《爬虫》专题
-
一文带你了解Python 四种常见基础爬虫方法介绍
本文向大家介绍一文带你了解Python 四种常见基础爬虫方法介绍,包括了一文带你了解Python 四种常见基础爬虫方法介绍的使用技巧和注意事项,需要的朋友参考一下 一、Urllib方法 Urllib是python内置的HTTP请求库 二、requests方法 –Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库 –urllib还
-
使用Python爬虫库requests发送请求、传递URL参数、定制headers
本文向大家介绍使用Python爬虫库requests发送请求、传递URL参数、定制headers,包括了使用Python爬虫库requests发送请求、传递URL参数、定制headers的使用技巧和注意事项,需要的朋友参考一下 首先我们先引入requests模块 一、发送请求 二、传递URL参数 URL传递参数的形式为:httpbin.org/get?key=val。但是手动的构造很麻烦,这是可以
-
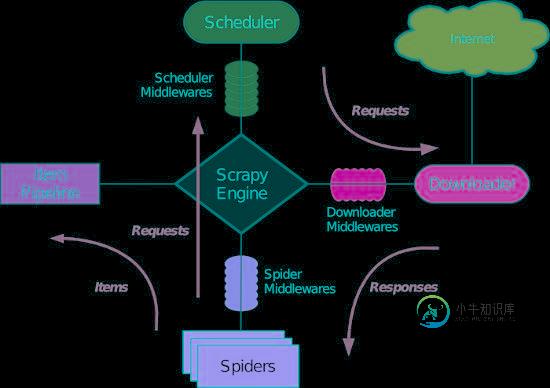 深入剖析Python的爬虫框架Scrapy的结构与运作流程
深入剖析Python的爬虫框架Scrapy的结构与运作流程本文向大家介绍深入剖析Python的爬虫框架Scrapy的结构与运作流程,包括了深入剖析Python的爬虫框架Scrapy的结构与运作流程的使用技巧和注意事项,需要的朋友参考一下 网络爬虫(Web Crawler, Spider)就是一个在网络上乱爬的机器人。当然它通常并不是一个实体的机器人,因为网络本身也是虚拟的东西,所以这个“机器人”其实也就是一段程序,并且它也不是乱爬,而是有一定目的的,并且
-
python 每天如何定时启动爬虫任务(实现方法分享)
本文向大家介绍python 每天如何定时启动爬虫任务(实现方法分享),包括了python 每天如何定时启动爬虫任务(实现方法分享)的使用技巧和注意事项,需要的朋友参考一下 python2.7环境下运行 安装相关模块 想要每天定时启动,最好是把程序放在linux服务器上运行,毕竟linux可以不用关机,即定时任务一直存活; 以上这篇python 每天如何定时启动爬虫任务(实现方法分享)就是小编分享给
-
基于python实现的抓取腾讯视频所有电影的爬虫
本文向大家介绍基于python实现的抓取腾讯视频所有电影的爬虫,包括了基于python实现的抓取腾讯视频所有电影的爬虫的使用技巧和注意事项,需要的朋友参考一下 我搜集了国内10几个电影网站的数据,里面近几十W条记录,用文本没法存,mongodb学习成本非常低,安装、下载、运行起来不会花你5分钟时间。
-
 零基础写python爬虫之使用urllib2组件抓取网页内容
零基础写python爬虫之使用urllib2组件抓取网页内容本文向大家介绍零基础写python爬虫之使用urllib2组件抓取网页内容,包括了零基础写python爬虫之使用urllib2组件抓取网页内容的使用技巧和注意事项,需要的朋友参考一下 版本号:Python2.7.5,Python3改动较大,各位另寻教程。 所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地。 类似于使用程序模拟IE浏览器的功能,把URL作为HTTP请求的
-
 使用Python编写简单网络爬虫抓取视频下载资源
使用Python编写简单网络爬虫抓取视频下载资源本文向大家介绍使用Python编写简单网络爬虫抓取视频下载资源,包括了使用Python编写简单网络爬虫抓取视频下载资源的使用技巧和注意事项,需要的朋友参考一下 我第一次接触爬虫这东西是在今年的5月份,当时写了一个博客搜索引擎,所用到的爬虫也挺智能的,起码比电影来了这个站用到的爬虫水平高多了! 回到用Python写爬虫的话题。 Python一直是我主要使用的脚本语言,没有之一。Python的语言简洁
-
程序员 - scrapy 爬虫,始终获取不到数据,如何解决呢?
求助 scrapy 爬取数据失败,排查了好久都没有找到问题了,实在找不到了 目标:爬取欣欣旅游网的某一城市 各大景点的基本信息 这是我的 sipder 以及 item 代码 spider: item: 这是执行日志: 跟着老师讲的一步一步来的,自己多爬取了几个信息(打开对应的详细网页进行爬取) 始终获取不到任何信息,301重定向错误也试了很多方法,但都没有解决 救救我吧 大佬们
-
 php实现爬取和分析知乎用户数据
php实现爬取和分析知乎用户数据本文向大家介绍php实现爬取和分析知乎用户数据,包括了php实现爬取和分析知乎用户数据的使用技巧和注意事项,需要的朋友参考一下 背景说明:小拽利用php的curl写的爬虫,实验性的爬取了知乎5w用户的基本信息;同时,针对爬取的数据,进行了简单的分析呈现。 php的spider代码和用户dashboard的展现代码,整理后上传github,在个人博客和公众号更新代码库,程序仅供娱乐和学习交流;如果有
-
 SpringBoot中使用Jsoup爬取网站数据的方法
SpringBoot中使用Jsoup爬取网站数据的方法本文向大家介绍SpringBoot中使用Jsoup爬取网站数据的方法,包括了SpringBoot中使用Jsoup爬取网站数据的方法的使用技巧和注意事项,需要的朋友参考一下 爬取数据 导入jar包 新建实体类 编写爬虫工具类 可以看到内容、图片、价格系数爬取 到此这篇关于SpringBoot中使用Jsoup爬取网站数据的方法的文章就介绍到这了,更多相关SpringBoot Jsoup爬取内容请搜索呐
-
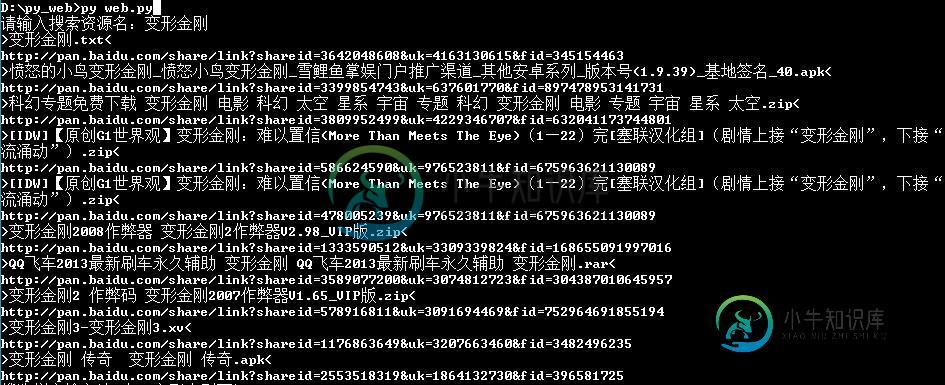 python urllib爬取百度云连接的实例代码
python urllib爬取百度云连接的实例代码本文向大家介绍python urllib爬取百度云连接的实例代码,包括了python urllib爬取百度云连接的实例代码的使用技巧和注意事项,需要的朋友参考一下 翻看自己以前写的程序,发现写过一个爬取盘多多百度云资源的东西,完全是当时想看变形金刚才自己写的,而且当时第一次接触python大概写了有2天才搞出来这个程序,学习python语言,可以看得出来那时候的代码写的真的low。虽然现在也不怎么
-
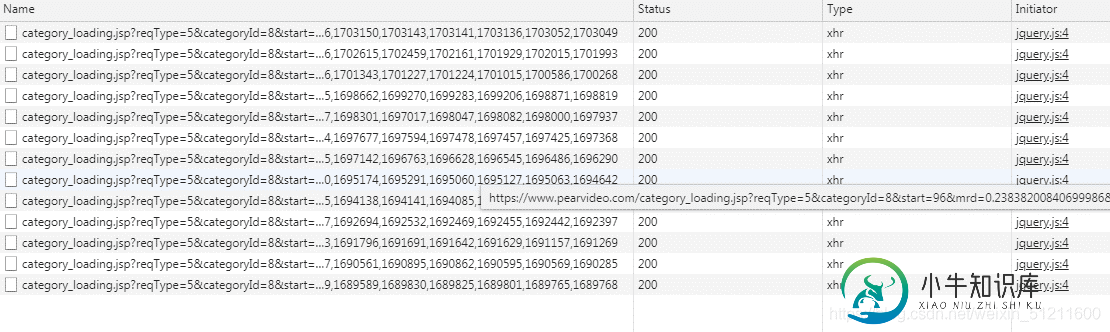 基于python爬取梨视频实现过程解析
基于python爬取梨视频实现过程解析本文向大家介绍基于python爬取梨视频实现过程解析,包括了基于python爬取梨视频实现过程解析的使用技巧和注意事项,需要的朋友参考一下 目标网址:梨视频 然后我们找到科技这一页:https://www.pearvideo.com/category_8。其实你要哪一页都行,你喜欢就行。嘿嘿… 这是动态网站,所以咱们直奔network 然后去到XHR: 找规律,这个应该不难,我就直接贴网址上来咯,
-
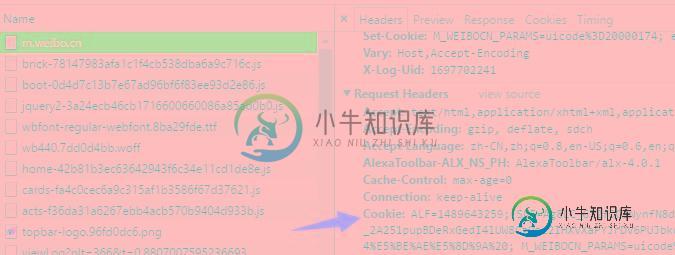 使用python爬取微博数据打造一颗“心”
使用python爬取微博数据打造一颗“心”本文向大家介绍使用python爬取微博数据打造一颗“心”,包括了使用python爬取微博数据打造一颗“心”的使用技巧和注意事项,需要的朋友参考一下 前言 一年一度的虐狗节终于过去了,朋友圈各种晒,晒自拍,晒娃,晒美食,秀恩爱的。程序员在晒什么,程序员在加班。但是礼物还是少不了的,送什么好?作为程序员,我准备了一份特别的礼物,用以往发的微博数据打造一颗“爱心”,我想她一定会感动得哭了吧。哈哈 准备工
-
 scrapy利用selenium爬取豆瓣阅读的全步骤
scrapy利用selenium爬取豆瓣阅读的全步骤本文向大家介绍scrapy利用selenium爬取豆瓣阅读的全步骤,包括了scrapy利用selenium爬取豆瓣阅读的全步骤的使用技巧和注意事项,需要的朋友参考一下 首先创建scrapy项目 命令:scrapy startproject douban_read 创建spider 命令:scrapy genspider douban_spider url 网址:https://read.douba
-
在Scrapy中爬行经过身份验证的会话
问题内容: 我对问题不是很具体(希望通过与Scrapy进行身份验证的会话进行抓取),希望能够从更笼统的答案中得出解决方案。我应该宁可使用这个词。 所以,这是到目前为止的代码: 如你所见,我访问的第一页是登录页面。如果尚未通过身份验证(在函数中),则调用自定义函数,该函数将发布到登录表单中。然后,如果我我验证,我想继续爬行。 问题是我尝试覆盖以登录的功能,现在不再进行必要的调用以刮擦任何其他页面(我