《爬虫》专题
-
21. 从API爬取天气预报数据
21.1 注册免费API和阅读文档 本节通过一个API接口(和风天气预报)爬取天气信息,该接口为个人开发者提供了一个免费的预报数据(有次数限制)。 首先访问和风天气网,注册一个账户。注册地址:https://console.heweather.com/ 在登陆后的控制台中可以看到个人认证的key(密钥),这个key就是访问API接口的钥匙。 获取key之后阅读API文档:https://www.h
-
14. 使用代理爬取信息实战
14.1 实战目标: 本节目标是利用代理爬取微信公众号的文章信息,从中提取标题、摘要、发布日期、公众号以及url地址等内容。 本节爬取的是搜索关键字为python的,类别为微信的所有文章信息,并将信息存储到MongoDB中。 URL地址:http://weixin.sogou.com/weixin?type=2&query=python&ie=utf8&s_from=input 14.2 准备工作
-
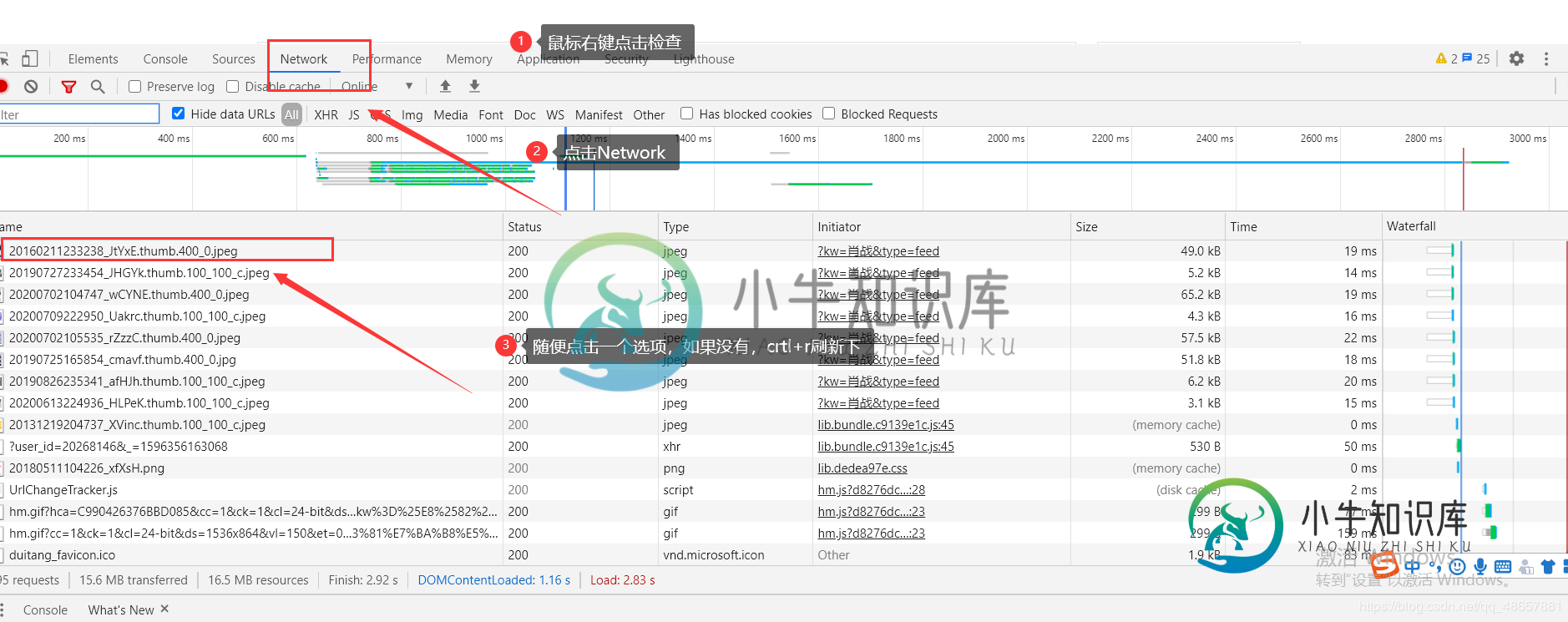 python根据用户需求输入想爬取的内容及页数爬取图片方法详解
python根据用户需求输入想爬取的内容及页数爬取图片方法详解本文向大家介绍python根据用户需求输入想爬取的内容及页数爬取图片方法详解,包括了python根据用户需求输入想爬取的内容及页数爬取图片方法详解的使用技巧和注意事项,需要的朋友参考一下 本次小编向大家介绍的是根据用户的需求输入想爬取的内容及页数。 主要步骤: 1.提示用户输入爬取的内容及页码。 2.根据用户输入,获取网址列表。 3.模拟浏览器向服务器发送请求,获取响应。 4.利用xpath方法找
-
有没有专业搞python爬虫的,对于动态网页怎么爬取,可以私信我,有偿,有没有高效地方法?
最近在学习爬虫,遇到一个动态页面内容的网页,我虽然有办法将它转为html代码,但是效率实在可怜。求一个专业的大神,有偿支持我。
-
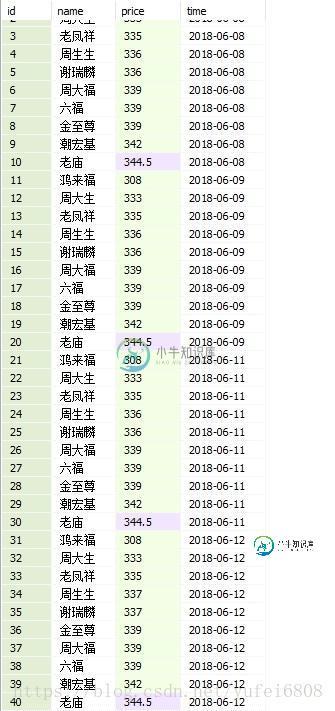 使用python爬虫获取黄金价格的核心代码
使用python爬虫获取黄金价格的核心代码本文向大家介绍使用python爬虫获取黄金价格的核心代码,包括了使用python爬虫获取黄金价格的核心代码的使用技巧和注意事项,需要的朋友参考一下 继续练手,根据之前获取汽油价格的方式获取了金价,暂时没钱投资,看看而已 最近的数据 总结 以上所述是小编给大家介绍的使用python爬虫获取黄金价格的核心代码,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对
-
“围棋之旅”网络爬虫练习中的频道说明
问题内容: 我正在经历“ A Go of Go”,并且一直在编辑大多数课程,以确保我完全理解它们。我对以下练习的答案有疑问: https : //tour.golang.org/concurrency/10,可在此处找到: https //github.com/golang/tour/blob/master/solutions/ webcrawler.go 我对以下部分有疑问: 从通道添加和删除t
-
python制作爬虫并将抓取结果保存到excel中
本文向大家介绍python制作爬虫并将抓取结果保存到excel中,包括了python制作爬虫并将抓取结果保存到excel中的使用技巧和注意事项,需要的朋友参考一下 学习Python也有一段时间了,各种理论知识大体上也算略知一二了,今天就进入实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫。 第一步:分析网站的请求过程 我们在查看拉勾网上的招聘信息的时候,搜索Python,或者是PHP等等
-
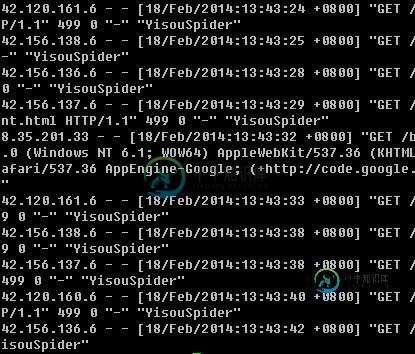 Nginx中配置过滤爬虫的User-Agent的简单方法
Nginx中配置过滤爬虫的User-Agent的简单方法本文向大家介绍Nginx中配置过滤爬虫的User-Agent的简单方法,包括了Nginx中配置过滤爬虫的User-Agent的简单方法的使用技巧和注意事项,需要的朋友参考一下 过去写博客的时候经常出现服务器宕机,网页全部刷不出来,但是Ping服务器的时候又能Ping通。登录SSH看了下top,惊呆了,平均负载13 12 8。瞬间觉得我这是被人DDOS了么?看了下进程基本上都是php-fpm把CPU
-
Python爬虫之pandas基本安装与使用方法示例
本文向大家介绍Python爬虫之pandas基本安装与使用方法示例,包括了Python爬虫之pandas基本安装与使用方法示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫之pandas基本安装与使用方法。分享给大家供大家参考,具体如下: 一、简介: Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决
-
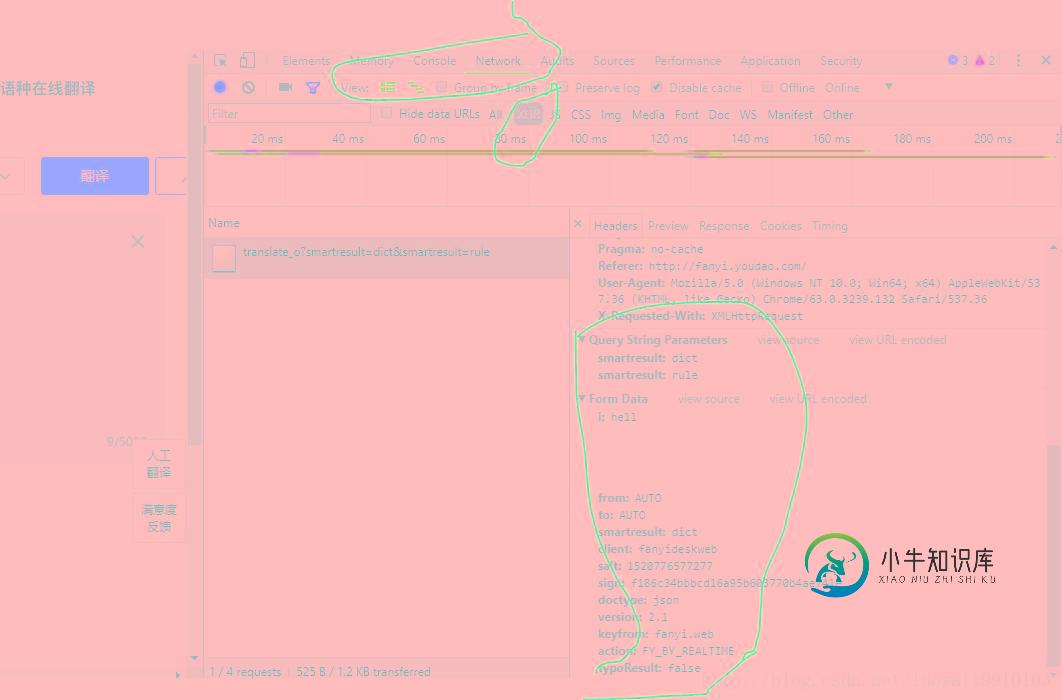 用python3 urllib破解有道翻译反爬虫机制详解
用python3 urllib破解有道翻译反爬虫机制详解本文向大家介绍用python3 urllib破解有道翻译反爬虫机制详解,包括了用python3 urllib破解有道翻译反爬虫机制详解的使用技巧和注意事项,需要的朋友参考一下 前言 最近在学习python 爬虫方面的知识,网上有一博客专栏专门写爬虫方面的,看到用urllib请求有道翻译接口获取翻译结果。发现接口变化很大,用md5加了密,于是自己开始破解。加上网上的其他文章找源码方式并不是通用的,所
-
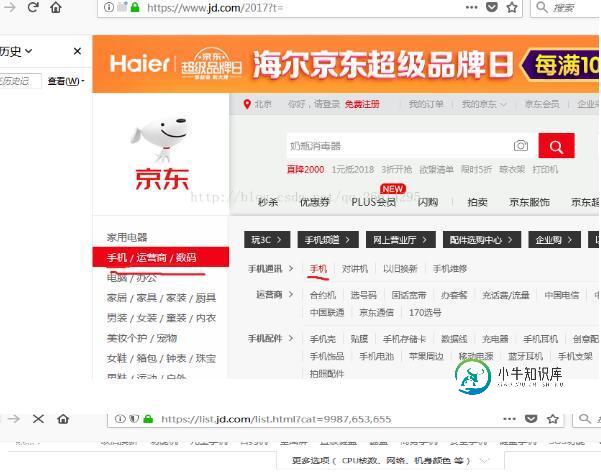 python爬虫获取京东手机图片的图文教程
python爬虫获取京东手机图片的图文教程本文向大家介绍python爬虫获取京东手机图片的图文教程,包括了python爬虫获取京东手机图片的图文教程的使用技巧和注意事项,需要的朋友参考一下 如题,首先当然是要打开京东的手机页面 因为要获取不同页面的所有手机图片,所以我们要跳转到不同页面观察页面地址的规律,这里观察第二页页面 由观察可以得到,第二页的链接地址很有可能是 https://list.jd.com/list.html?cat=99
-
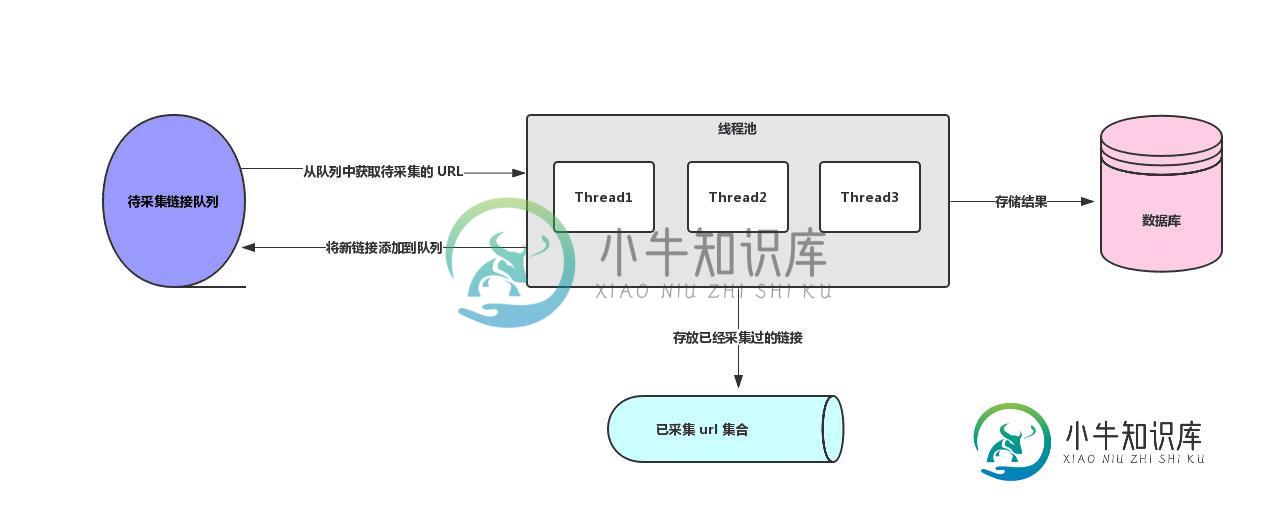 Java多线程及分布式爬虫架构原理解析
Java多线程及分布式爬虫架构原理解析本文向大家介绍Java多线程及分布式爬虫架构原理解析,包括了Java多线程及分布式爬虫架构原理解析的使用技巧和注意事项,需要的朋友参考一下 这是 Java 爬虫系列博文的第五篇,在上一篇Java 爬虫服务器被屏蔽的解决方案中,我们简单的聊反爬虫策略和反反爬虫方法,主要针对的是 IP 被封及其对应办法。前面几篇文章我们把爬虫相关的基本知识都讲的差不多啦。这一篇我们来聊一聊爬虫架构相关的内容。 前面几
-
 Android利用爬虫实现模拟登录的实现实例
Android利用爬虫实现模拟登录的实现实例本文向大家介绍Android利用爬虫实现模拟登录的实现实例,包括了Android利用爬虫实现模拟登录的实现实例的使用技巧和注意事项,需要的朋友参考一下 Android利用爬虫实现模拟登录的实现实例 为了用手机登录校网时不用一遍一遍的输入账号密码,于是决定用爬虫抓取学校登录界面,然后模拟填写本次保存的账号、密码,模拟点击登录按钮。实现过程折腾好几个。 一开始选择的是htmlunit解析登录界面htm
-
Python网络爬虫中的同步与异步示例详解
本文向大家介绍Python网络爬虫中的同步与异步示例详解,包括了Python网络爬虫中的同步与异步示例详解的使用技巧和注意事项,需要的朋友参考一下 一、同步与异步 模板 tips: await表达式中的对象必须是awaitable requests不支持非阻塞 aiohttp是用于异步请求的库 代码 gevent简介 gevent是一个python的并发库,它为各种并发和网络相关的任务提供了整洁的
-
详解Selenium-webdriver绕开反爬虫机制的4种方法
本文向大家介绍详解Selenium-webdriver绕开反爬虫机制的4种方法,包括了详解Selenium-webdriver绕开反爬虫机制的4种方法的使用技巧和注意事项,需要的朋友参考一下 之前爬美团外卖后台的时候出现的问题,各种方式拖动验证码都无法成功,包括直接控制拉动,模拟人工轨迹的随机拖动都失败了,最后发现只要用chrome driver打开页面,哪怕手动登录也不可以,猜测driver肯定