
Nginx中配置过滤爬虫的User-Agent的简单方法

过去写博客的时候经常出现服务器宕机,网页全部刷不出来,但是Ping服务器的时候又能Ping通。登录SSH看了下top,惊呆了,平均负载13 12 8。瞬间觉得我这是被人DDOS了么?看了下进程基本上都是php-fpm把CPU给占了,去看下日志吧。。。
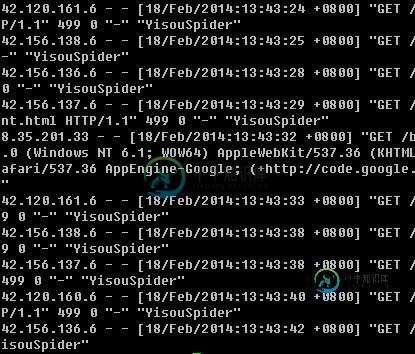
一看不得了,基本上都是被一个User Agent叫"YisouSpider"的东西给刷屏了,一看就不知道是哪的蜘蛛,太没节操了。
找到根目录配置区,增加User Agent过滤判断语句,发现叫"YisouSpider"的直接返回403
注1:如果需要增加多个过滤,这样做
($http_user_agent ~* "Spider1|Spider2|Spider3|Spider4")
,中间用|隔开就行了
注2:如果你是用的是子目录博客,像我的一样,那么要找到 "location /blog/" 这样的区段去修改
location / {
......其它配置
if ($http_user_agent ~* "YisouSpider") {
return 403;
}
}
配置完成wq保存后reload一下nginx,然后使用以下命令自我测试,地址自己改。没装curl的我就没办法了,自己apt或者yum装一个吧,神器来的。
curl -I -A "YisouSpider" www.slyar.com/blog/
看到返回403就可以了,说明配置成功

PS:一些常见爬虫的User-Agent,这些一般就不要过滤了~
百度爬虫
* Baiduspider+(+http://www.baidu.com/search/spider.htm”)
google爬虫
* Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
* Googlebot/2.1 (+http://www.googlebot.com/bot.html)
* Googlebot/2.1 (+http://www.google.com/bot.html)
雅虎爬虫(分别是雅虎中国和美国总部的爬虫)
*Mozilla/5.0 (compatible; Yahoo! Slurp China; http://misc.yahoo.com.cn/help.html”)
*Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp”)
新浪爱问爬虫
*iaskspider/2.0(+http://iask.com/help/help_index.html”)
*Mozilla/5.0 (compatible; iaskspider/1.0; MSIE 6.0)
搜狗爬虫
*Sogou web spider/3.0(+http://www.sogou.com/docs/help/webmasters.htm#07″)
*Sogou Push Spider/3.0(+http://www.sogou.com/docs/help/webmasters.htm#07″)
网易爬虫
*Mozilla/5.0 (compatible; YodaoBot/1.0; http://www.yodao.com/help/webmaster/spider/”; )
MSN爬虫
*msnbot/1.0 (+http://search.msn.com/msnbot.htm”)
-
本文向大家介绍PHP实现简单爬虫的方法,包括了PHP实现简单爬虫的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP实现简单爬虫的方法。分享给大家供大家参考。具体如下: 希望本文所述对大家的php程序设计有所帮助。
-
本文向大家介绍python爬虫爬取图片的简单代码,包括了python爬虫爬取图片的简单代码的使用技巧和注意事项,需要的朋友参考一下 Python是很好的爬虫工具不用再说了,它可以满足我们爬取网络内容的需求,那最简单的爬取网络上的图片,可以通过很简单的方法实现。只需导入正则表达式模块,并利用spider原理通过使用定义函数的方法可以轻松的实现爬取图片的需求。 1、spider原理 spider就是定
-
本文向大家介绍关于爬虫和反爬虫的简略方案分享,包括了关于爬虫和反爬虫的简略方案分享的使用技巧和注意事项,需要的朋友参考一下 前言 爬虫和反爬虫日益成为每家公司的标配系统。 爬虫在情报获取、虚假流量、动态定价、恶意攻击、薅羊毛等方面都能起到很关键的作用,所以每家公司都或多或少的需要开发一些爬虫程序,业界在这方面的成熟的方案也非常多。 有矛就有盾,每家公司也相应的需要反爬虫系统来达到数据保护、系统稳定
-
本文向大家介绍php实现简单爬虫的开发,包括了php实现简单爬虫的开发的使用技巧和注意事项,需要的朋友参考一下 有时候因为工作、自身的需求,我们都会去浏览不同网站去获取我们需要的数据,于是爬虫应运而生,下面是我在开发一个简单爬虫的经过与遇到的问题。 开发一个爬虫,首先你要知道你的这个爬虫是要用来做什么的。我是要用来去不同网站找特定关键字的文章,并获取它的链接,以便我快速阅读。 按照
-
本文向大家介绍Android编写简单的网络爬虫,包括了Android编写简单的网络爬虫的使用技巧和注意事项,需要的朋友参考一下 一、网络爬虫的基本知识 网络爬虫通过遍历互联网络,把网络中的相关网页全部抓取过来,这体现了爬的概念。爬虫如何遍历网络呢,互联网可以看做是一张大图,每个页面看做其中的一个节点,页面的连接看做是有向边。图的遍历方式分为宽度遍历和深度遍历,但是深度遍历可能会在深度上过深的遍历或
-
本文向大家介绍Python制作简单的网页爬虫,包括了Python制作简单的网页爬虫的使用技巧和注意事项,需要的朋友参考一下 1.准备工作: 工欲善其事必先利其器,因此我们有必要在进行Coding前先配置一个适合我们自己的开发环境,我搭建的开发环境是: 操作系统:Ubuntu 14.04 LTS Python版本:2.7.6 代码编辑器:Sublime Text 3.0 这次的网络爬虫需求背景我打算