《爬虫》专题
-
 详解Python爬取并下载《电影天堂》3千多部电影
详解Python爬取并下载《电影天堂》3千多部电影本文向大家介绍详解Python爬取并下载《电影天堂》3千多部电影,包括了详解Python爬取并下载《电影天堂》3千多部电影的使用技巧和注意事项,需要的朋友参考一下 不知不觉,玩爬虫玩了一个多月了。 我愈发觉得,爬虫其实并不是什么特别高深的技术,它的价值不在于你使用了什么特别牛的框架,用了多么了不起的技术,它不需要。它只是以一种自动化搜集数据的小工具,能够获取到想要的数据,就是它最大的价值。 我的爬
-
 用Python爬取QQ音乐评论并制成词云图的实例
用Python爬取QQ音乐评论并制成词云图的实例本文向大家介绍用Python爬取QQ音乐评论并制成词云图的实例,包括了用Python爬取QQ音乐评论并制成词云图的实例的使用技巧和注意事项,需要的朋友参考一下 环境:Ubuntu16.4 python版本:3.6.4 库:wordcloud 这次我们要讲的是爬取QQ音乐的评论并制成云词图,我们这里拿周杰伦的等你下课来举例。 第一步:获取评论 我们先打开QQ音乐,搜索周杰伦的《等你下课》,直接拉到底
-
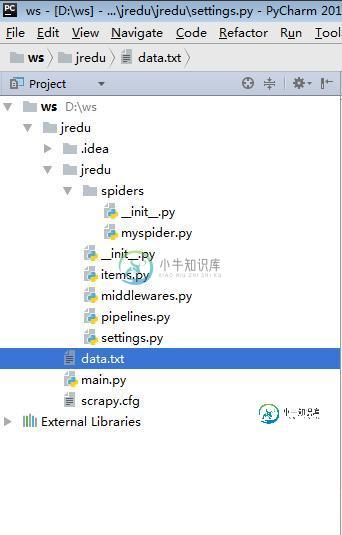 Python大数据之从网页上爬取数据的方法详解
Python大数据之从网页上爬取数据的方法详解本文向大家介绍Python大数据之从网页上爬取数据的方法详解,包括了Python大数据之从网页上爬取数据的方法详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python大数据之从网页上爬取数据的方法。分享给大家供大家参考,具体如下: myspider.py : items.py : middlewares.py : pipelines.py : settings.py
-
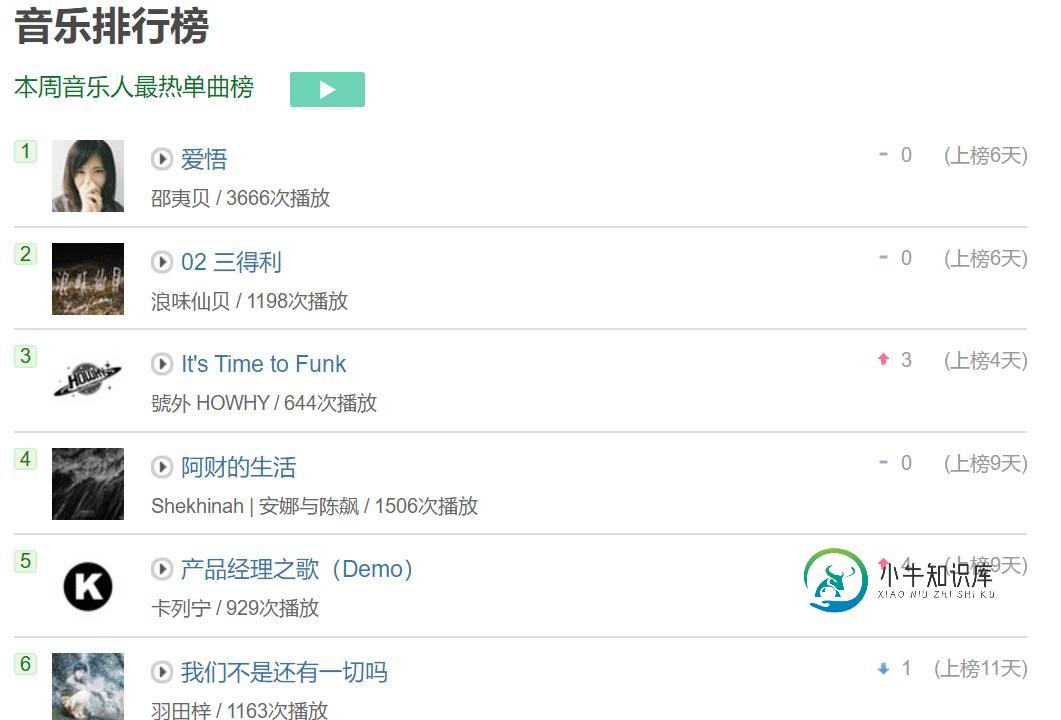 Python使用Beautiful Soup爬取豆瓣音乐排行榜过程解析
Python使用Beautiful Soup爬取豆瓣音乐排行榜过程解析本文向大家介绍Python使用Beautiful Soup爬取豆瓣音乐排行榜过程解析,包括了Python使用Beautiful Soup爬取豆瓣音乐排行榜过程解析的使用技巧和注意事项,需要的朋友参考一下 前言 要想学好爬虫,必须把基础打扎实,之前发布了两篇文章,分别是使用XPATH和requests爬取网页,今天的文章是学习Beautiful Soup并通过一个例子来实现如何使用Beautiful
-
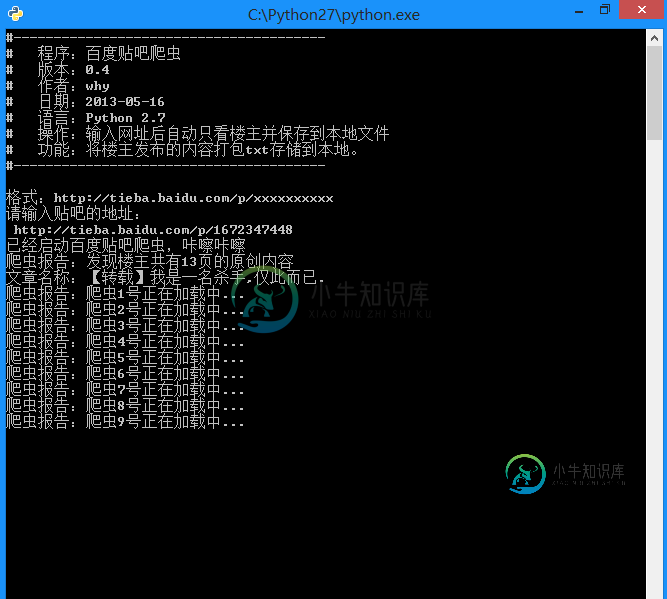 零基础写python爬虫之抓取百度贴吧并存储到本地txt文件改进版
零基础写python爬虫之抓取百度贴吧并存储到本地txt文件改进版本文向大家介绍零基础写python爬虫之抓取百度贴吧并存储到本地txt文件改进版,包括了零基础写python爬虫之抓取百度贴吧并存储到本地txt文件改进版的使用技巧和注意事项,需要的朋友参考一下 百度贴吧的爬虫制作和糗百的爬虫制作原理基本相同,都是通过查看源码扣出关键数据,然后将其存储到本地txt文件。 项目内容: 用Python写的百度贴吧的网络爬虫。 使用方法: 新建一个BugBaidu.py
-
爬虫 - Ajax页面交互自动请求的可以手动调用后端返回没有权限?
https://www.pexels.com/zh-cn/search/%E7%8C%AB%E5%92%AA/ URL解码后的: https://www.pexels.com/zh-cn/search/猫咪/ 进入页面, 向下滚动页面会触发翻页请求(Ajax请求). 然后, 复制Ajax请求的参数, 放到地址栏或者postman请求, 后端返回 {"error_messages":["Bad AP
-
 python实现模拟器爬取抖音评论数据的示例代码
python实现模拟器爬取抖音评论数据的示例代码本文向大家介绍python实现模拟器爬取抖音评论数据的示例代码,包括了python实现模拟器爬取抖音评论数据的示例代码的使用技巧和注意事项,需要的朋友参考一下 目标: 由于之前和朋友聊到抖音评论的爬虫,demo做出来之后一直没整理,最近时间充裕后,在这里做个笔记。 提示:大体思路 通过fiddle + app模拟器进行抖音抓包,使用python进行数据整理 安装需要的工具: python3 下载
-
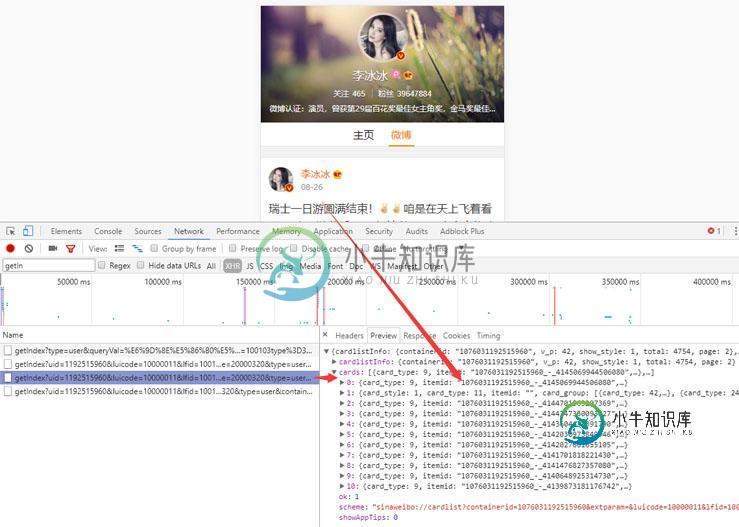 利用Python爬取微博数据生成词云图片实例代码
利用Python爬取微博数据生成词云图片实例代码本文向大家介绍利用Python爬取微博数据生成词云图片实例代码,包括了利用Python爬取微博数据生成词云图片实例代码的使用技巧和注意事项,需要的朋友参考一下 前言 在很早之前写过一篇怎么利用微博数据制作词云图片出来,之前的写得不完整,而且只能使用自己的数据,现在重新整理了一下,任何的微博数据都可以制作出来,一年一度的虐汪节,是继续蹲在角落默默吃狗粮还是主动出击告别单身汪加入散狗粮的行列就看你啦,
-
python2爬取百度贴吧指定关键字和图片代码实例
本文向大家介绍python2爬取百度贴吧指定关键字和图片代码实例,包括了python2爬取百度贴吧指定关键字和图片代码实例的使用技巧和注意事项,需要的朋友参考一下 目的:在百度贴吧输入关键字和要查找的起始结束页,获取帖子里面楼主所发的图片 思路: 获取分页里面的帖子链接列表 获取帖子里面楼主所发的图片链接列表 保存图片到本地 注意事项: 问题:在谷歌浏览器使用xpath helper插件时有匹配结
-
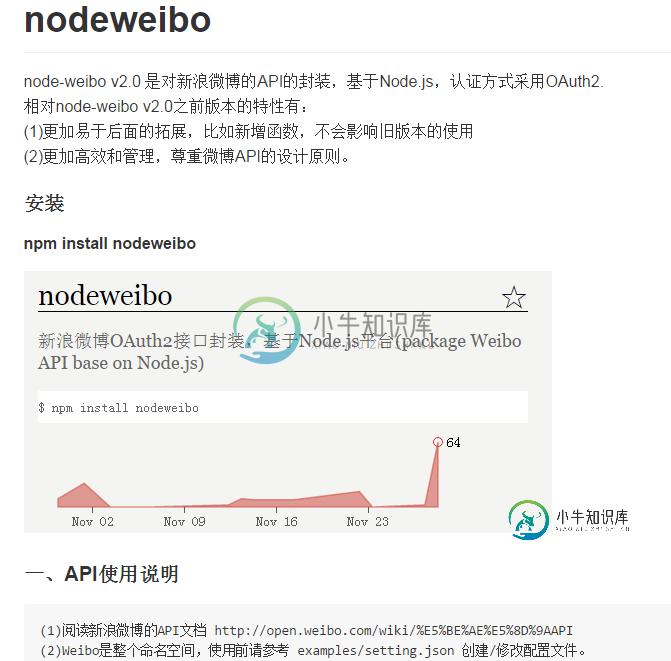 node爬取微博的数据的简单封装库nodeweibo使用指南
node爬取微博的数据的简单封装库nodeweibo使用指南本文向大家介绍node爬取微博的数据的简单封装库nodeweibo使用指南,包括了node爬取微博的数据的简单封装库nodeweibo使用指南的使用技巧和注意事项,需要的朋友参考一下 一、前言 就在去年12月份,有个想法是使用node爬取微博的数据,于是简单的封装了一个nodeweibo这个库。时隔一年,没有怎么维护,中途也就将函数形式改成了配置文件。以前做的一些其他的项目也下线了,为了是更加专注
-
详解Java两种方式简单实现:爬取网页并且保存
本文向大家介绍详解Java两种方式简单实现:爬取网页并且保存,包括了详解Java两种方式简单实现:爬取网页并且保存的使用技巧和注意事项,需要的朋友参考一下 对于网络,我一直处于好奇的态度。以前一直想着写个爬虫,但是一拖再拖,懒得实现,感觉这是一个很麻烦的事情,出现个小错误,就要调试很多时间,太浪费时间。 后来一想,既然早早给自己下了保证,就先实现它吧,从简单开始,慢慢增加功能,有时间就实现一个,并
-
 python requests库爬取豆瓣电视剧数据并保存到本地详解
python requests库爬取豆瓣电视剧数据并保存到本地详解本文向大家介绍python requests库爬取豆瓣电视剧数据并保存到本地详解,包括了python requests库爬取豆瓣电视剧数据并保存到本地详解的使用技巧和注意事项,需要的朋友参考一下 首先要做的就是去豆瓣网找对应的接口,这里就不赘述了,谷歌浏览器抓包即可,然后要做的就是分析返回的json数据的结构: https://movie.douban.com/j/search_subjects?
-
 利用Python2下载单张图片与爬取网页图片实例代码
利用Python2下载单张图片与爬取网页图片实例代码本文向大家介绍利用Python2下载单张图片与爬取网页图片实例代码,包括了利用Python2下载单张图片与爬取网页图片实例代码的使用技巧和注意事项,需要的朋友参考一下 前言 一直想好好学习一下Python爬虫,之前断断续续的把Python基础学了一下,悲剧的是学的没有忘的快。只能再次拿出来滤了一遍,趁热打铁,通过实例来实践下,下面这篇文章主要介绍了关于Python2下载单张图片与爬取网页的相关内容
-
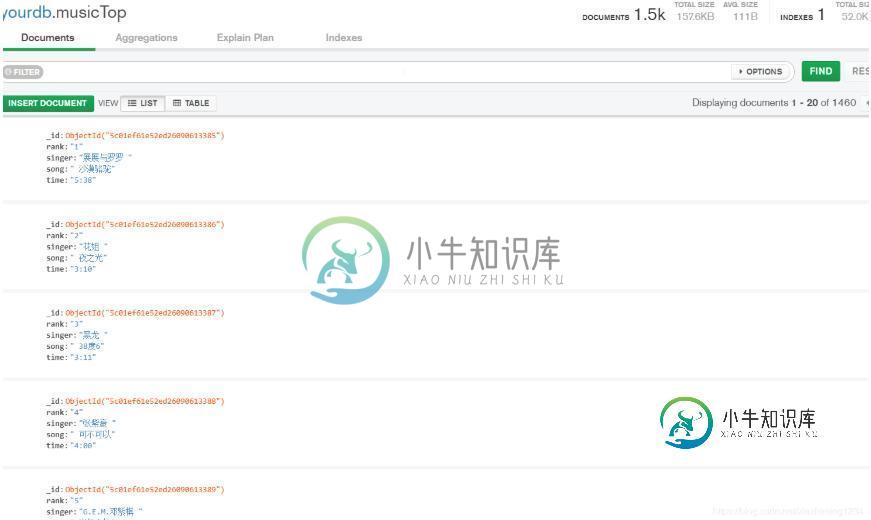 python3 实现爬取TOP500的音乐信息并存储到mongoDB数据库中
python3 实现爬取TOP500的音乐信息并存储到mongoDB数据库中本文向大家介绍python3 实现爬取TOP500的音乐信息并存储到mongoDB数据库中,包括了python3 实现爬取TOP500的音乐信息并存储到mongoDB数据库中的使用技巧和注意事项,需要的朋友参考一下 爬取TOP500的音乐信息,包括排名情况、歌曲名、歌曲时间。 网页版酷狗不能手动翻页进行下一步的浏览,仔细观察第一页的URL: http://www.kugou.com/yy/rank
-
python - 为什么scapy爬虫用管道持久化存储时创建的文件一直为空写不进去?
最近在学习scrapy爬虫的用管道持久化存储时,遇到了这个问题,只知道这个创建的fp一直为none 接下来分别是item.py的 这个是pipelines.py: 以下是我的报错: 真的找了很久的问题了,像是那种重写父类方法的问题我也比对过感觉自己重写的方式是正确的,还有就是setting文件中pipelines也有手动打开,但是始终不知道自己创建的这个fp为什么是None,一直无法写入,连txt