现登录功能的使用技巧和注意事项,需要的朋友参考一下 以豆瓣为例,访问https://www.douban.com/contacts/list 来查看自己关注的人,要登录才能查看。 如果用requests.get()方
-
python - 网络爬虫需要进行登陆操才的网站选择什么语言?
适合需要先进行登陆后才能操作的完整?应该使用什么语言呢?
-
在Scrapy中通过身份验证的会话进行爬网
问题内容: 在上一个问题中,我对问题不是很具体(希望通过与Scrapy进行身份验证的会话进行爬取),希望能够从更笼统的答案中得出解决方案。我应该宁可使用这个词。 因此,这是到目前为止的代码: 如您所见,我访问的第一页是登录页面。如果尚未通过身份验证(在函数中),则调用自定义函数,该函数将发布到登录表单中。然后,如果我 我 验证,我想继续爬行。 问题是我尝试覆盖以登录的功能,现在不再进行必要的调用以
-
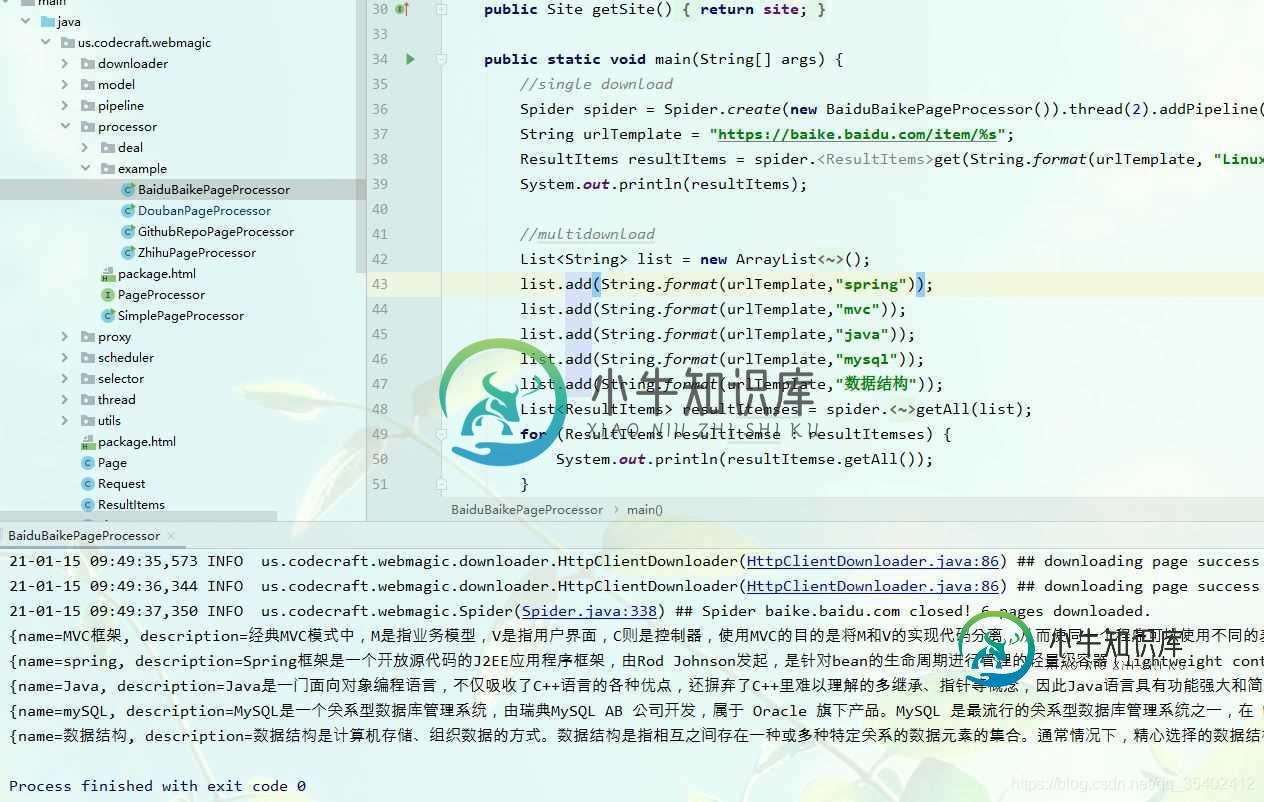 Java基于WebMagic爬取某豆瓣电影评论的实现
Java基于WebMagic爬取某豆瓣电影评论的实现本文向大家介绍Java基于WebMagic爬取某豆瓣电影评论的实现,包括了Java基于WebMagic爬取某豆瓣电影评论的实现的使用技巧和注意事项,需要的朋友参考一下 目的 搭建爬虫平台,爬取某豆瓣电影的评论信息。 准备 webmagic是一个开源的Java垂直爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑功能的开发。webmagic的核心非常简单,但是覆盖爬虫的整个流程,也是很好的学习爬
-
Python爬取视频(其实是一篇福利)过程解析
本文向大家介绍Python爬取视频(其实是一篇福利)过程解析,包括了Python爬取视频(其实是一篇福利)过程解析的使用技巧和注意事项,需要的朋友参考一下 窗外下着小雨,作为单身程序员的我逛着逛着发现一篇好东西,来自知乎 你都用 Python 来做什么?的第一个高亮答案。 到上面去看了看,地址都是明文的,得,赶紧开始吧。 下载流式文件,requests库中请求的stream设为True就可以啦,文