
Rapid Miner不保存爬网结果

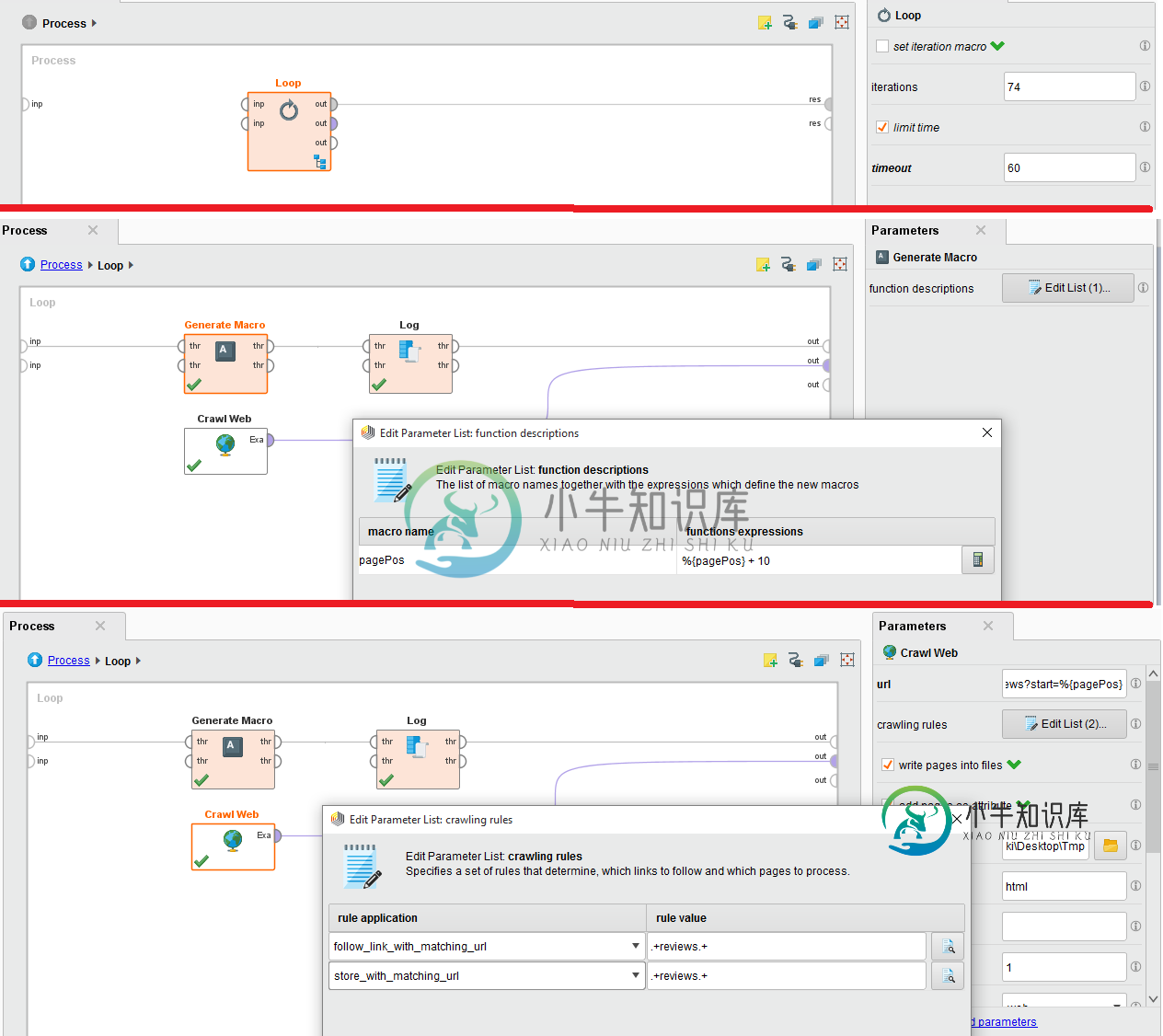
我试图从IMDB网站抓取特定电影评论的评论。为此,我使用抓取网络,我有内嵌循环,因为有74个页面。
附件是配置的图像。请帮忙。我深陷其中。
爬网网站的URL为:http://www.imdb.com/title/tt0454876/reviews?start=%{pagePos}
共有1个答案

当我尝试它时,我得到了403禁止错误,因为IMDB服务认为我是一个机器人。将Loop与Crawl Web一起使用是不好的做法,因为Loop运算符不实现任何等待。
此过程可以简化为仅由爬网操作员执行。关键参数包括:
- URL-将此设置为http://www.imdb.com/title/tt0454876
- 最大页数-设置为79页或任何您需要的数字
- 最大页面大小-将其设置为1000
- 爬网规则-将这些规则设置为您指定的规则
- output dir-选择一个文件夹来存储内容
这是有效的,因为爬行操作员将计算出所有可能的匹配规则的URL,并将存储那些也匹配的URL。访问将延迟1000毫秒(延迟参数),以避免在服务器上触发机器人排除。
希望这能让你开始。
-
RapidMiner是世界领先的数据挖掘解决方案,在一个非常大的程度上有着先进技术。它数据挖掘任务涉及范围广泛,包括各种数据艺术,能简化数据挖掘过程的设计和评价。 功能和特点 免费提供数据挖掘技术和库 100%用Java代码(可运行在操作系统) 数据挖掘过程简单,强大和直观 内部XML保证了标准化的格式来表示交换数据挖掘过程 可以用简单脚本语言自动进行大规模进程 多层次的数据视图,确保有效和透明的
-
试图找出scrapy的工作原理,并使用它在论坛上查找信息。 items.py spider.py 在这个例子中,我试图获取帖子标题的论坛是:https://forum.bodybuilding.nl/fora/supplementen.22/ 然而,我一直没有得到任何结果: 类BodyBuildingSpider(BaseSpider):2017-10-07 00:42:28[scrapy.uti
-
本文向大家介绍python制作爬虫并将抓取结果保存到excel中,包括了python制作爬虫并将抓取结果保存到excel中的使用技巧和注意事项,需要的朋友参考一下 学习Python也有一段时间了,各种理论知识大体上也算略知一二了,今天就进入实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫。 第一步:分析网站的请求过程 我们在查看拉勾网上的招聘信息的时候,搜索Python,或者是PHP等等
-
本文向大家介绍详解Java两种方式简单实现:爬取网页并且保存,包括了详解Java两种方式简单实现:爬取网页并且保存的使用技巧和注意事项,需要的朋友参考一下 对于网络,我一直处于好奇的态度。以前一直想着写个爬虫,但是一拖再拖,懒得实现,感觉这是一个很麻烦的事情,出现个小错误,就要调试很多时间,太浪费时间。 后来一想,既然早早给自己下了保证,就先实现它吧,从简单开始,慢慢增加功能,有时间就实现一个,并
-
4.3 使用Pipeline保存结果 好了,爬虫编写完成,现在我们可能还有一个问题:我如果想把抓取的结果保存下来,要怎么做呢?WebMagic用于保存结果的组件叫做Pipeline。例如我们通过“控制台输出结果”这件事也是通过一个内置的Pipeline完成的,它叫做ConsolePipeline。那么,我现在想要把结果用Json的格式保存下来,怎么做呢?我只需要将Pipeline的实现换成"Jso
-
POI释义:“Point of Interest”的缩写,中文可以翻译为“兴趣点”。在地理信息系统中,一个POI可以是一栋房子、一个商铺、一个邮筒、一个公交站等。 POI 点搜索必选先选择地区 再点击搜索框,输入关键词,回车 查询结果列表里,可将搜索到的POI点选中,在地图上,点击“保存为网点”,保存该POI点作为网点;点击“复制”按钮,可以复制该POI点的经纬度