《爬虫》专题
-
刮擦不产生结果(已爬网0页)
试图找出scrapy的工作原理,并使用它在论坛上查找信息。 items.py spider.py 在这个例子中,我试图获取帖子标题的论坛是:https://forum.bodybuilding.nl/fora/supplementen.22/ 然而,我一直没有得到任何结果: 类BodyBuildingSpider(BaseSpider):2017-10-07 00:42:28[scrapy.uti
-
Nutch Crawl-删除每个爬行影响的段
我注意到在每次Nutch抓取过程中,发送到Solr的索引不一致。有时会显示网页的最新更改,有时会显示较旧的更改。 原因 注意到Nutch将旧段的索引提供给Solr。 当前解决方案 在获取之前删除所有旧段,似乎解决了问题。 问题 想知道这种方法是否有任何含义,或者我对此的理解是不正确的。还想知道为什么Nutch在爬行过程中不会自动删除旧段。 谢谢。
-
15. 豆瓣电影Top250信息爬取实战
通过本案例[豆瓣电影Top250信息爬取]锻炼除正则表达式之外三种信息解析方式:Xpath、BeautifulSoup和PyQuery。 爬取url地址:https://movie.douban.com/top250 分析: 分析url地址:https://movie.douban.com/top250 每页25条数据,共计10页 第一页:https://movie.douban.com/top2
-
 python爬虫把url链接编码成gbk2312格式过程解析
python爬虫把url链接编码成gbk2312格式过程解析本文向大家介绍python爬虫把url链接编码成gbk2312格式过程解析,包括了python爬虫把url链接编码成gbk2312格式过程解析的使用技巧和注意事项,需要的朋友参考一下 1. 问题 抓取某个网站,发现请求参数是乱码格式, 这是点击 TextView,发现请求参数如下图所示 3. 那么=%B9%FA%CE%F1%D4%BA%B7%A2%D5%B9%D1%D0%BE%BF%D6%D0%
-
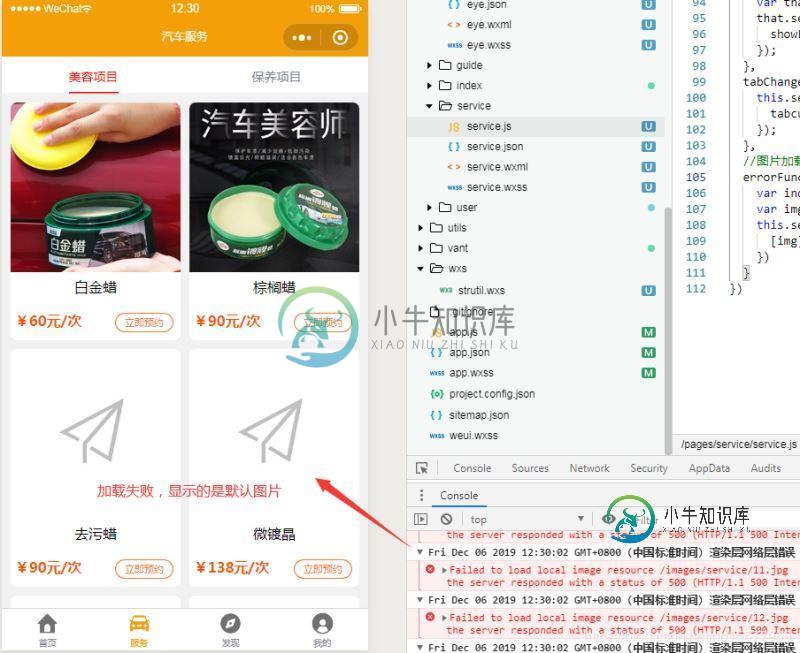 python爬虫模拟浏览器的两种方法实例分析
python爬虫模拟浏览器的两种方法实例分析本文向大家介绍python爬虫模拟浏览器的两种方法实例分析,包括了python爬虫模拟浏览器的两种方法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python爬虫模拟浏览器的两种方法。分享给大家供大家参考,具体如下: 爬虫爬取网站出现403,因为站点做了防爬虫的设置 一、Herders 属性 爬取CSDN博客 爬取结果 urllib.error.HTTPError: HTTP
-
 Python爬虫运用正则表达式的方法和优缺点
Python爬虫运用正则表达式的方法和优缺点本文向大家介绍Python爬虫运用正则表达式的方法和优缺点,包括了Python爬虫运用正则表达式的方法和优缺点的使用技巧和注意事项,需要的朋友参考一下 前言 我看到最近几部电影很火,查了一下猫眼电影上的数据,发现还有个榜单,里面有各种经典和热映电影的排行榜,然后我觉得电影封面图还挺好看的,想着一张一张下载真是费时费力,于是突发奇想,好像可以用一下最近学的东西实现我的需求,学习了正则表达式之后,想着
-
Linux/Nginx如何查看搜索引擎蜘蛛爬虫的行为
本文向大家介绍Linux/Nginx如何查看搜索引擎蜘蛛爬虫的行为,包括了Linux/Nginx如何查看搜索引擎蜘蛛爬虫的行为的使用技巧和注意事项,需要的朋友参考一下 摘要 做好网站SEO优化的第一步就是首先让蜘蛛爬虫经常来你的网站进行光顾,下面的Linux命令可以让你清楚的知道蜘蛛的爬行情况。下面我们针对nginx服务器进行分析,日志文件所在目录:/usr/local/nginx/logs/ac
-
python通过伪装头部数据抵抗反爬虫的实例
本文向大家介绍python通过伪装头部数据抵抗反爬虫的实例,包括了python通过伪装头部数据抵抗反爬虫的实例的使用技巧和注意事项,需要的朋友参考一下 0x00 环境 系统环境:win10 编写工具:JetBrains PyCharm Community Edition 2017.1.2 x64 python 版本:python-3.6.2 抓包工具:Fiddler 4 0x01 头部数据伪装思路
-
Python爬虫框架scrapy实现的文件下载功能示例
本文向大家介绍Python爬虫框架scrapy实现的文件下载功能示例,包括了Python爬虫框架scrapy实现的文件下载功能示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫框架scrapy实现的文件下载功能。分享给大家供大家参考,具体如下: 我们在写普通脚本的时候,从一个网站拿到一个文件的下载url,然后下载,直接将数据写入文件或者保存下来,但是这个需要我们自己一点一
-
 Python爬虫之正则表达式基本用法实例分析
Python爬虫之正则表达式基本用法实例分析本文向大家介绍Python爬虫之正则表达式基本用法实例分析,包括了Python爬虫之正则表达式基本用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫之正则表达式基本用法。分享给大家供大家参考,具体如下: 一、简介 正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为regex、re
-
Python爬虫抓取代理IP并检验可用性的实例
本文向大家介绍Python爬虫抓取代理IP并检验可用性的实例,包括了Python爬虫抓取代理IP并检验可用性的实例的使用技巧和注意事项,需要的朋友参考一下 经常写爬虫,难免会遇到ip被目标网站屏蔽的情况,银次一个ip肯定不够用,作为节约的程序猿,能不花钱就不花钱,那就自己去找吧,这次就写了下抓取 西刺代理上的ip,但是这个网站也反爬!!! 至于如何应对,我觉得可以通过增加延时试试,可能是我抓取的太
-
Python使用Beautiful Soup包编写爬虫时的一些关键点
本文向大家介绍Python使用Beautiful Soup包编写爬虫时的一些关键点,包括了Python使用Beautiful Soup包编写爬虫时的一些关键点的使用技巧和注意事项,需要的朋友参考一下 1.善于利用soup节点的parent属性 比如对于已经得到了如下html代码: 的soup变量eachMonthHeader了。 想要提取其中的 Month的label的值:November 和Ye
-
Python的爬虫包Beautiful Soup中用正则表达式来搜索
本文向大家介绍Python的爬虫包Beautiful Soup中用正则表达式来搜索,包括了Python的爬虫包Beautiful Soup中用正则表达式来搜索的使用技巧和注意事项,需要的朋友参考一下 Beautiful Soup使用时,一般可以通过指定对应的name和attrs去搜索,特定的名字和属性,以找到所需要的部分的html代码。 但是,有时候,会遇到,对于要处理的内容中,其name或att
-
 Java爬虫实战抓取一个网站上的全部链接
Java爬虫实战抓取一个网站上的全部链接本文向大家介绍Java爬虫实战抓取一个网站上的全部链接,包括了Java爬虫实战抓取一个网站上的全部链接的使用技巧和注意事项,需要的朋友参考一下 前言:写这篇文章之前,主要是我看了几篇类似的爬虫写法,有的是用的队列来写,感觉不是很直观,还有的只有一个请求然后进行页面解析,根本就没有自动爬起来这也叫爬虫?因此我结合自己的思路写了一下简单的爬虫。 一 算法简介 程序在思路上采用了广度优先算法,对未遍历过
-
python爬虫获取小区经纬度以及结构化地址
本文向大家介绍python爬虫获取小区经纬度以及结构化地址,包括了python爬虫获取小区经纬度以及结构化地址的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了python爬虫获取小区经纬度、地址的具体代码,供大家参考,具体内容如下 通过小区名称利用百度api可以获取小区的地址以及经纬度,但是由于api返回的值中的地址形式不同,所以可以首先利用小区名称进行一轮爬虫,获取小区的经纬度,然