《爬虫》专题
-
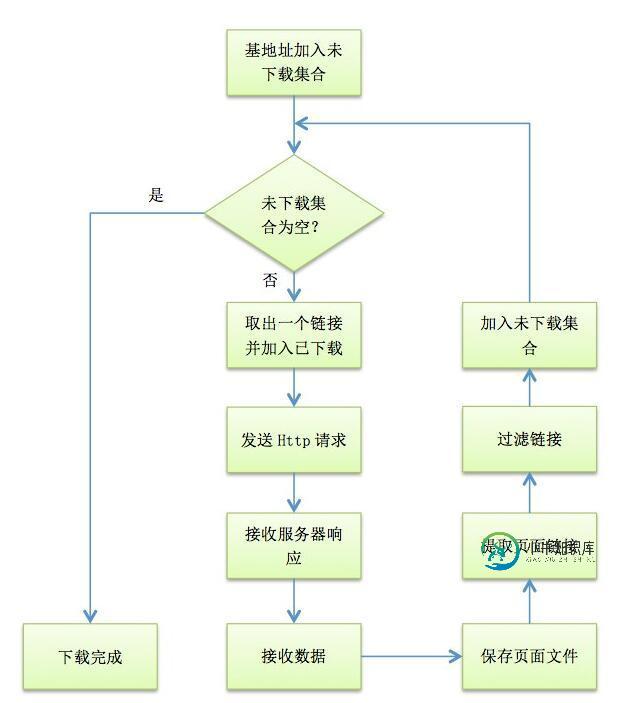 利用C#实现网络爬虫
利用C#实现网络爬虫本文向大家介绍利用C#实现网络爬虫,包括了利用C#实现网络爬虫的使用技巧和注意事项,需要的朋友参考一下 网络爬虫在信息检索与处理中有很大的作用,是收集网络信息的重要工具。 接下来就介绍一下爬虫的简单实现。 爬虫的工作流程如下 爬虫自指定的URL地址开始下载网络资源,直到该地址和所有子地址的指定资源都下载完毕为止。 下面开始逐步分析爬虫的实现。 1. 待下载集合与已下载集合 为了保存需要下载的URL
-
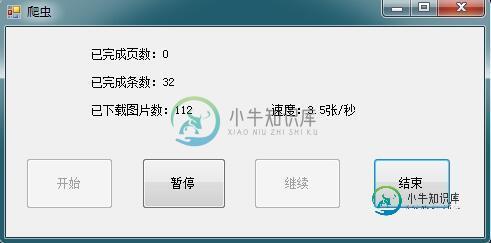 基于C#实现网页爬虫
基于C#实现网页爬虫本文向大家介绍基于C#实现网页爬虫,包括了基于C#实现网页爬虫的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了基于C#实现网页爬虫的详细代码,供大家参考,具体内容如下 HTTP请求工具类: 功能: 1、获取网页html 2、下载网络图片 多线程爬取网页代码: 截图: 以上就是本文的全部内容,希望对大家的学习有所帮助。
-
24. 爬虫项目架构设计
1. 数据库设计: 为了方便后续的数据处理,将所有图书信息都汇总的一张数据表中。 创建数据库:doubandb 进入数据库创建数据表:books 表中字段: [ ID号、书名、作者、出版社、原作名、译者、出版年、页数、 定价、装帧、丛书、ISBN、评分、评论人数 ] 数据表结构: CREATE TABLE `books` (
-
23. 爬虫项目需求分析
1 项目名称 《豆瓣读书信息爬取项目》 2 项目描述: 使用Python编程语言编写一个网络爬虫项目,将豆瓣读书网站上的所有图书信息爬取下来,并存储到MySQL数据库中。 爬取信息字段要求: [ID号、书名、作者、出版社、原作名、译者、出版年、页数、定价、装帧、丛书、ISBN、评分、评论人数] 3 爬取网站过程分析: 打开豆瓣读书的首页:https://book.douban.com/ 在豆瓣读书
-
八、Python网络爬虫基础(下)
-
7. 网络爬虫基础使用
urllib介绍: 在Python2版本中,有urllib和urlib2两个库可以用来实现request的发送。 而在Python3中,已经不存在urllib2这个库了,统一为urllib。 Python3 urllib库官方链接:https://docs.python.org/3/library/urllib.html urllib中包括了四个模块,包括: urllib.request:可以用来
-
6. 网络爬虫工作原理
网络爬虫使用的技术--数据抓取: 在爬虫实现上,除了scrapy框架之外,python有许多与此相关的库可供使用。其中,在数据抓取方面包括: urllib2(urllib3)、requests、mechanize、selenium、splinter; 其中,urllib2(urllib3)、requests、mechanize用来获取URL对应的原始响应内容;而selenium、splinter通
-
七、Python网络爬虫基础(上)
-
大话爬虫的实践技巧
大话爬虫的实践技巧 图1-意淫爬虫与反爬虫间的对决 数据的重要性 如今已然是大数据时代,数据正在驱动着业务开发,驱动着运营手段,有了数据的支撑可以对用户进行用户画像,个性化定制,数据可以指明方案设计和决策优化方向,所以互联网产品的开发都是离不开对数据的收集和分析,数据收集的一种是方式是通过上报API进行自身平台用户交互情况的捕获,还有一种手段是通过开发爬虫程序,爬取竞品平台的数据,后面就重点说下爬
-
大话爬虫的基本套路
大话爬虫的基本套路 什么是爬虫? 网络爬虫也叫网络蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘蛛就是在网上爬来爬去的蜘蛛,爬虫程序通过请求url地址,根据响应的内容进行解析采集数据, 比如:如果响应内容是html,分析dom结构,进行dom解析、或者正则匹配,如果响应内容是xml/json数据,就可以转数据对象,然后对数据进行解析。 有什么作用? 通过有效的爬虫手段批量采集数据,可以降低人工成
-
5. 使用注解编写爬虫
5.使用注解编写爬虫 WebMagic支持使用独有的注解风格编写一个爬虫,引入webmagic-extension包即可使用此功能。 在注解模式下,使用一个简单对象加上注解,可以用极少的代码量就完成一个爬虫的编写。对于简单的爬虫,这样写既简单又容易理解,并且管理起来也很方便。这也是WebMagic的一大特色,我戏称它为OEM(Object/Extraction Mapping)。 注解模式的开发方
-
 WebMagic 爬虫框架中文文档
WebMagic 爬虫框架中文文档WebMagic是我业余开发的一款简单灵活的爬虫框架。基于它你可以很容易的编写一个爬虫。 这本小书以WebMagic入手,一方面讲解WebMagic的使用方式,另一方面讲解爬虫开发的一些惯用方案。
-
 Python 爬虫学习系列教程
Python 爬虫学习系列教程网络爬虫,即 Web Spider,是一个很形象的名字。目前爬虫开发的语言的主要是 Python,本教程是作者实际开发使用的心得总结,还附加几个小的爬虫案例,帮助读者更好的学习 Python 开发爬虫。 适用人群 适用于爬虫初学者,如果你对高效抓取数据有兴趣,那么本教程将会是你不错的选择。 学习前提 学习本教程前,你需要对 Python 语言有一定的了解。 版本信息 书中演示代码基于以下版本: 语
-
示例代码 - 多进程爬虫
EasySwoole利用redis队列+定时器+task进程实现的一个多进程爬虫。直接上代码 添加Redis配置信息 修改配置文件,添加Redis配置 "REDIS"=>array( "HOST"=>'', "PORT"=>6379, "AUTH"=>"" ) 封装Redis namespace AppUtilityDb; use ConfConfig; class Re
-
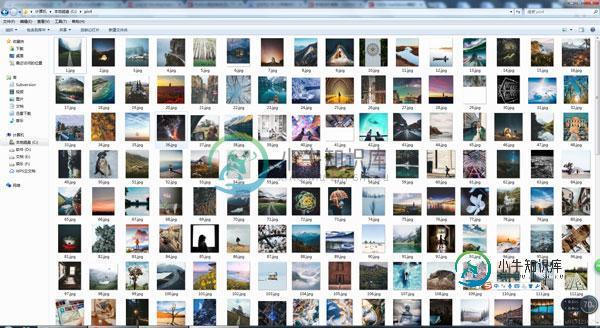 Python实现爬取百度贴吧帖子所有楼层图片的爬虫示例
Python实现爬取百度贴吧帖子所有楼层图片的爬虫示例本文向大家介绍Python实现爬取百度贴吧帖子所有楼层图片的爬虫示例,包括了Python实现爬取百度贴吧帖子所有楼层图片的爬虫示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python实现爬取百度贴吧帖子所有楼层图片的爬虫。分享给大家供大家参考,具体如下: 下载百度贴吧帖子图片,好好看 python2.7版本: PS:这里再为大家提供2款非常方便的正则表达式工具供大家参考使用: Ja