《爬虫》专题
-
基于selenium-java封装chrome、firefox、phantomjs实现爬虫
本文向大家介绍基于selenium-java封装chrome、firefox、phantomjs实现爬虫,包括了基于selenium-java封装chrome、firefox、phantomjs实现爬虫的使用技巧和注意事项,需要的朋友参考一下 2017年一直以来在公司负责爬虫项目相关工程,主要业务有预定、库存、在开发中也遇到很多问题,随手记录一下,后续会持续更新。 chrome、firefox、p
-
python爬虫(入门教程、视频教程) 原创
本文向大家介绍python爬虫(入门教程、视频教程) 原创,包括了python爬虫(入门教程、视频教程) 原创的使用技巧和注意事项,需要的朋友参考一下 python的版本经过了python2.x和python3.x等版本,无论哪种版本,关于python爬虫相关的知识是融会贯通的,呐喊教程关于爬虫这个方便整理过很多有价值的教程,小编通过本文章给大家做一个关于python爬虫相关知识的总结,以下就是全
-
 nodeJs爬虫获取数据简单实现代码
nodeJs爬虫获取数据简单实现代码本文向大家介绍nodeJs爬虫获取数据简单实现代码,包括了nodeJs爬虫获取数据简单实现代码的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了nodeJs爬虫获取数据代码,供大家参考,具体内容如下 效果图: 以上就是nodeJs爬虫获取数据的相关代码,希望对大家的学习有所帮助。
-
 nodejs制作爬虫实现批量下载图片
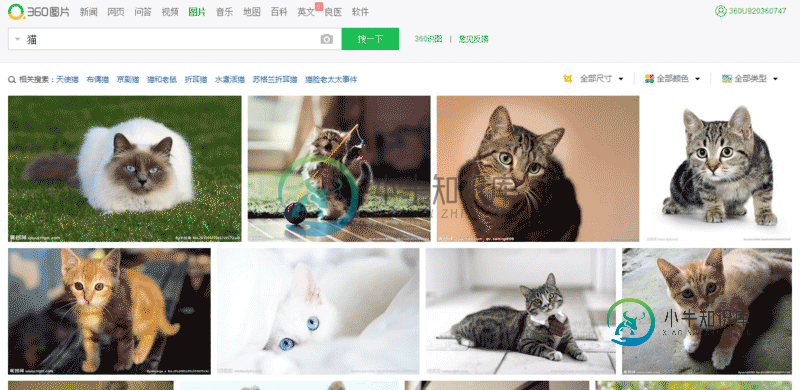
nodejs制作爬虫实现批量下载图片本文向大家介绍nodejs制作爬虫实现批量下载图片,包括了nodejs制作爬虫实现批量下载图片的使用技巧和注意事项,需要的朋友参考一下 今天想获取一大批猫的图片,然后就在360流浪器搜索框中输入 猫 ,然后点击图片。就看到了一大波猫的图片: http://image.so.com/i?q=%E7%8... ,我在想啊,要是审查元素,一张张手动下载,多麻烦,所以打算写程序来实现。不写不知道,一写发现
-
Nodejs实现爬虫抓取数据实例解析
本文向大家介绍Nodejs实现爬虫抓取数据实例解析,包括了Nodejs实现爬虫抓取数据实例解析的使用技巧和注意事项,需要的朋友参考一下 开始之前请先确保自己安装了Node.js环境,如果没有安装,大家可以到呐喊教程下载安装。 1.在项目文件夹安装两个必须的依赖包 superagent 是一个轻量的,渐进式的ajax api,可读性好,学习曲线低,内部依赖nodejs原生的请求api,适用于node
-
 Python爬虫PyQuery库基本用法入门教程
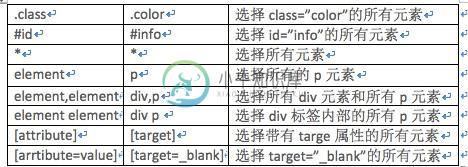
Python爬虫PyQuery库基本用法入门教程本文向大家介绍Python爬虫PyQuery库基本用法入门教程,包括了Python爬虫PyQuery库基本用法入门教程的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫PyQuery库基本用法。分享给大家供大家参考,具体如下: PyQuery库也是一个非常强大又灵活的网页解析库,如果你有前端开发经验的,都应该接触过jQuery,那么PyQuery就是你非常绝佳的选择,PyQu
-
Python爬虫使用浏览器cookies:browsercookie过程解析
本文向大家介绍Python爬虫使用浏览器cookies:browsercookie过程解析,包括了Python爬虫使用浏览器cookies:browsercookie过程解析的使用技巧和注意事项,需要的朋友参考一下 很多用Python的人可能都写过网络爬虫,自动化获取网络数据确实是一件令人愉悦的事情,而Python很好的帮助我们达到这种愉悦。然而,爬虫经常要碰到各种登录、验证的阻挠,让人灰心丧气(
-
 详解python3 + Scrapy爬虫学习之创建项目
详解python3 + Scrapy爬虫学习之创建项目本文向大家介绍详解python3 + Scrapy爬虫学习之创建项目,包括了详解python3 + Scrapy爬虫学习之创建项目的使用技巧和注意事项,需要的朋友参考一下 最近准备做一个关于scrapy框架的实战,爬取腾讯社招信息并存储,这篇博客记录一下创建项目的步骤 pycharm是无法创建一个scrapy项目的 因此,我们需要用命令行的方法新建一个scrapy项目 请确保已经安装了scrapy
-
Python常用爬虫代码总结方便查询
本文向大家介绍Python常用爬虫代码总结方便查询,包括了Python常用爬虫代码总结方便查询的使用技巧和注意事项,需要的朋友参考一下 beautifulsoup解析页面 unicode编码转中文 url encode的解码与解码 html转义字符的解码 base64的编码与解码 过滤emoji表情 完全过滤script和style标签 过滤html的标签,但保留标签里的内容 时间操作 数据库操作
-
 Java爬虫抓取视频网站下载链接
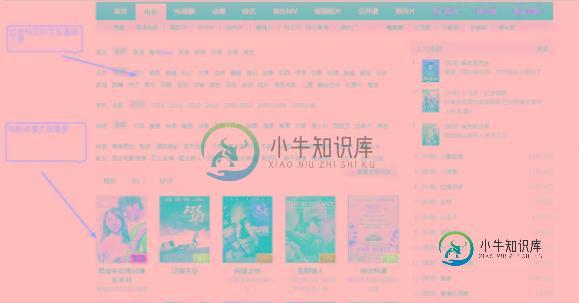
Java爬虫抓取视频网站下载链接本文向大家介绍Java爬虫抓取视频网站下载链接,包括了Java爬虫抓取视频网站下载链接的使用技巧和注意事项,需要的朋友参考一下 本篇文章抓取目标网站的链接的基础上,进一步提高难度,抓取目标页面上我们所需要的内容并保存在数据库中。这里的测试案例选用了一个我常用的电影下载网站(http://www.80s.la/)。本来是想抓取网站上的所有电影的下载链接,后来感觉需要的时间太长,因此改成了抓取2015
-
Python爬虫入门有哪些基础知识点
本文向大家介绍Python爬虫入门有哪些基础知识点,包括了Python爬虫入门有哪些基础知识点的使用技巧和注意事项,需要的朋友参考一下 1、什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来。想抓取什么?这个由你来控制它咯。 比如它在抓取一个网页,在这个网中他发现了一条道路,其实就是指向
-
nginx修改配置限制恶意爬虫频率
本文向大家介绍nginx修改配置限制恶意爬虫频率,包括了nginx修改配置限制恶意爬虫频率的使用技巧和注意事项,需要的朋友参考一下 如何在nginx中限制恶意网络爬虫抓取内容呢?也就是限制下恶意爬虫的抓取频率。下面来一起看看。 今天在微博发现@金荣叶 的处理方法很灵活,可以动态设定一个爬虫的频率,达到减轻服务器负载,并且不至于封杀爬虫。 超过设置的限定频率,就会给spider一个503。 总结 以
-
使用PyV8在Python爬虫中执行js代码
本文向大家介绍使用PyV8在Python爬虫中执行js代码,包括了使用PyV8在Python爬虫中执行js代码的使用技巧和注意事项,需要的朋友参考一下 前言 可能很多人会觉得这是一个奇葩的需求,爬虫去好好的爬数据不就行了,解析js干嘛?吃饱了撑的? 搜索一下互联网上关于这个问题还真不少,但是大多数童鞋是因为自己的js基础太烂,要么是HTML基础烂,要么ajax基础烂,反正各方面都很烂。基础这么渣不
-
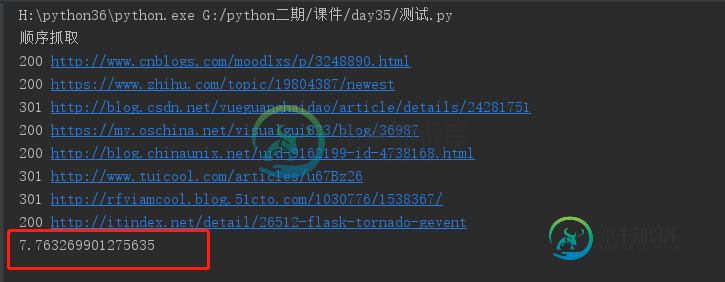 Python并发爬虫常用实现方法解析
Python并发爬虫常用实现方法解析本文向大家介绍Python并发爬虫常用实现方法解析,包括了Python并发爬虫常用实现方法解析的使用技巧和注意事项,需要的朋友参考一下 在进行单个爬虫抓取的时候,我们不可能按照一次抓取一个url的方式进行网页抓取,这样效率低,也浪费了cpu的资源。目前python上面进行并发抓取的实现方式主要有以下几种:进程,线程,协程。进程不在的讨论范围之内,一般来说,进程是用来开启多个spider,比如我们开
-
Python小白学习爬虫常用请求报头
本文向大家介绍Python小白学习爬虫常用请求报头,包括了Python小白学习爬虫常用请求报头的使用技巧和注意事项,需要的朋友参考一下 客户端HTTP请求 URL只是标识资源的位置,而HTTP是用来提交和获取资源。客户端发送一个HTTP请求到服务器的请求消息,包括以下格式: 请求行、请求头部、空行、请求数据 一个典型的HTTP请求 常用请求报头 1. Host (主机和端口号) Host:对应网址