
python3 实现爬取TOP500的音乐信息并存储到mongoDB数据库中

爬取TOP500的音乐信息,包括排名情况、歌曲名、歌曲时间。
网页版酷狗不能手动翻页进行下一步的浏览,仔细观察第一页的URL:
http://www.kugou.com/yy/rank/home/1-8888.html
这里尝试将1改为2,再进行浏览,恰好是第二页的信息,再改为3,恰好是第三页的信息,多次尝试发现不同的数字即为不同的页面。因此只需更改home/后面的数字即可。由于每页显示的为22首歌曲,所以总共需要23个URL。
import requests
from bs4 import BeautifulSoup
from time import sleep
import pymongo
#连接数据库
client = pymongo.MongoClient(‘localhost',27017)
mydb = client[‘yourdb']
#创建数据库
musicTop = mydb[‘musicTop']
#使用header是用于伪装为浏览器,让爬虫更稳定
Headers = {
‘User-Agent': ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
}
#定义获取信息的函数
def get_info(url):
wd_data = requests.get(url,headers=Headers)
soup = BeautifulSoup(wd_data.text,‘lxml')
#获取排名情况
ranks = soup.select(‘span.pc_temp_num')
#获取标题
titles = soup.select(‘div.pc_temp_songlist > ul > li > a')
#获取时间
times = soup.select(‘span.pc_temp_tips_r > span')
for rank,title,time in zip(ranks,titles,times):
data = {
‘rank':rank.get_text().strip(),
‘singer':title.get_text(),
‘song':title.get_text(),
‘time':time.get_text().strip()
}
musicTop.insert_one(data) #存入数据库中
if name == ‘main':
urls = [‘http://www.kugou.com/yy/rank/home/{}-8888.html'.format(number) for number in range(1,24)]
for url in urls:
get_info(url)
sleep(2)
运行后,爬取的数据在mongoDB数据库中显示如下:
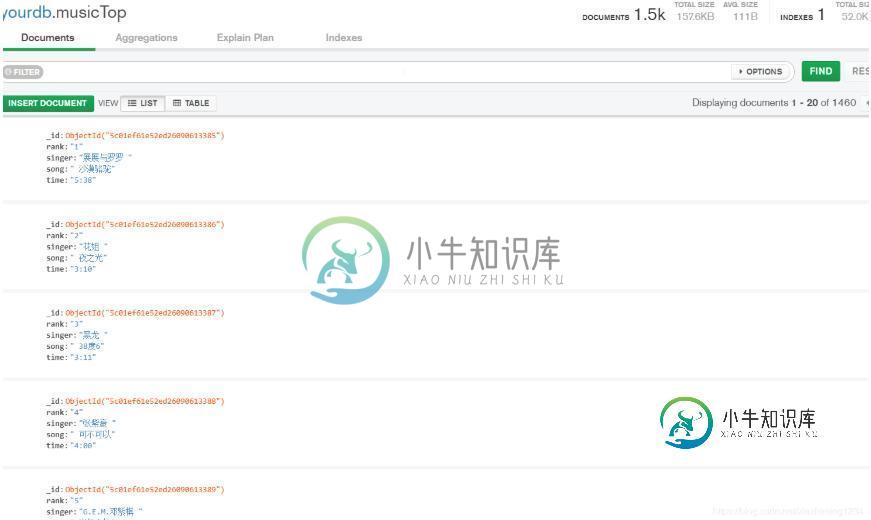
以上这篇python3 实现爬取TOP500的音乐信息并存储到mongoDB数据库中就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
问题内容: 在我国,在线支付并不是一件老事,去年我第一次看到一个网络应用程序直接向本地银行帐户进行支付。 因此,我是一个新手编码的网络支付系统。 我的问题是,将信用卡信息存储到数据库中的最佳实践是什么? 我有很多想法:加密信用卡,数据库安全性限制等。 你做了什么? 问题答案: 不要做 只是涉及太多的风险,通常需要对您进行外部审核,以确保您遵守所有相关的当地法律和安全规定。 有许多第三方公司为您执行
-
本文向大家介绍PHP将session信息存储到数据库的类实例,包括了PHP将session信息存储到数据库的类实例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP将session信息存储到数据库的类。分享给大家供大家参考。具体分析如下: SessionHandlerInterface接口是PHP内置的接口,直接实现就行了 具体可以看php手册关于session_set_save_ha
-
本文向大家介绍python爬虫之爬取百度音乐的实现方法,包括了python爬虫之爬取百度音乐的实现方法的使用技巧和注意事项,需要的朋友参考一下 在上次的爬虫中,抓取的数据主要用到的是第三方的Beautifulsoup库,然后对每一个具体的数据在网页中的selecter来找到它,每一个类别便有一个select方法。对网页有过接触的都知道很多有用的数据都放在一个共同的父节点上,只是其子节点不同。在上次
-
本文向大家介绍Java爬虫 信息抓取的实现,包括了Java爬虫 信息抓取的实现的使用技巧和注意事项,需要的朋友参考一下 今天公司有个需求,需要做一些指定网站查询后的数据的抓取,于是花了点时间写了个demo供演示使用。 思想很简单:就是通过Java访问的链接,然后拿到html字符串,然后就是解析链接等需要的数据。技术上使用Jsoup方便页面的解析,当然Jsoup很方便,也很简单,一行代码就能知道怎么
-
我想知道是否有任何机制可以在Spring Data MongoDB存储库中使用带有注释的?我希望能收到我所拥有的文件数量,而不必获取所有文件。 基本上,这在Java中相当于:
-
本文向大家介绍Python爬取数据并写入MySQL数据库的实例,包括了Python爬取数据并写入MySQL数据库的实例的使用技巧和注意事项,需要的朋友参考一下 首先我们来爬取 http://html-color-codes.info/color-names/ 的一些数据。 按 F12 或 ctrl+u 审查元素,结果如下: 结构很清晰简单,我们就是要爬 tr 标签里面的 style 和 tr 下几