《爬虫》专题
-
刮。开始爬行后如何更改蜘蛛设置?
我无法更改分析方法中的爬行器设置。但这肯定是一种方式。 例如: 但是项目将由FirstPipeline处理。新项目参数不工作。开始爬网后如何更改设置?提前谢谢!
-
使用Solr Nutch对特定数据进行Web爬网
我看到了一些像http://homes.mitula.ph/homes/makati这样的搜索网站,我想知道他们是如何抓取其他网站(如、和)中的数据并将其显示到他们的站点上的。 我正在考虑使用Solr索引数据,使用Nutch抓取数据。我是一个新的网页抓取和索引,目前为止,我只能抓取一个网页的内容。 Solr Nutch能做那种爬行吗?怎么做的?
-
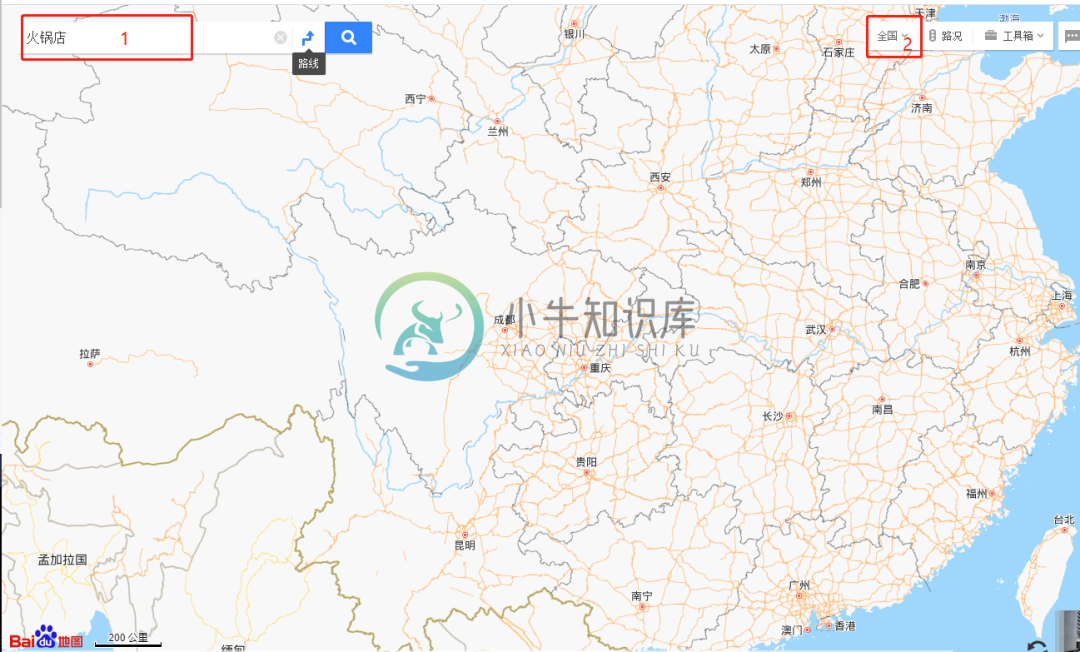 Python爬取全国火锅店并可视化展示
Python爬取全国火锅店并可视化展示先给大家分享一个数据可视化案例:如何获取全国不同城市火锅店数量情况,并将这些数据进行可视化展示,以更加直观的方式去浏览全国不同省份、不同城市的火锅店分布情况。(本文数据来自于某度地图,通过python技术知识去获取数据并进行可视化。)
-
编写Python爬虫抓取暴走漫画上gif图片的实例分享
本文向大家介绍编写Python爬虫抓取暴走漫画上gif图片的实例分享,包括了编写Python爬虫抓取暴走漫画上gif图片的实例分享的使用技巧和注意事项,需要的朋友参考一下 本文要介绍的爬虫是抓取暴走漫画上的GIF趣图,方便离线观看。爬虫用的是python3.3开发的,主要用到了urllib、request和BeautifulSoup模块。 urllib模块提供了从万维网中获取数据的高层接口,当我们
-
讲解Python的Scrapy爬虫框架使用代理进行采集的方法
本文向大家介绍讲解Python的Scrapy爬虫框架使用代理进行采集的方法,包括了讲解Python的Scrapy爬虫框架使用代理进行采集的方法的使用技巧和注意事项,需要的朋友参考一下 1.在Scrapy工程下新建“middlewares.py” 2.在项目配置文件里(./project_name/settings.py)添加 只要两步,现在请求就是通过代理的了。测试一下^_^ 3.使用随机user
-
 零基础写python爬虫之urllib2中的两个重要概念:Openers和Handlers
零基础写python爬虫之urllib2中的两个重要概念:Openers和Handlers本文向大家介绍零基础写python爬虫之urllib2中的两个重要概念:Openers和Handlers,包括了零基础写python爬虫之urllib2中的两个重要概念:Openers和Handlers的使用技巧和注意事项,需要的朋友参考一下 在开始后面的内容之前,先来解释一下urllib2中的两个个方法:info / geturl urlopen返回的应答对象response(或者HTTPErr
-
如何使用Selenium和Python通过爬虫测试非标准下拉列表
我在一个大学的项目,建立一个网页的cralwer。现在我在网页中遇到了测试下拉列表。具体地说,下面的页面没有使用标准的“Dropdown”类。
-
python - 爬虫代理反向代理管理面板有哪些技术选型?
爬虫代理反向代理管理面板有哪些技术选型? 需求:爬虫业务,有多个代理 ip 供应商,但是这些供应商没有监控:实时使用的带宽、流量、连接数等等指标 但是我们自己需要监控 有哪些工具可以做这个?openresty?
-
python - 爬虫requests.get无限刷新加载,呈现卡死特征,如何处理?
初学者一个,爬取某网站url html=requests.get(url=url).text#,headers=headers,timeout=10 一直卡主不返回,加上headers timeout无效,代码改为 原来并不是卡死,而是在加载完成后还在无限加载 如何在初次加载完成后立即返回不再重复加载,手动点击stop按钮即可返回,如何在初次加载完成后立即返回不再重复加载,手动点击stop按钮即可
-
python - 为什么Python爬虫对一个网站一发请求就被封ip?
最近试着爬一个网站,只要一对这个网站用request请求,网站立马封ip,这是怎么回事,是网站太严了还是代码的问题,代码如下,新手爬虫
-
 Python爬取qq music中的音乐url及批量下载
Python爬取qq music中的音乐url及批量下载本文向大家介绍Python爬取qq music中的音乐url及批量下载,包括了Python爬取qq music中的音乐url及批量下载的使用技巧和注意事项,需要的朋友参考一下 前言 qq music上的音乐还是不少的,有些时候想要下载好听的音乐,但有每次在网页下载都是烦人的登录什么的。于是,来了个qqmusic的爬虫。至少我觉得for循环爬虫,最核心的应该就是找到待爬元素所在url吧。下面开始找吧
-
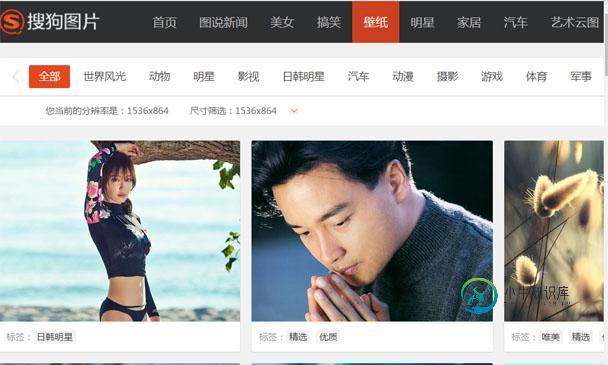 Python爬取网页中的图片(搜狗图片)详解
Python爬取网页中的图片(搜狗图片)详解本文向大家介绍Python爬取网页中的图片(搜狗图片)详解,包括了Python爬取网页中的图片(搜狗图片)详解的使用技巧和注意事项,需要的朋友参考一下 前言 最近几天,研究了一下一直很好奇的爬虫算法。这里写一下最近几天的点点心得。下面进入正文: 你可能需要的工作环境: Python 3.6官网下载 本地下载 我们这里以sogou作为爬取的对象。 首先我们进入搜狗图片http://
-
基于Python爬取fofa网页端数据过程解析
本文向大家介绍基于Python爬取fofa网页端数据过程解析,包括了基于Python爬取fofa网页端数据过程解析的使用技巧和注意事项,需要的朋友参考一下 FOFA-网络空间安全搜索引擎是网络空间资产检索系统(FOFA)是世界上数据覆盖更完整的IT设备搜索引擎,拥有全球联网IT设备更全的DNA信息。探索全球互联网的资产信息,进行资产及漏洞影响范围分析、应用分布统计、应用流行度态势感知等。 安装环境
-
在多个solr索引之间共享爬网nutch数据
我们有数以千计的solr索引/集合共享Nutch抓取的页面。 感谢任何想法或帮助:)
-
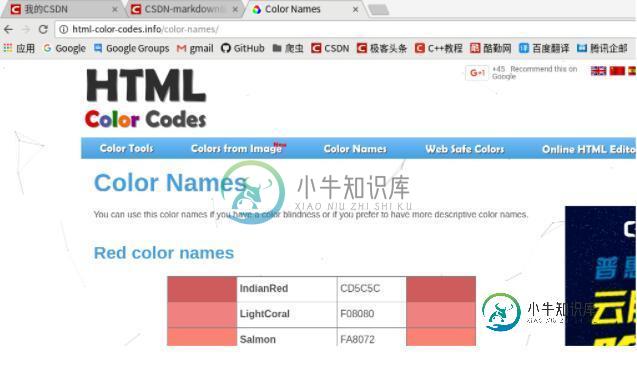 Python爬取数据并写入MySQL数据库的实例
Python爬取数据并写入MySQL数据库的实例本文向大家介绍Python爬取数据并写入MySQL数据库的实例,包括了Python爬取数据并写入MySQL数据库的实例的使用技巧和注意事项,需要的朋友参考一下 首先我们来爬取 http://html-color-codes.info/color-names/ 的一些数据。 按 F12 或 ctrl+u 审查元素,结果如下: 结构很清晰简单,我们就是要爬 tr 标签里面的 style 和 tr 下几