《爬虫》专题
-
前端 - 我再使用puppter爬虫,像antd这种的组件,select我不知道怎么选中下面的值?
比如Input 我可以这样选中赋值。但是antd的select,1是下拉框无法展开,也就没办法赋值了。
-
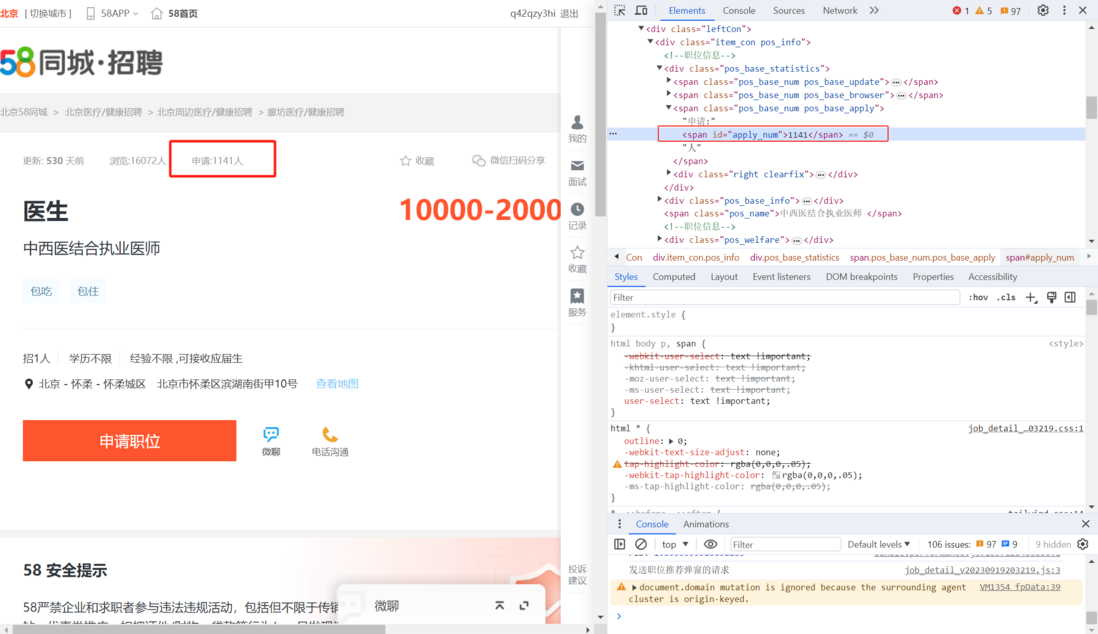 html - 爬虫时网页源代码和页面内容不一致,和F12中的ELEMENT也不一致,怎么办?
html - 爬虫时网页源代码和页面内容不一致,和F12中的ELEMENT也不一致,怎么办?在爬取58同城工作页面的申请人数和浏览人数时,网页源代码总是显示0人,但页面数据在实时更新,更新的内容和F12中的elements内容是一致的,请问这种情况应该如何爬到申请和浏览人数? 网页地址:https://bj.58.com/zpyiyuanyiliao/27988291906488x.shtml?psid=1... 网页页面: 网页源代码:
-
遇到第一个异常时,如何使草率的爬网中断并退出?
问题内容: 出于开发目的,我想在发生第一个异常(在蜘蛛网或管道中)后立即停止所有抓取抓取活动。 有什么建议吗? 问题答案: 在Spider中,您可以抛出CloseSpider异常。 对于其他(中间件,管道等),您可以按照akhter所述手动调用close_spider。 从0.11开始,存在: 一个整数,指定在关闭蜘蛛网之前要接收的最大错误数。如果蜘蛛产生的错误数量超过了该数目,它将以原因关闭。如
-
在JMeterforRESTAPI中,线程数和爬升周期之间的理想比率是多少
我需要为RESTAPI设计一个非常基本的性能测试。 并发用户数=40,响应时间=500ms以内 通常情况下,无Thread和斜坡上升周期之间的理想比率是多少? 我在某个地方读到过——虚拟用户的到达率应该是每秒25-50个用户。但是我不知道它的真实性。 对于我的情况,我是否应该将爬升周期设为2秒? 提前感谢!!!
-
python中requests爬去网页内容出现乱码问题解决方法介绍
本文向大家介绍python中requests爬去网页内容出现乱码问题解决方法介绍,包括了python中requests爬去网页内容出现乱码问题解决方法介绍的使用技巧和注意事项,需要的朋友参考一下 最近在学习python爬虫,使用requests的时候遇到了不少的问题,比如说在requests中如何使用cookies进行登录验证,这可以查看这篇文章。这篇博客要解决的问题是如何避免在使用request
-
尝试使用nutch-java.net进行爬网时出错。本地主机名上的UnknownHostException
试图在Centos 6.6上用纳奇1.9爬行。 在遵循本指南后尝试初始化我的第一次爬网时: http://wiki.apache.org/nutch/NutchTutorial 但是,我在启动时遇到以下异常: Injector:将注入的URL转换为爬网数据库条目。喷油器:java.net。未知主机异常:Sparky。立克:火花四射。LITK:java.security.AccessControll
-
数据挖掘 - 58同城url无规律变化,是一种反爬措施吗?
我在爬58同城的招聘数据时,发现在同一页面从第二页转到第三页时,url中不仅页码部分从2变到3,还有一部分以“PGTID=”开头的内容,一直发生无规律变化,因此只通过修改Url中页码部分无法和浏览器一样遍历不同页,请问这是一种什么情况呢?会对爬虫有影响吗?请问该如何解决这个问题 例如:58同城招聘北京地区护士招聘第二页url为 https://bj.58.com/nhushi/pn2/?fullP
-
利用.Htaccess阻止IP恶意攻击网站,禁止指定域名访问,禁止机器爬虫,禁止盗链
本文向大家介绍利用.Htaccess阻止IP恶意攻击网站,禁止指定域名访问,禁止机器爬虫,禁止盗链,包括了利用.Htaccess阻止IP恶意攻击网站,禁止指定域名访问,禁止机器爬虫,禁止盗链的使用技巧和注意事项,需要的朋友参考一下 前几天发现我的网站被一些IP发起了大量恶意的、有针对性的扫描,企图通过暴力探测方式获取网站中一些内部配置文件和信息。我是用.Htaccess来化解攻击的,就是在.Hta
-
螺母爬网失败的 Solr 索引,报告“索引器: java.io.IO异常: 作业失败!
我在ec2实例上集成了Nutch1.13和Solr 6.5.1。我确实复制了模式。使用下面的cp命令将xml转换为Solr。我给localhost发了兴奋剂。宿主在nutch站点。nutch_home/conf文件夹中的xml。 cp /usr/local/apache-nutch-1.13/conf/schema.xml /usr/local/apache-nutch-1.13/solr-6.5
-
 使用python itchat包爬取微信好友头像形成矩形头像集的方法
使用python itchat包爬取微信好友头像形成矩形头像集的方法本文向大家介绍使用python itchat包爬取微信好友头像形成矩形头像集的方法,包括了使用python itchat包爬取微信好友头像形成矩形头像集的方法的使用技巧和注意事项,需要的朋友参考一下 初学python,我们必须干点有意思的事!从微信下手吧! 头像集样例如下: 大家可以发朋友圈开启辨认大赛哈哈~ 话不多说,直接上代码,注释我写了比较多,大家应该能看懂 运行结果: ok!!! 以上这篇
-
通过抓取淘宝评论为例讲解Python爬取ajax动态生成的数据(经典)
本文向大家介绍通过抓取淘宝评论为例讲解Python爬取ajax动态生成的数据(经典),包括了通过抓取淘宝评论为例讲解Python爬取ajax动态生成的数据(经典)的使用技巧和注意事项,需要的朋友参考一下 在学习python的时候,一定会遇到网站内容是通过 ajax动态请求、异步刷新生成的json数据 的情况,并且通过python使用之前爬取静态网页内容的方式是不可以实现的,所以这篇文章将要讲述如果
-
python - 求解?爬取电影使用协程出现'任务已销毁,但仍处于挂起状态!'?
爬取某一部电影 于网上从学习 一步一步操作 没有出现代码错误 但还是出现 '任务已销毁,但仍处于挂起状态!' 在网上看了很多没有看到合适的解决方法 需要把所有的 任务下载完毕 而不是跳过该任务 源代码 出现的错误是
-
python - 爬取apkpure网站,headers已经完全照搬浏览器数据requests发起请求为啥还是返回403?
代码如下,有无大佬解答 orz
-
python - 求:关于爬取每次刷新页面后元素结构和对应class名都不相同的解决方法?
各位好,我使用 python的 selenium 去爬取某网页的 一些a标签,但有个问题,每次刷新后这个a标签所在的位置都会发生变化,比如第一次进入他的位置是: [@id="layoutPage"]/div[1]/div[2]/div[11]/div[2]/div[3]/div[2]/div/div[1]/div[1]/a 第二次刷新进入他就成了 [@id="layoutPage"]/div[1]
-
python - 爬虫过程中,我想查找ul下的多个li中带有特定文本的那一个li,获取li的路径。以此实现查找带有特定文本的控件。请问用driver.find_element如何实现?
爬虫过程中,我想查找ul下的多个li中带有特定文本的那一个li,获取li的路径。以此实现查找带有特定文本的控件。请问用driver.find_element如何实现? 我现有代码如下: