《爬虫》专题
-
python爬虫中多线程的使用详解
本文向大家介绍python爬虫中多线程的使用详解,包括了python爬虫中多线程的使用详解的使用技巧和注意事项,需要的朋友参考一下 queue介绍 queue是python的标准库,俗称队列.可以直接import引用,在python2.x中,模块名为Queue。python3直接queue即可 在python中,多个线程之间的数据是共享的,多个线程进行数据交换的时候,不能够保证数据的安全性和一致性
-
PHP一个简单的无需刷新爬虫
本文向大家介绍PHP一个简单的无需刷新爬虫,包括了PHP一个简单的无需刷新爬虫的使用技巧和注意事项,需要的朋友参考一下 由于只是一个小示例,所以过程化简单写了,小菜随便参考,大神大可点解 接下的入表库当然就不写了,那些更小意思了~就此别过吧~ 总结 以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对呐喊教程的支持。如果你想了解更多相关内容请查看下面相
-
 PHP+HTML+JavaScript+Css实现简单爬虫开发
PHP+HTML+JavaScript+Css实现简单爬虫开发本文向大家介绍PHP+HTML+JavaScript+Css实现简单爬虫开发,包括了PHP+HTML+JavaScript+Css实现简单爬虫开发的使用技巧和注意事项,需要的朋友参考一下 开发一个爬虫,首先你要知道你的这个爬虫是要用来做什么的。我是要用来去不同网站找特定关键字的文章,并获取它的链接,以便我快速阅读。 按照个人习惯,我首先要写一个界面,理清下思路。 1、去不同网站。那么我们需
-
PHP代码实现爬虫记录——超管用
本文向大家介绍PHP代码实现爬虫记录——超管用,包括了PHP代码实现爬虫记录——超管用的使用技巧和注意事项,需要的朋友参考一下 实现爬虫记录本文从创建crawler 数据库,robot.php记录来访的爬虫从而将信息插入数据库crawler,然后从数据库中就可以获得所有的爬虫信息。实现代码具体如下: 数据库设计 以下文件 robot.php 记录来访的爬虫,并将信息写入数据库: 成功了,现在访问数
-
python制作花瓣网美女图片爬虫
本文向大家介绍python制作花瓣网美女图片爬虫,包括了python制作花瓣网美女图片爬虫的使用技巧和注意事项,需要的朋友参考一下 花瓣图片的加载使用了延迟加载的技术,源代码只能下载20多张图片,修改后基本能下载所有的了,只是速度有点慢,后面再优化下
-
python3之微信文章爬虫实例讲解
本文向大家介绍python3之微信文章爬虫实例讲解,包括了python3之微信文章爬虫实例讲解的使用技巧和注意事项,需要的朋友参考一下 前提: python3.4 windows 作用:通过搜狗的微信搜索接口http://weixin.sogou.com/来搜索相关微信文章,并将标题及相关链接导入Excel表格中 说明:需xlsxwriter模块,另程序编写时间为2017/7/11,以免之后程序无
-
分享一个简单的java爬虫框架
本文向大家介绍分享一个简单的java爬虫框架,包括了分享一个简单的java爬虫框架的使用技巧和注意事项,需要的朋友参考一下 反复给网站编写不同的爬虫逻辑太麻烦了,自己实现了一个小框架 可以自定义的部分有: 请求方式(默认为Getuser-agent为谷歌浏览器的设置),可以通过实现RequestSet接口来自定义请求方式 储存方式(默认储存在f盘的html文件夹下),可以通过SaveUtil接口来
-
Python无头爬虫下载文件的实现
本文向大家介绍Python无头爬虫下载文件的实现,包括了Python无头爬虫下载文件的实现的使用技巧和注意事项,需要的朋友参考一下 有些页面并不能直接用requests获取到内容,会动态执行一些js代码生成内容。这个文章主要是对付那些特殊页面的,比如必须要进行js调用才能下载的情况。 安装chrome 安装chromedriver 淘宝源(推荐) 感谢这篇博客 上述步骤可以选择适合自己的版本下
-
Python 爬虫之Beautiful Soup模块使用指南
本文向大家介绍Python 爬虫之Beautiful Soup模块使用指南,包括了Python 爬虫之Beautiful Soup模块使用指南的使用技巧和注意事项,需要的朋友参考一下 爬取网页的流程一般如下: 选着要爬的网址(url) 使用 python 登录上这个网址(urlopen、requests 等) 读取网页信息(read() 出来) 将读取的信息放入 BeautifulSoup 使用
-
 python爬虫之xpath的基本使用详解
python爬虫之xpath的基本使用详解本文向大家介绍python爬虫之xpath的基本使用详解,包括了python爬虫之xpath的基本使用详解的使用技巧和注意事项,需要的朋友参考一下 一、简介 XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。 二、
-
 node实现爬虫的几种简易方式
node实现爬虫的几种简易方式本文向大家介绍node实现爬虫的几种简易方式,包括了node实现爬虫的几种简易方式的使用技巧和注意事项,需要的朋友参考一下 说到爬虫大家可能会觉得很NB的东西,可以爬小电影,羞羞图,没错就是这样的。在node爬虫方面,我也是个新人,这篇文章主要是给大家分享几种实现node 爬虫的方式。第一种方式,采用node,js中的 superagent+request + cheerio。cheerio是必须
-
浅析python实现scrapy定时执行爬虫
本文向大家介绍浅析python实现scrapy定时执行爬虫,包括了浅析python实现scrapy定时执行爬虫的使用技巧和注意事项,需要的朋友参考一下 项目需要程序能够放在超算中心定时运行,于是针对scrapy写了一个定时爬虫的程序main.py ,直接放在scrapy的存储代码的目录中就能设定时间定时多次执行。 最简单的方法:直接使用Timer类 小伙伴有种方法是使用 她的程序运行正常可以定时多
-
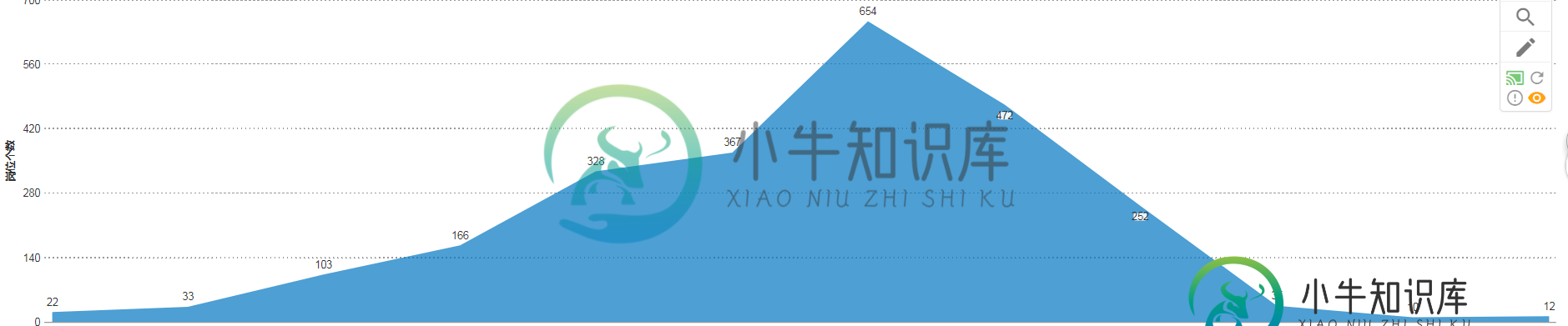 JAVA超级简单的爬虫实例讲解
JAVA超级简单的爬虫实例讲解本文向大家介绍JAVA超级简单的爬虫实例讲解,包括了JAVA超级简单的爬虫实例讲解的使用技巧和注意事项,需要的朋友参考一下 爬取整个页面的数据,并进行有效的提取信息,注释都有就不废话了: 上一张自己爬取的图片,并用fusioncharts生成报表(一般抓取的是int类型的数据的话,生成报表可以很直观) 以上这篇JAVA超级简单的爬虫实例讲解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希
-
十一、Python网络爬虫进阶实战(下)
-
十分钟掌握最强大的 python 爬虫
安装方法 执行 yum install libffi-devel yum install openssl-devel pip install scrapy scrapy的代码会安装在 /usr/local/lib/python2.7/site-packages/scrapy 中文文档在 http://scrapy-chs.readthedocs.io/zh_CN/latest/ 使用样例 创建