
python爬虫把url链接编码成gbk2312格式过程解析

1. 问题 抓取某个网站,发现请求参数是乱码格式,

这是点击 TextView,发现请求参数如下图所示
3. 那么=%B9%FA%CE%F1%D4%BA%B7%A2%D5%B9%D1%D0%BE%BF%D6%D0%D0%C4是什么东西啊
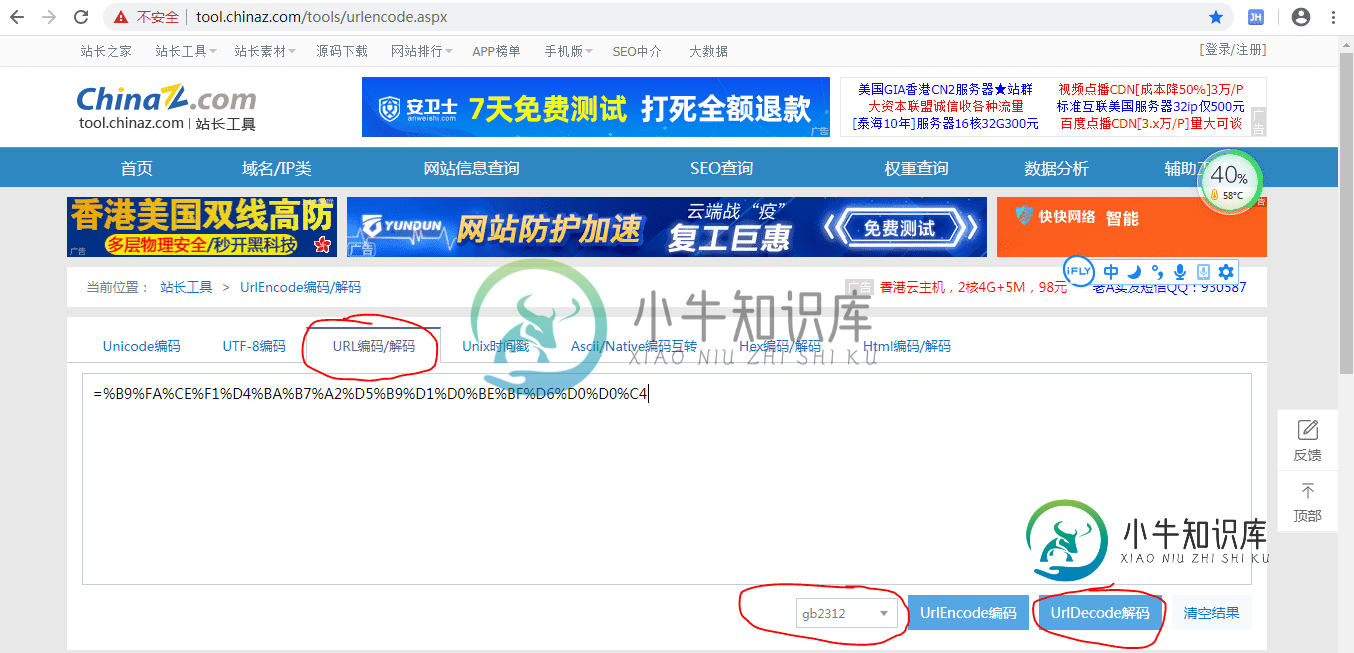
解码后是 =国务院发展研究中心
代码实现:
content = "我爱中国"
import urllib
res = urllib.quote(content.encode('gb2312'))
print res
print "11111111", type(res)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍python爬虫 urllib模块url编码处理详解,包括了python爬虫 urllib模块url编码处理详解的使用技巧和注意事项,需要的朋友参考一下 案例:爬取使用搜狗根据指定词条搜索到的页面数据(例如爬取词条为‘周杰伦'的页面数据) 编码错误 【注意】上述代码中url存在非ascii编码的数据,则该url无效。如果对其发起请求,则会报如下错误: url的特性:url不可以存在非
-
原始content: decode('utf-8')报错: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe8 in position 1: invalid continuation byte decode('utf-8', 'ignore'): decode('gbk', 'ignore'): decode('utf-16', 'ig
-
本文向大家介绍零基础写python爬虫之爬虫的定义及URL构成,包括了零基础写python爬虫之爬虫的定义及URL构成的使用技巧和注意事项,需要的朋友参考一下 一、网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字。 把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。 网络蜘蛛是通过网页的链接地址来寻找网页的。 从网站某一个页面(通常是首页)开始,读取网页的内容
-
本文向大家介绍Python爬虫爬取博客实现可视化过程解析,包括了Python爬虫爬取博客实现可视化过程解析的使用技巧和注意事项,需要的朋友参考一下 源码: 爬虫不是重点,只是拿来爬阅读数量,pyecharts是重点 这次爬的是我自己的博客,一共10页,每页10片文章,正好写了100篇博客 pyecharts安装: pip install wheelpip install pyecharts==0.
-
本文向大家介绍Python爬虫使用浏览器cookies:browsercookie过程解析,包括了Python爬虫使用浏览器cookies:browsercookie过程解析的使用技巧和注意事项,需要的朋友参考一下 很多用Python的人可能都写过网络爬虫,自动化获取网络数据确实是一件令人愉悦的事情,而Python很好的帮助我们达到这种愉悦。然而,爬虫经常要碰到各种登录、验证的阻挠,让人灰心丧气(
-
python爬虫时显示 [WinError 10061] 由于目标计算机积极拒绝,无法连接。 import csv import random import time import pandas as pd import requests from bs4 import BeautifulSoup import matplotlib.pyplot as plt plt.rcParams["font