
c# Selenium爬取数据时防止webdriver封爬虫的方法

背景
大家在使用Selenium + Chromedriver爬取网站信息的时候,以为这样就能做到不被网站的反爬虫机制发现。但是实际上很多参数和实际浏览器还是不一样的,只要网站进行判断处理,就能轻轻松松识别你是否使用了Selenium + Chromedriver模拟浏览器。其中
window.navigator.webdriver
就是很重要的一个。
问题窥探
正常浏览器打开是这样的
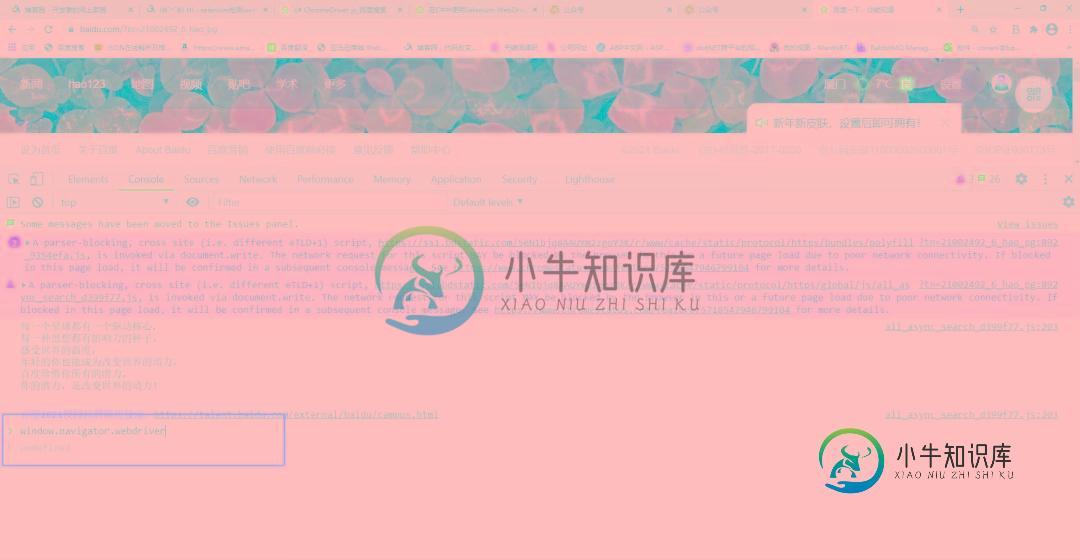
模拟器打开是这样的
ChromeOptions options = null;
IWebDriver driver = null;
try
{
options = new ChromeOptions();
options.AddArguments("--ignore-certificate-errors");
options.AddArguments("--ignore-ssl-errors");
// options.AddExcludedArgument("enable-automation");
// options.AddAdditionalCapability("useAutomationExtension", false);
var listCookie = CookieHelp.GetCookie();
if (listCookie != null)
{
// options.AddArgument("headless");
}
// string ss = @"{ ""source"": ""Object.defineProperty(navigator, 'webdriver', { get: () => undefined})""}";
// options.AddUserProfilePreference("Page.addScriptToEvaluateOnNewDocument", new ssss() { source = " Object.defineProperty(navigator, 'webdriver', { get: () => undefined }) " });
ChromeDriverService service = ChromeDriverService.CreateDefaultService(System.Environment.CurrentDirectory);
service.HideCommandPromptWindow = true;
driver = new ChromeDriver(service, options, TimeSpan.FromSeconds(120));
////session.Page.AddScriptToEvaluateOnNewDocument(new OpenQA.Selenium.DevTools.Page.AddScriptToEvaluateOnNewDocumentCommandSettings()
////{
//// Source = @"Object.defineProperty(navigator, 'webdriver', { get: () => undefined })"
////}
//// );

所以,如果网站通过js代码获取这个参数,返回值为undefined说明是正常的浏览器,返回true说明用的是Selenium模拟浏览器。
解决办法
那么对于这种情况,在爬虫开发的过程中如何防止这个参数告诉网站你在模拟浏览器呢?执行对应的js,改掉它的值。
IJavaScriptExecutor js = (IJavaScriptExecutor)driver;
string returnjs = (string)js.ExecuteScript("Object.defineProperties(navigator, {webdriver:{get:()=>undefined}});");
运行效果
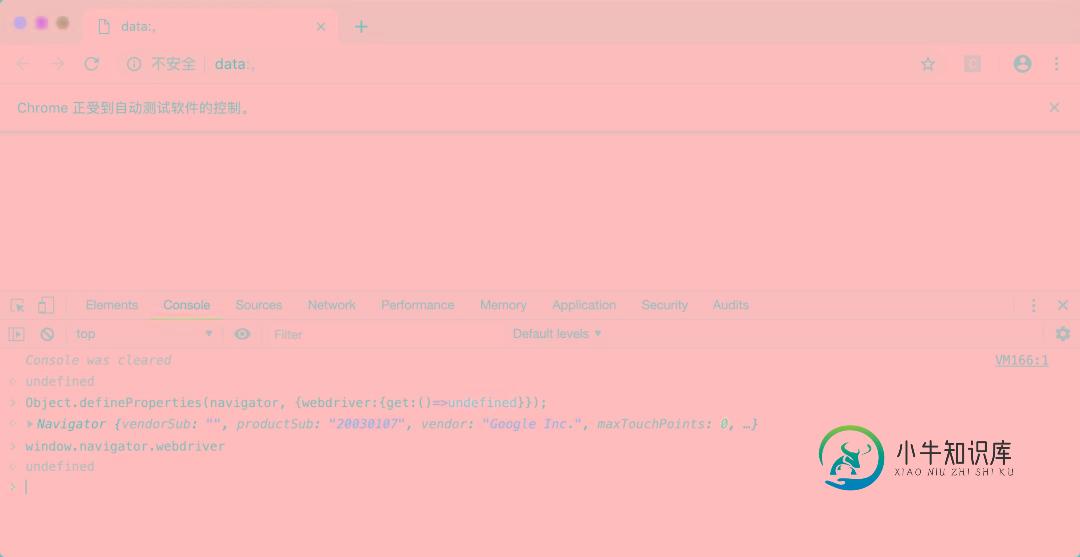
完美,达到预期效果。
以上就是c# Selenium爬取数据时防止webdriver封爬虫的方法的详细内容,更多关于c# 防止webdriver封爬虫的资料请关注小牛知识库其它相关文章!
-
本文向大家介绍python爬虫爬取网页数据并解析数据,包括了python爬虫爬取网页数据并解析数据的使用技巧和注意事项,需要的朋友参考一下 1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。 只要浏览器能够做的事情,原则上,爬虫都能够做到。 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以
-
本文向大家介绍Python爬虫爬取、解析数据操作示例,包括了Python爬虫爬取、解析数据操作示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫爬取、解析数据操作。分享给大家供大家参考,具体如下: 爬虫 当当网 http://search.dangdang.com/?key=python&act=input&page_index=1 获取书籍相关信息 面向对象思想 利用不
-
有的时候,当我们的爬虫程序完成了,并且在本地测试也没有问题,爬取了一段时间之后突然就发现报错无法抓取页面内容了。这个时候,我们很有可能是遇到了网站的反爬虫拦截。 我们知道,网站一方面想要爬虫爬取网站,比如让搜索引擎爬虫去爬取网站的内容,来增加网站的搜索排名。另一方面,由于网站的服务器资源有限,过多的非真实的用户对网站的大量访问,会增加运营成本和服务器负担。 因此,有些网站会设置一些反爬虫的措施。我
-
这一章将会介绍使用一些新的模块(optparse,spider)去完成一个爬虫的web应用。爬虫其实就是一个枚举出一个网站上面的所有链接,以帮助你创建一个网站地图的web应用程序。而使用Python则可以很快的帮助你开发出一个爬虫脚本. 你可以创建一个爬虫脚本通过href标签对请求的响应内容进行解析,并且可以在解析的同时创建一个新的请求,你还可以直接调用spider模块来实现,这样就不需要自己去写
-
本文向大家介绍详解Selenium-webdriver绕开反爬虫机制的4种方法,包括了详解Selenium-webdriver绕开反爬虫机制的4种方法的使用技巧和注意事项,需要的朋友参考一下 之前爬美团外卖后台的时候出现的问题,各种方式拖动验证码都无法成功,包括直接控制拉动,模拟人工轨迹的随机拖动都失败了,最后发现只要用chrome driver打开页面,哪怕手动登录也不可以,猜测driver肯定
-
本文向大家介绍python爬虫之爬取百度音乐的实现方法,包括了python爬虫之爬取百度音乐的实现方法的使用技巧和注意事项,需要的朋友参考一下 在上次的爬虫中,抓取的数据主要用到的是第三方的Beautifulsoup库,然后对每一个具体的数据在网页中的selecter来找到它,每一个类别便有一个select方法。对网页有过接触的都知道很多有用的数据都放在一个共同的父节点上,只是其子节点不同。在上次